Unified and open governance for data and AI
Eliminate silos, simplify governance and accelerate insights at scale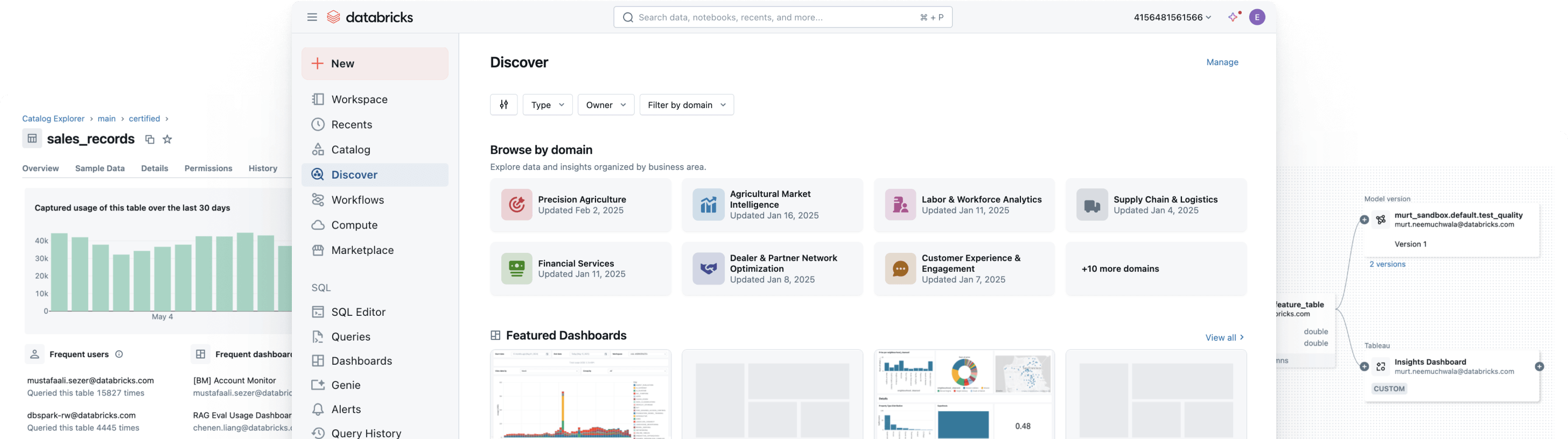
TOP TEAMS SUCCEED WITH UNIFIED AND OPEN GOVERNANCEGovern, discover, monitor and share — all in one place
Unify your data landscape, streamline compliance and drive faster, trusted insights with open, intelligent governance across data and AIUnified governance
Enforce consistent discovery, access, quality monitoring and compliance controls across structured and unstructured data, ML models and business metrics — in any cloud. With unified governance, you can reduce risk, simplify audits and accelerate data access without compromising control.
Open
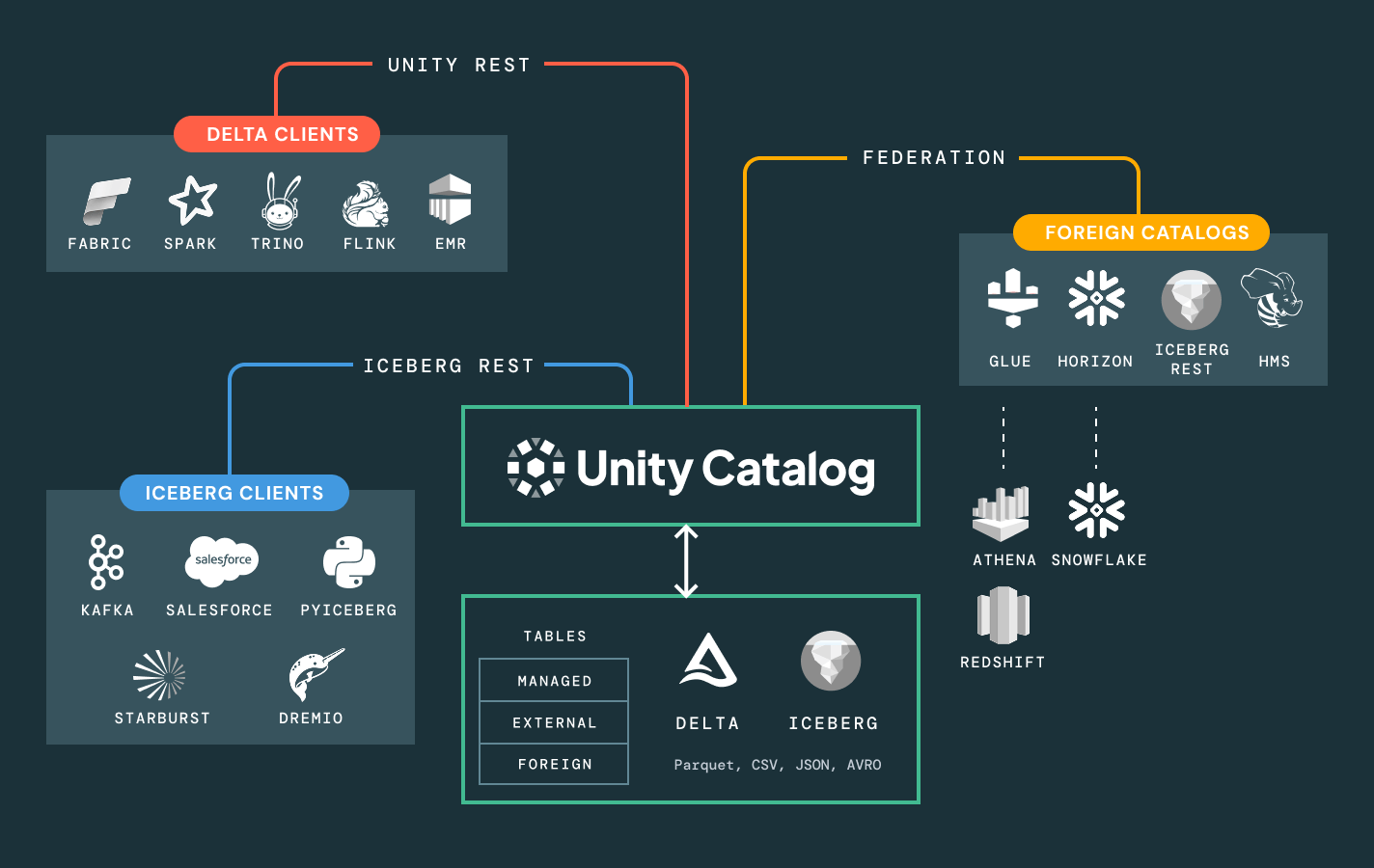
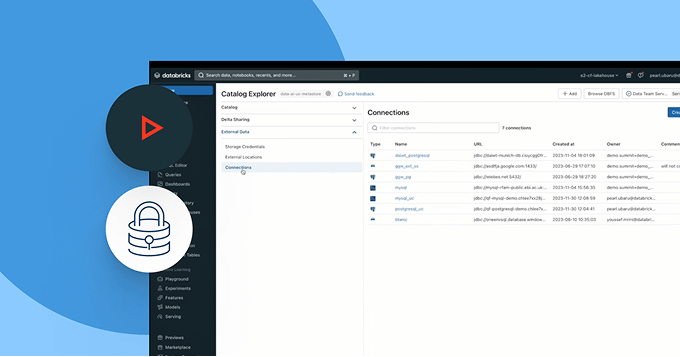
