Reference Architecture for a Security Lakehouse
This architecture demonstrates how to centralize security data and operationalize detection, response and reporting with the Databricks lakehouse ecosystem.
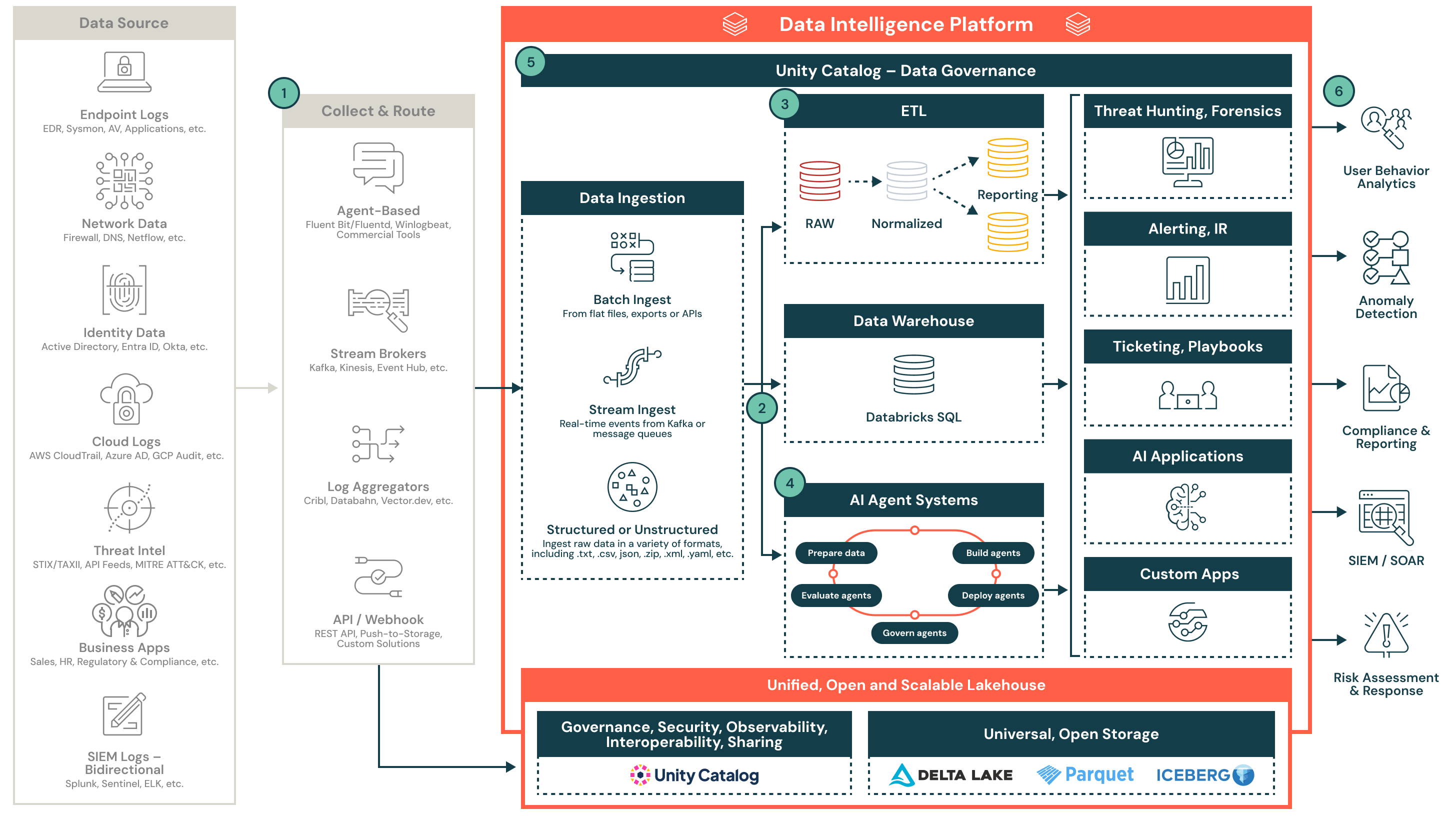
Operationalizing security telemetry at scale with the Databricks lakehouse
This reference architecture demonstrates how security teams can collect, normalize and operationalize diverse telemetry at scale using the Databricks lakehouse. It supports real-time analytics, detection engineering, compliance reporting and integration with downstream SOC tooling.
Architecture overview
Security telemetry is complex, high-volume and originates from many systems. Legacy architectures often struggle with cost, retention and cross-source correlation. The Databricks security lakehouse helps security teams centralize and operationalize this data by using open formats, governed pipelines and a flexible compute engine.
This architecture outlines a modular, cloud-native design for ingesting structured and unstructured security data from endpoints, identity systems, cloud providers, threat feeds, SIEMs and business applications. Once ingested and normalized, this data powers downstream use cases, including threat detection, triage, AI-driven investigation and reporting.
1. Collect and route
Security data is collected from multiple sources, including endpoints, cloud platforms, identity systems and threat feeds. Data is routed through agent-based collectors, stream brokers, log aggregators or direct APIs. These tools support both structured and unstructured formats and can operate in real time or batch.
Examples include:
- Fluentd, Vector or commercial log shippers
- Kafka, Event Hub or Kinesis
- Cribl, Databahn or webhook-based pipelines
2. Ingest and land
Data enters the lakehouse via structured batch ingestion or real-time streaming. Ingested data is written to Delta Lake Bronze tables to preserve fidelity and traceability. Unity Catalog ensures data is governed and discoverable from the beginning of the pipeline.
Key features include:
- Support for flat files, JSON, CSV and nested formats
- Stream ingestion from Kafka or other brokers
- Governance and discoverability through Unity Catalog
3. Normalize and transform
Raw data is parsed, flattened and enriched into structured formats for analysis and detection. This stage uses medallion architecture (Bronze, Silver, Gold) to create reusable, queryable tables that fuel detection engineering and reporting.
Normalization tasks include:
- Schema alignment (e.g., OCSF or custom models)
- Enrichment with metadata or threat intel
- Deduplication, parsing and timestamp alignment
4. Enable AI and advanced analytics
Normalized data feeds native Databricks AI agent frameworks that support security use cases. These agents can detect anomalies, triage alerts and automate investigative workflows. The platform supports agent lifecycle management from development to production.
Capabilities include:
- Preparing data for training and inference
- Deploying and managing detection agents
- Scoring and evaluating model performance in production
5. Power security operations
The lakehouse enables core SOC functions such as threat hunting, alerting, incident response and automation. Structured outputs feed dashboards, tickets, SOAR workflows and downstream systems.
Outcomes include:
- Faster investigations and reduced alert fatigue
- Unified view of telemetry across sources
- Enhanced collaboration through notebooks and SQL
6. Deliver security outcomes
Curated insights flow to tools and teams that need them. Data products support compliance, reporting, user behavior analytics, anomaly detection and risk scoring. The SIEM becomes a downstream consumer of refined alerts and context.
Examples of downstream consumption:
- Compliance reporting dashboards
- UEBA and anomaly detection pipelines
- SIEM enrichment and SOAR playbooks
