Solution Accelerator
Better LLMs With Better Data Using Cleanlab Studio
Pre-built code, sample data and step-by-step instructions ready to go in a Databricks notebook

Improve training data to boost LLM performance
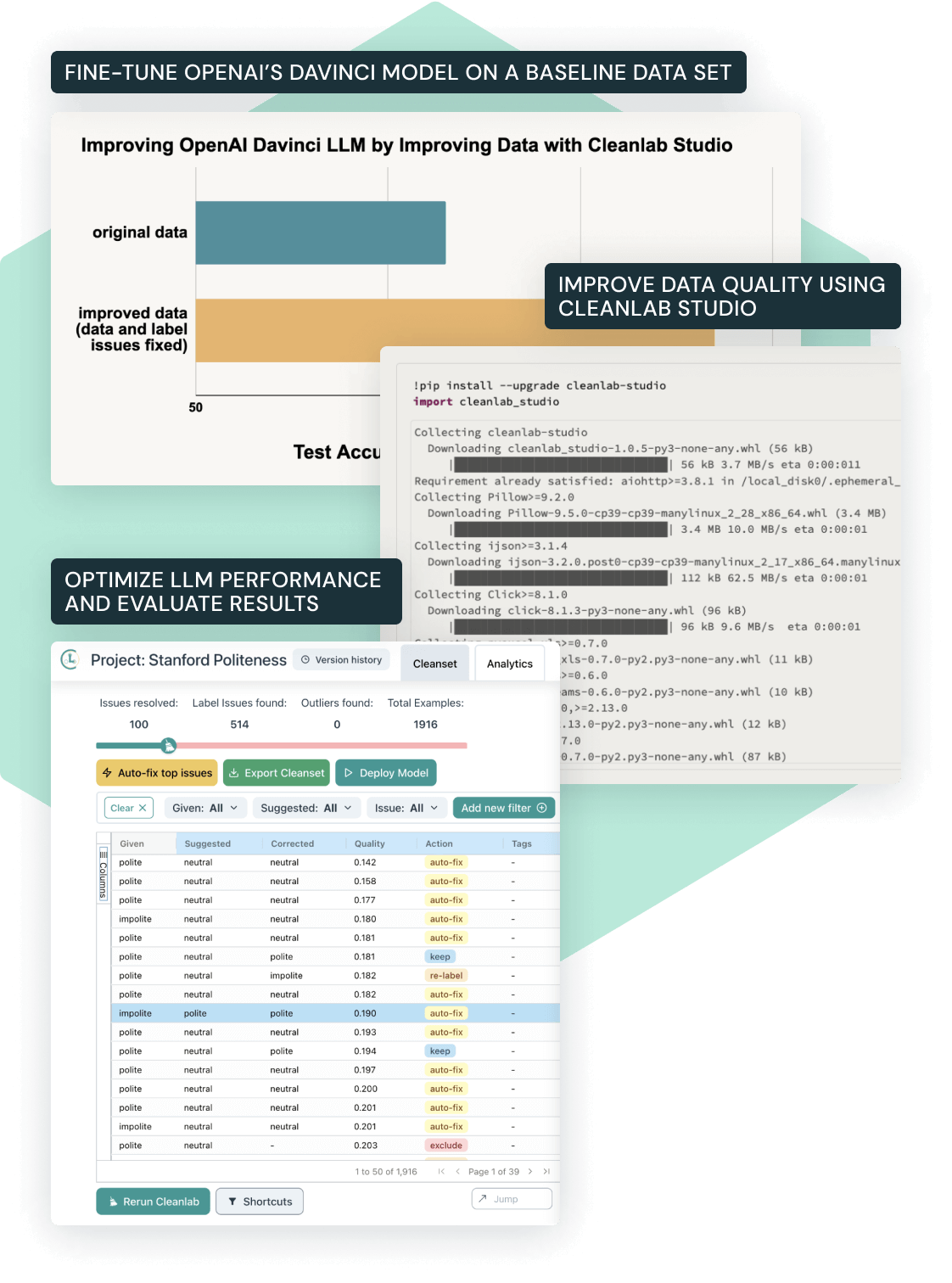
Data powers AI in the enterprise, but real-world data sets have been found to contain 7%–50% annotation errors. Unsurprisingly, erroneous data — from imperfectly labeled data to outliers — hampers the training (and evaluation) of ML models across tasks like intent recognition, entity recognition and sequence generation. Our joint Solution Accelerator with Cleanlab helps to improve training data to boost LLM performance by 37% without spending any time or resources to change the model architecture, hyperparameters or the training process.
- Fine-tune state-of-the-art LLMs using OpenAI’s APIs
- Evaluate trained LLMs to achieve high test accuracy (65%)
- Improve data quality using confident learning and DCAI without writing any code or having any ML expertise using Cleanlab Studio
Resources
Blog

Tutorial Video

Blog

Deliver AI innovation faster with Solution Accelerators for popular industry use cases. See our full library of solutions
Ready to get started?