Break free from platform lock-in. Leverage any open lakehouse formats (Delta, Apache Iceberg™, Hudi, Parquet) of your choice, connect to external data sources without migration and integrate with your existing BI, AI and catalog tools through open APIs. Whether you’re sharing data internally or with partners, make collaboration secure, scalable and open standards based.
Built-in intelligence
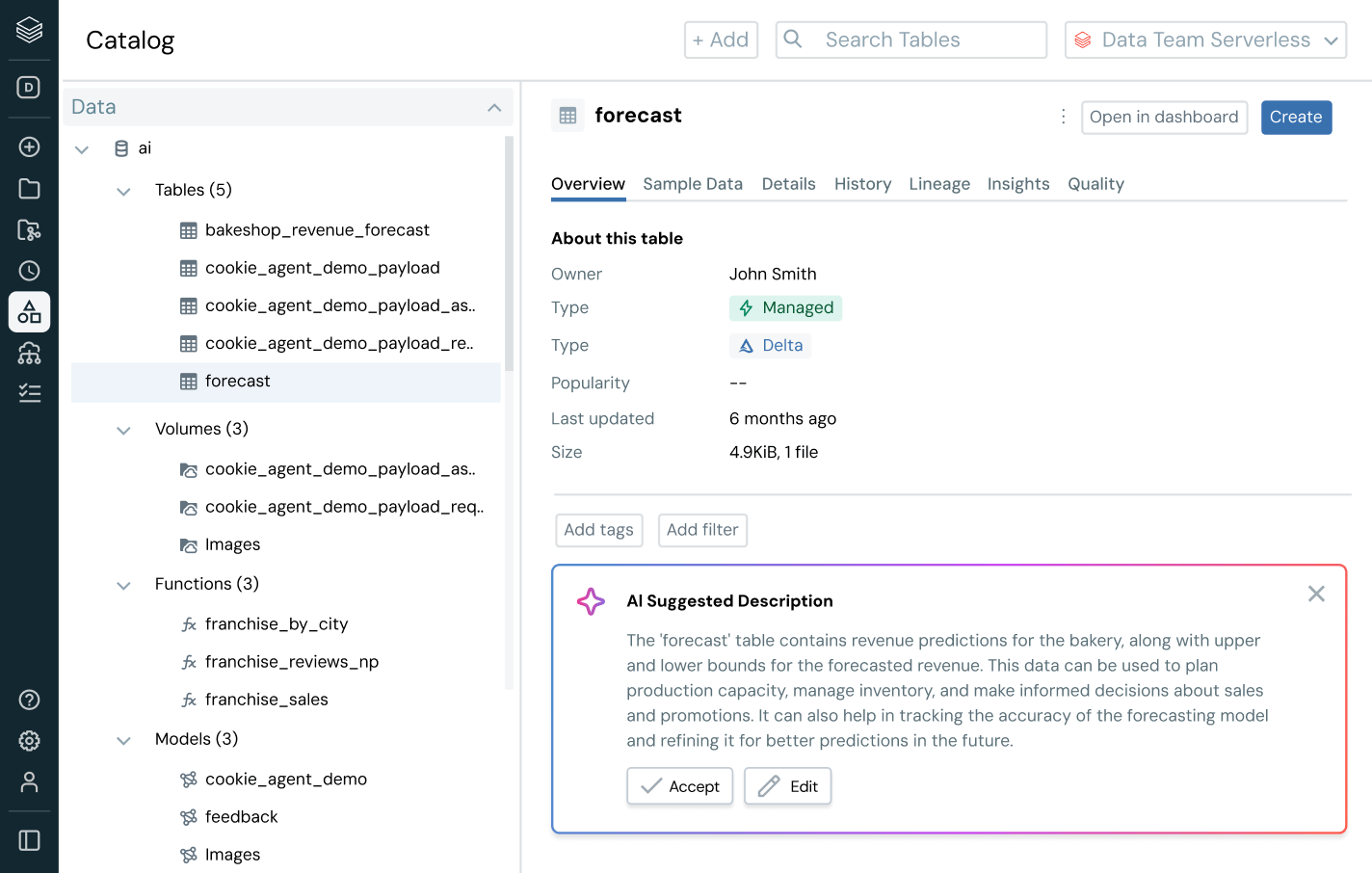
Go beyond data discovery and access management — empower users with business context. With built-in lineage, usage insights and business semantics, users can find, understand and explore data faster. AI-powered documentation, natural language search and conversational spaces help technical and business users get from data to decision — faster and with full business context.
