Build Production ETL with Lakeflow Spark Declarative Pipelines
Designed for modern analytics and AI workloads, this reference architecture provides a robust, scalable foundation for building and automating extract, transform, load (ETL) pipelines across batch and streaming data.
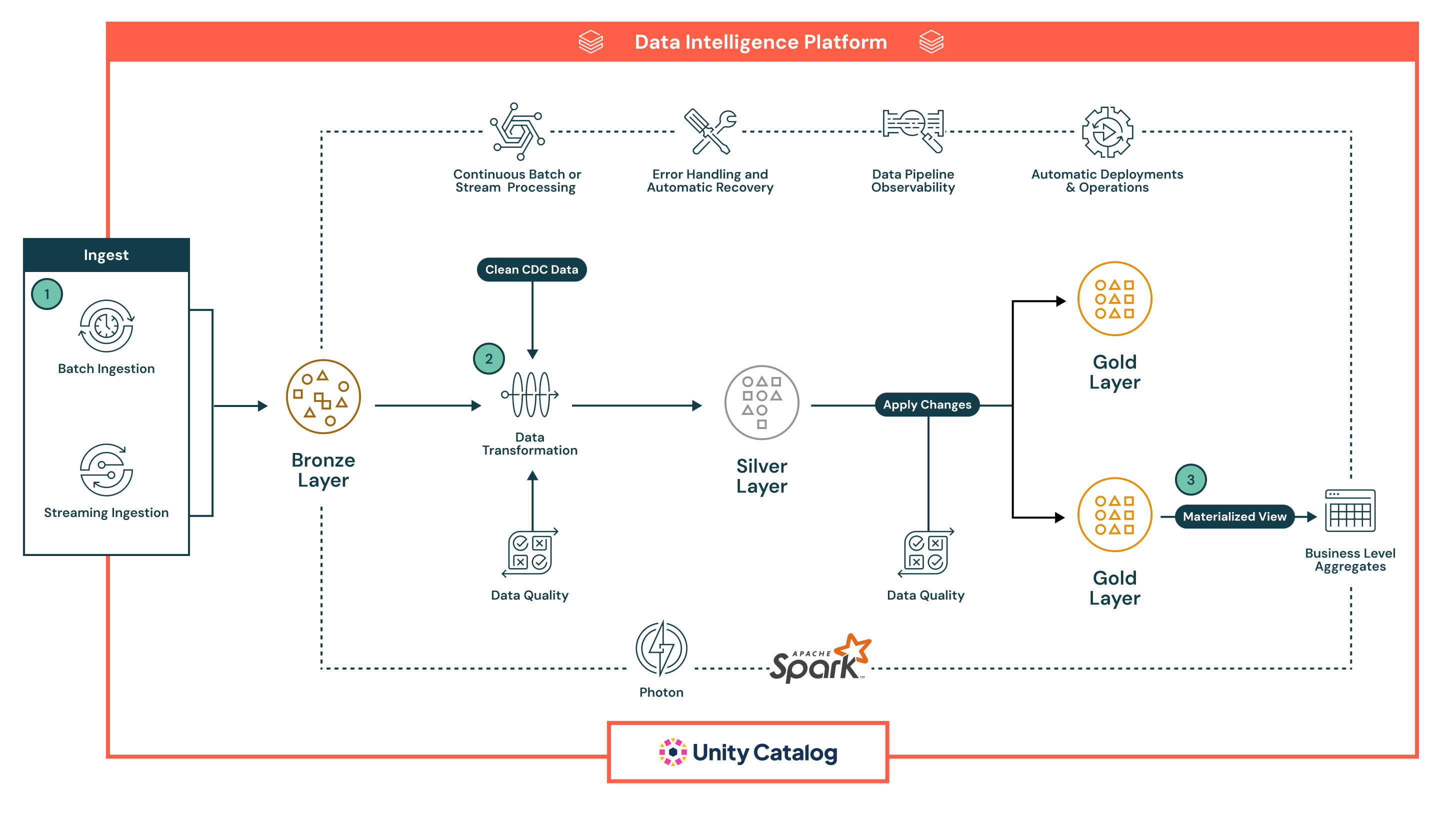
Architecture Summary
This reference architecture is well suited for organizations looking to unify batch and streaming pipelines under a single declarative framework, while ensuring data reliability, quality and governance at every stage. It leverages the Databricks Data Intelligence Platform to simplify pipeline management, enforce data expectations and deliver real-time insights with built-in observability and automation.
It supports a wide range of data engineering and analytics scenarios, from data ingestion and transformation to complex workflows with real-time quality checks, business logic and automatic recovery. Organizations adopting this architecture often seek to modernize legacy ETL, reduce operational overhead and accelerate the delivery of curated, high-quality data for business intelligence, machine learning and operational applications.
Technical Use Cases
- This architecture enables change data capture (CDC) pipelines that incrementally apply updates from source systems into the lakehouse
- Data engineers can build slowly changing dimension (SCD) patterns to manage dimensional models in analytics layers
- Streaming pipelines can be built resiliently to handle out-of-order events and late-arriving data with watermarks and checkpointing
- Data engineers can enforce schema evolution and automated quality rules using declarative constraints
- Data engineers can automate data lineage tracking and audit logging across the full pipeline with no manual instrumentation
Business Use Cases
- Retail and consumer packaged goods (CPG) companies can use this architecture to build real-time dashboards that track sales, inventory and customer behavior across multiple channels
- By integrating data from transactions, digital interactions and CRM systems, financial institutions can support fraud detection and customer segmentation
- Healthcare organizations can process and normalize medical device data and patient records for clinical insights and compliance reporting
- Manufacturers can combine IoT sensor data with historical logs to drive predictive maintenance and supply chain optimization
- Telecommunications providers can unify CRM and network telemetry data to model customer churn and usage patterns in near real time
Key Capabilities
- Declarative Pipelines development: Define pipelines using SQL or Python, abstracting away orchestration logic
- Batch and streaming support: Handle both real-time and scheduled workloads in a unified framework
- Data quality enforcement: Apply expectations directly in the pipeline to detect, block or quarantine bad data
- Observability and lineage: Built-in monitoring, alerts and visual lineage tracking improve transparency and troubleshooting
- Error handling and recovery: Automatically detect and recover from failures at any stage of the pipeline
- Governance with Unity Catalog: Enforce fine-grained access controls, audit data usage and maintain data classification across the stack
- Optimized execution: Leverage Spark and Photon under the hood for scalable, high-performance processing
- Automated operations: Pipelines can be versioned, deployed and managed through CI/CD, with support for scheduling and parameterization
Dataflow