Built-in intelligent governance
Simplify discovery, compliance and monitoring across your entire data and AI estate with intelligent governanceUnified catalog for all structured data, unstructured data, business metrics and AI models across open data formats like Delta Lake, Apache Iceberg, Hudi, Parquet and more.

More features
Unlock the full business value of data with unified governance
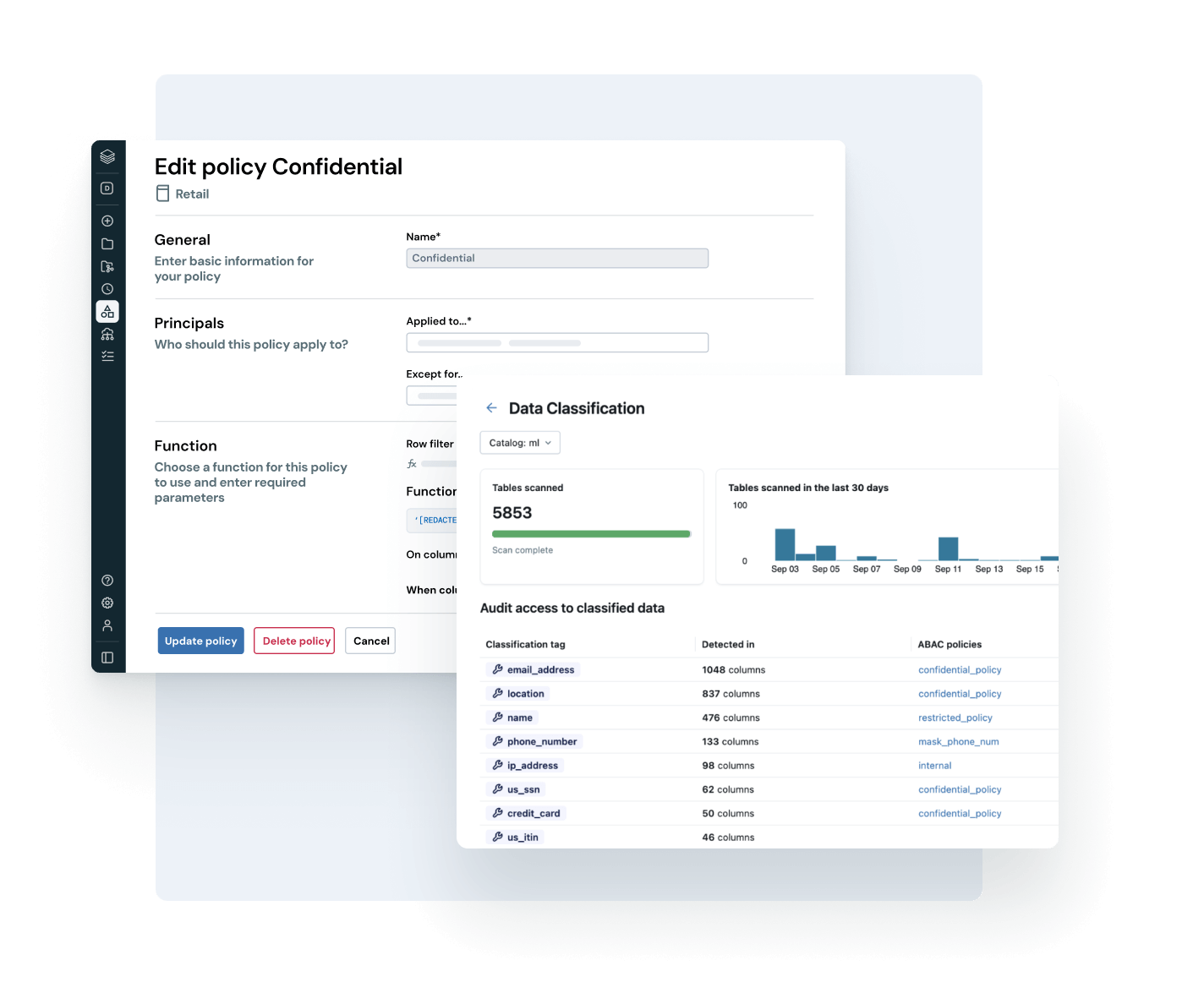
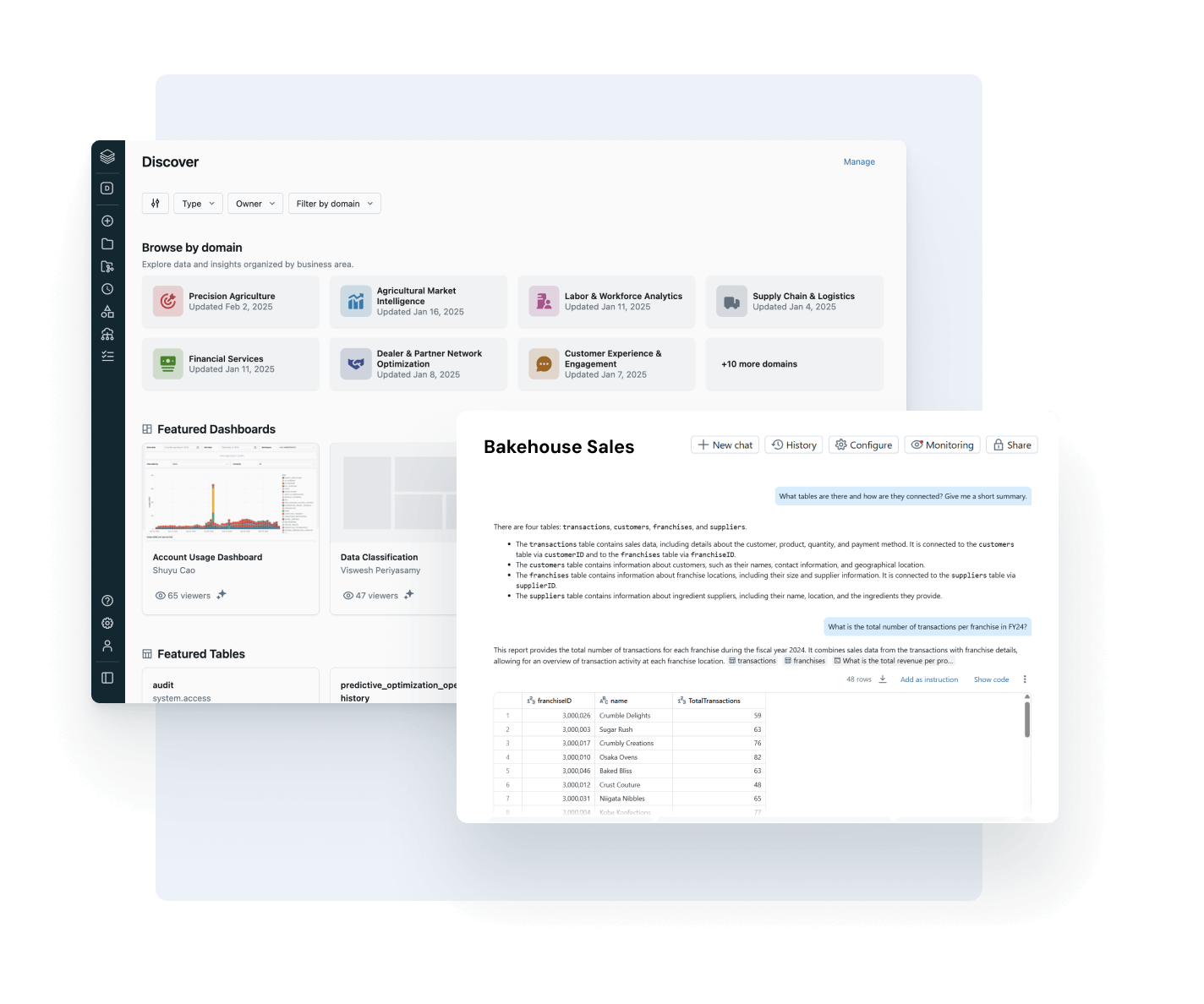
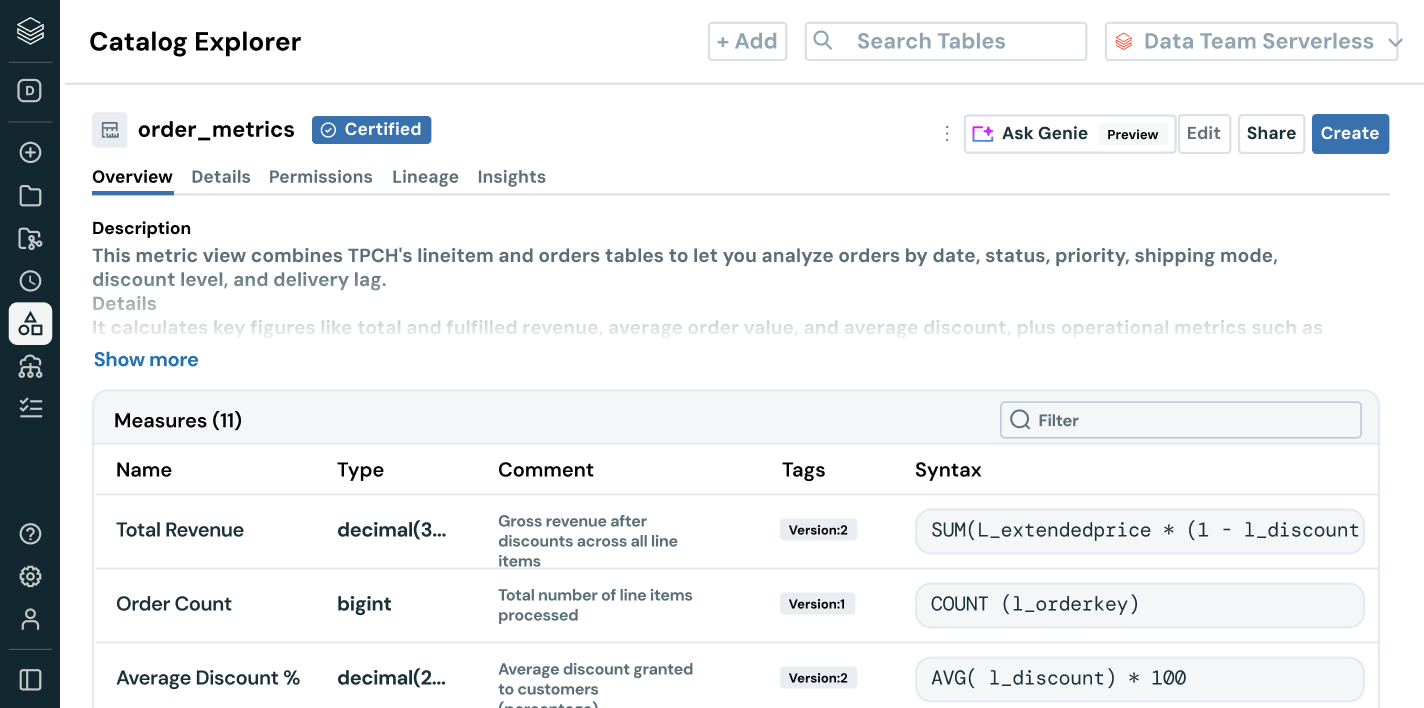
Empower every user to find, trust and use the right data
Make your most valuable data assets easy to find and understand — company-wide.
- Auto-curated discovery surfaces trusted, high-impact data assets
- AI-powered documentation, tags and usage insights add rich context
- Governed business semantics surface consistent, trusted metrics across teams and tools
- Conversational interface with AI/BI Genie helps business users explore data without needing SQL
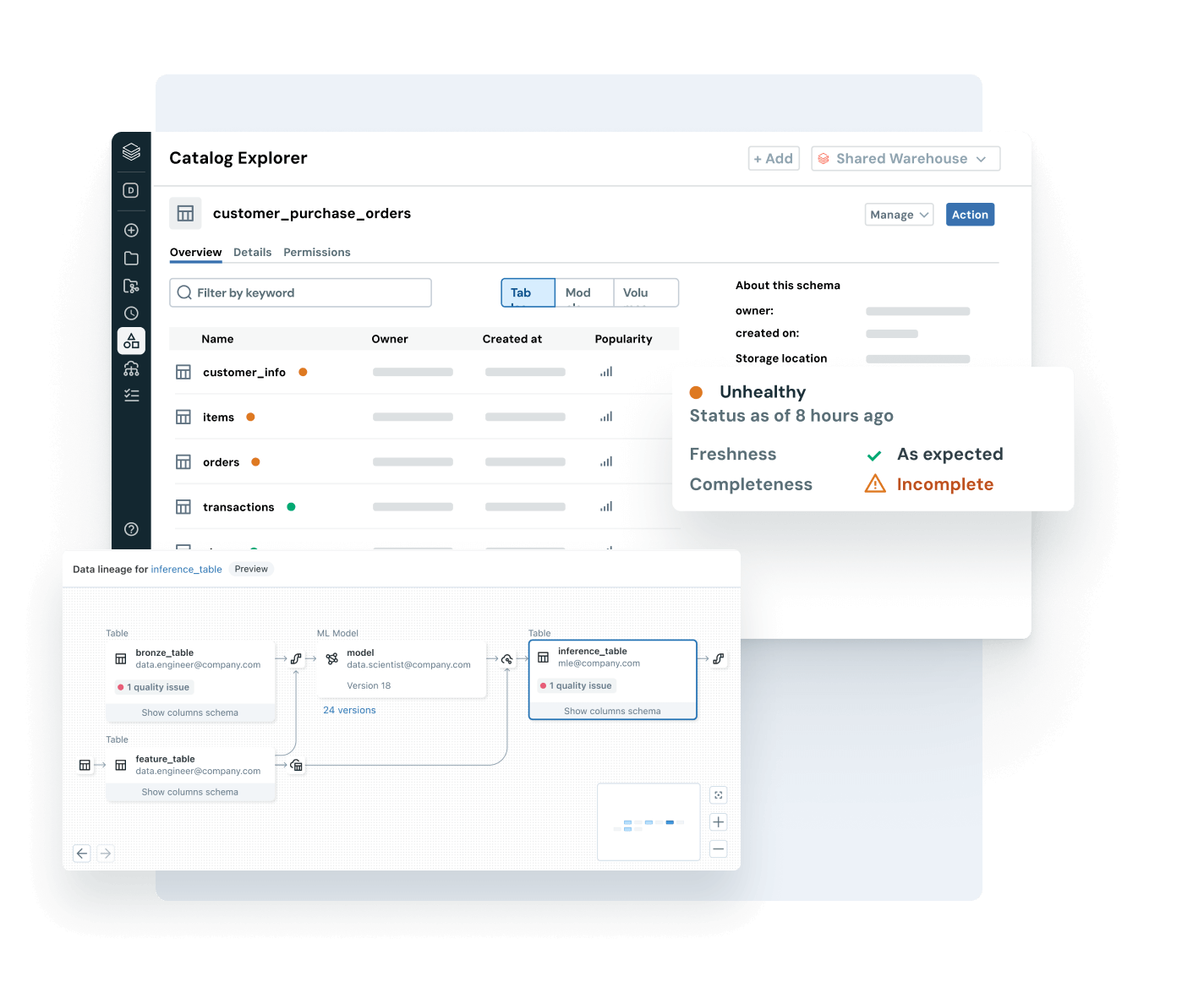