The architecture follows a robust, multilayered medallion architecture, enhanced by Lakeflow Spark Declarative Pipelines’ built-in capabilities for automation, governance and reliability. Each phase of the pipeline is declarative, observable and optimized for both batch and streaming use cases:
Lakeflow Spark Declarative Pipelines supports both batch and streaming ingestion, providing a unified and automated way to bring data into the lakehouse.
- Batch ingestion loads data on a schedule or trigger, ideal for periodic ETL workflows. It supports full and incremental loads from cloud storage and databases. Unlike traditional tools, declarative manages orchestration, retries and schema evolution natively, reducing the need for external schedulers or scripts.
- Streaming ingestion continuously processes data from sources like Kafka and Event Hubs using Structured Streaming. Declarative Pipelines handles checkpointing, state management and autoscaling out of the box, eliminating the manual configuration typically required in streaming pipelines.
All data lands first in the Bronze layer in raw form, enabling full lineage, traceability and safe reprocessing. The pipelines’ declarative approach, built-in quality checks and automatic infrastructure handling significantly reduce operational complexity and make it easier to build resilient, production-grade pipelines — something most legacy ETL tools struggle to deliver natively.
- After ingestion, data can be processed in the Silver layer, where it is cleaned, joined and enriched to prepare for downstream consumption.
- Pipelines are defined using declarative SQL or Python, making transformations easy to read, maintain and version. Transformations are executed using Apache Spark™ with Photon, providing scalable and high-performance processing.
- Data quality checks are applied inline using expectations, a native feature of Declarative Pipelines that allows teams to enforce validation rules (e.g., null checks, data types, range limits). Invalid data can be configured to either drop bad records, quarantine them or fail the pipeline — ensuring that downstream systems only receive trusted data.
- The pipeline automatically handles job dependency tracking, task retries and error isolation, reducing operational overhead. This ensures that data processed in the Silver layer is accurate, consistent and production-ready — while maintaining operational simplicity.
- In the Gold layer, the pipeline generates business-level aggregates and curated datasets ready for consumption.
- These outputs are optimized for use in BI dashboards, machine learning features and operational systems
- Declarative Pipelines supports temporal tables and SCD logic, enabling advanced use cases like historical tracking and audit reporting
- Throughout all layers, Declarative Pipelines provides rich observability and pipeline lineage.
- The UI displays data flow graphs, operational metrics and quality dashboards to support rapid troubleshooting and compliance reporting
- With Unity Catalog integration, every table, column and transformation is governed through centralized access control, audit logging and data classification
- Pipelines are production-ready by design.
- Teams can deploy Declarative Pipelines using version-controlled definitions, schedule them via Lakeflow Jobs and manage them through CI/CD tools like GitHub Actions or Azure DevOps
- This automation replaces fragile scripting and complex orchestration setups, helping data teams focus on business logic rather than infrastructure
Recommended

On-Demand Video

On-Demand Video
Product Tour

Industry Architecture