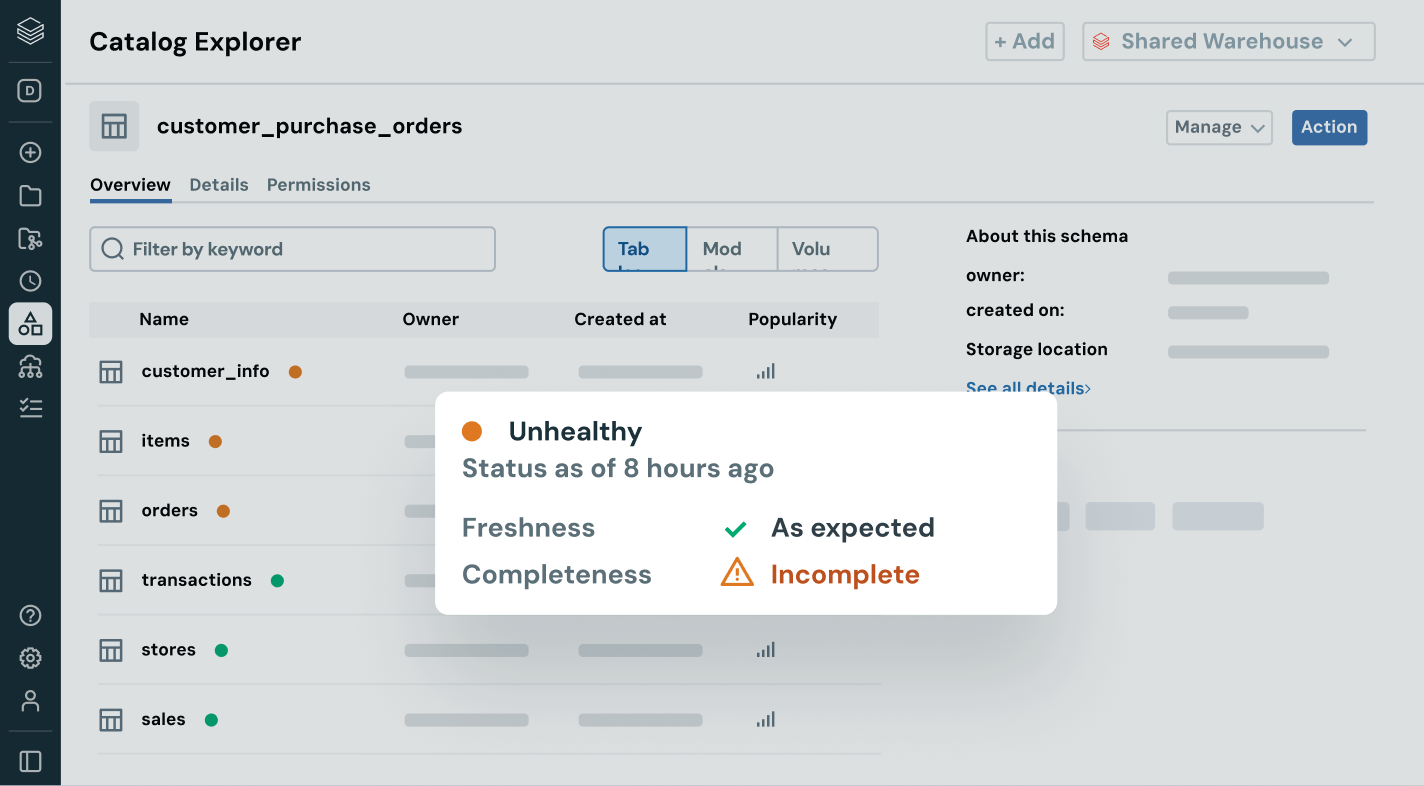
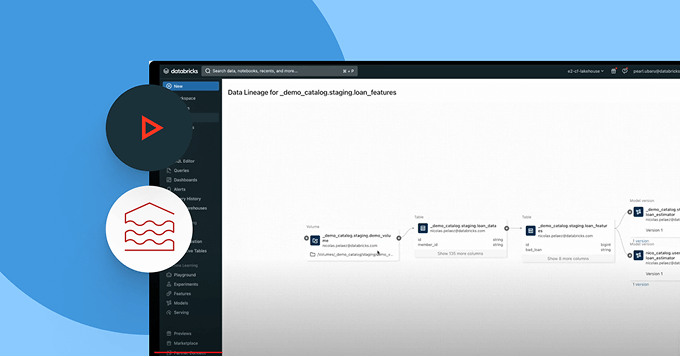
Ensure data you rely on is fresh, complete and trustworthy
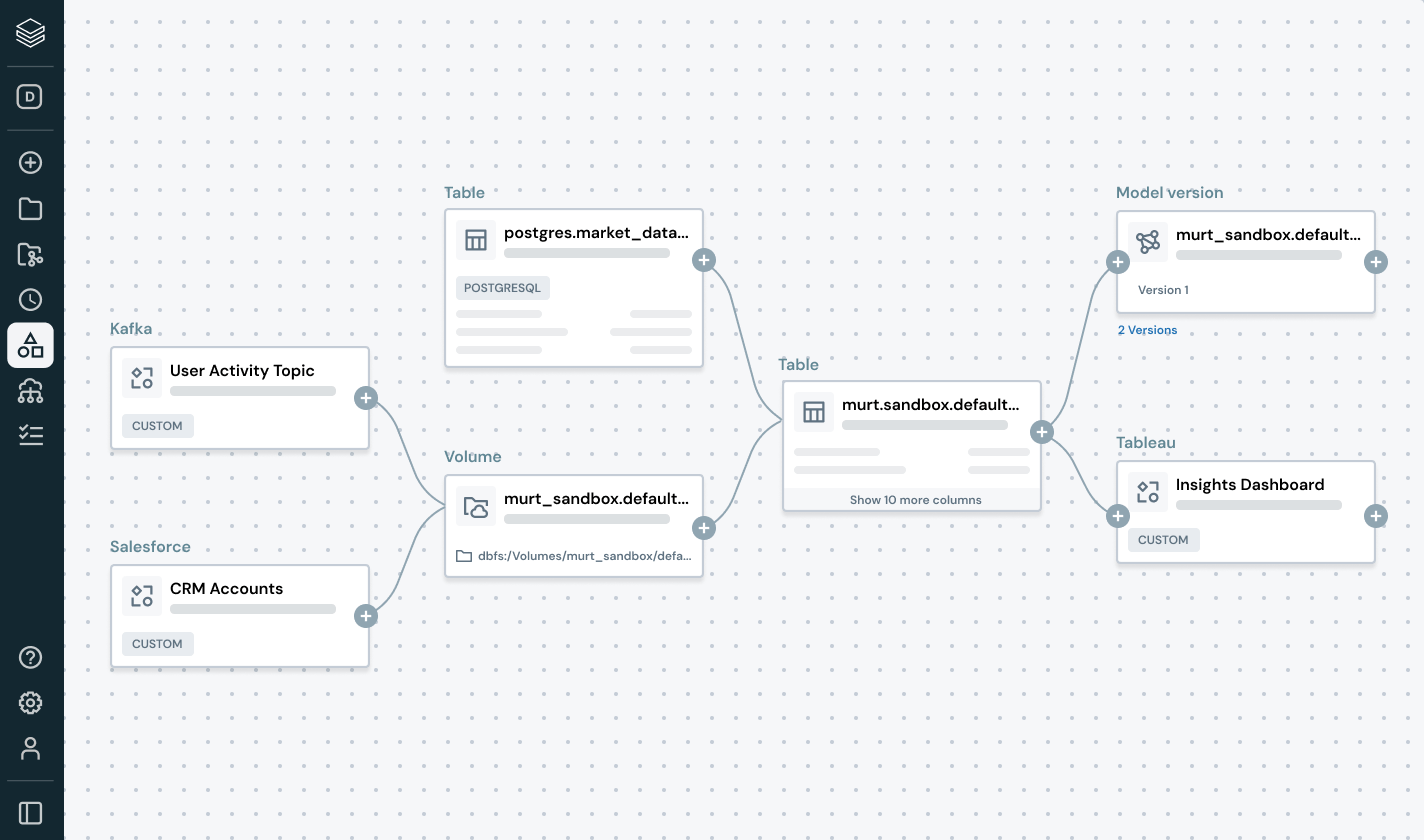
Proactively detect and resolve data issues with complete visibility into lineage and quality signals.
- Monitor data health with freshness, completeness and anomaly detection
- Trace end-to-end lineage across pipelines, models and dashboards
- Assess the downstream impact of broken data and AI pipelines
- Strengthen trust by exposing quality insights alongside each asset
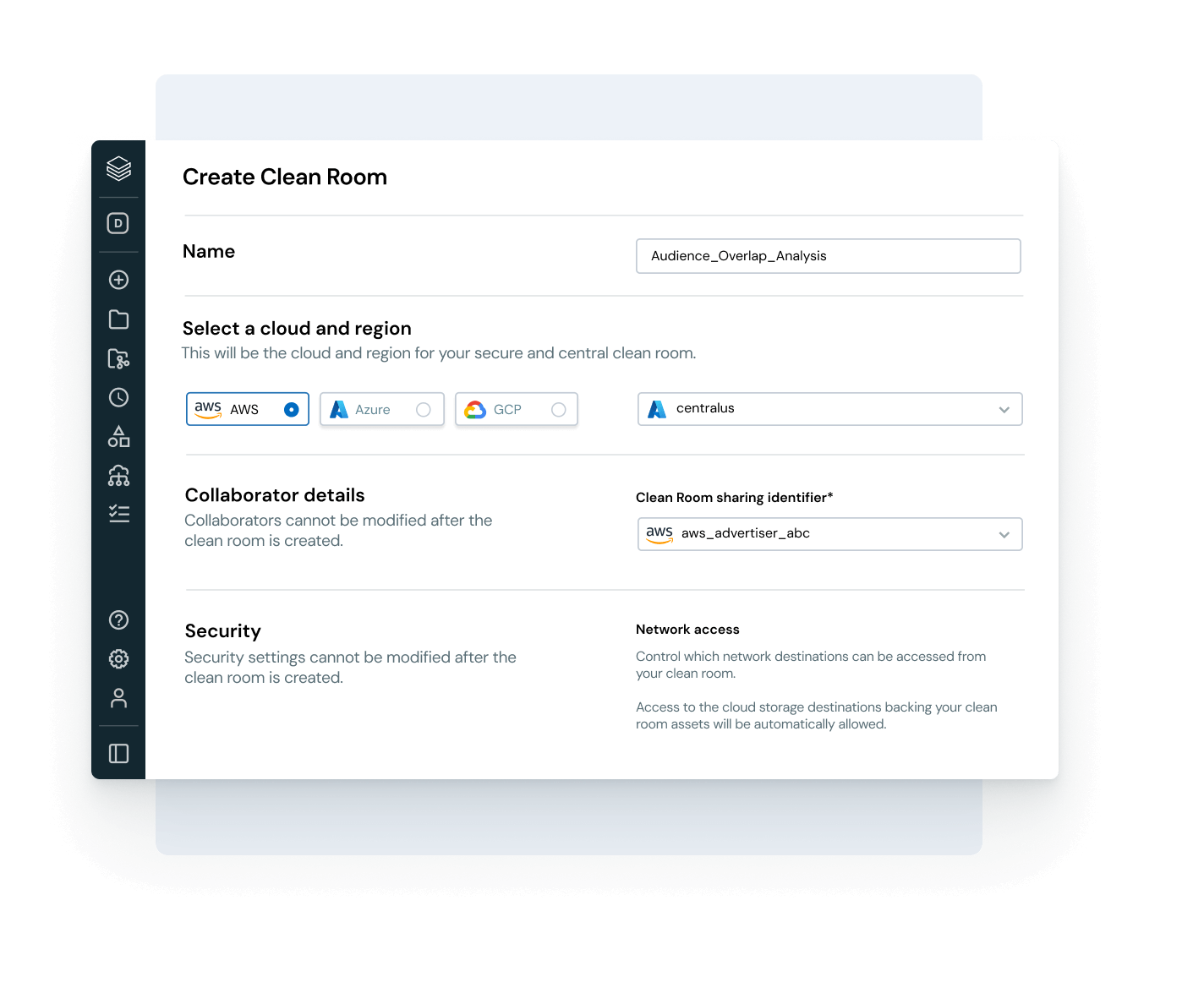
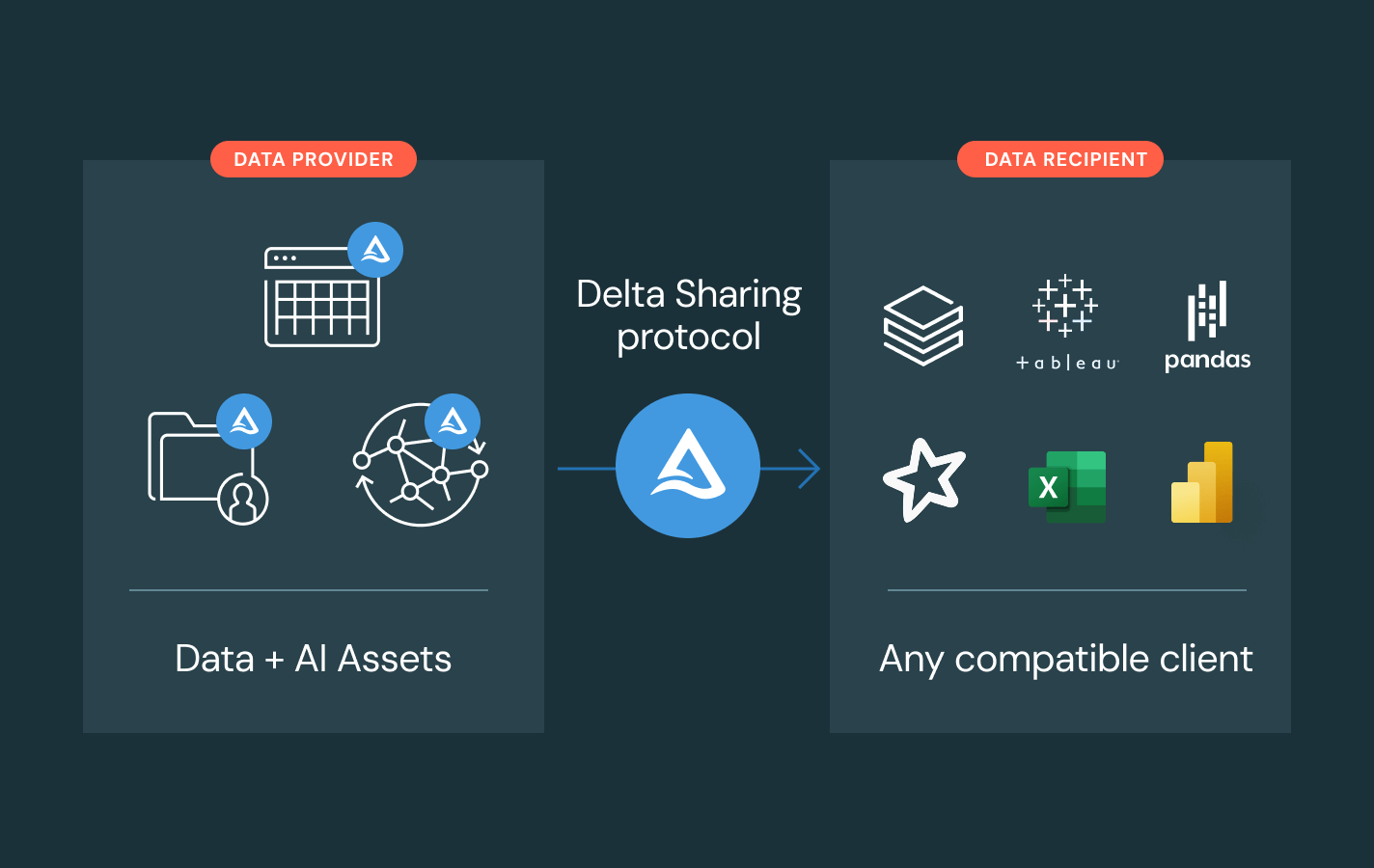
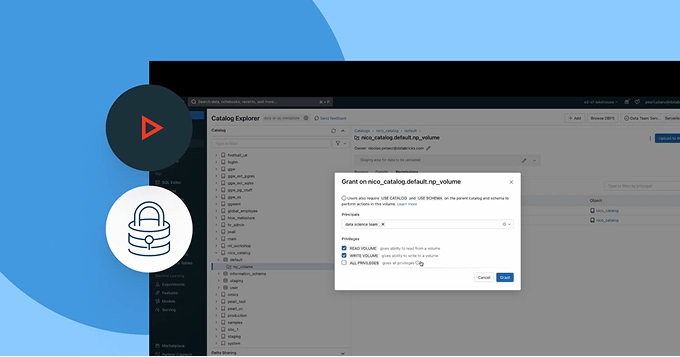
Enable safe, open collaboration across clouds and partners
Break down silos and scale data and AI sharing — with complete governance control.
- Share governed data and AI assets across teams, clouds or partners using Delta Sharing
- Use Clean Rooms for secure, privacy-preserving collaboration
- Avoid vendor lock-in with open sharing standards
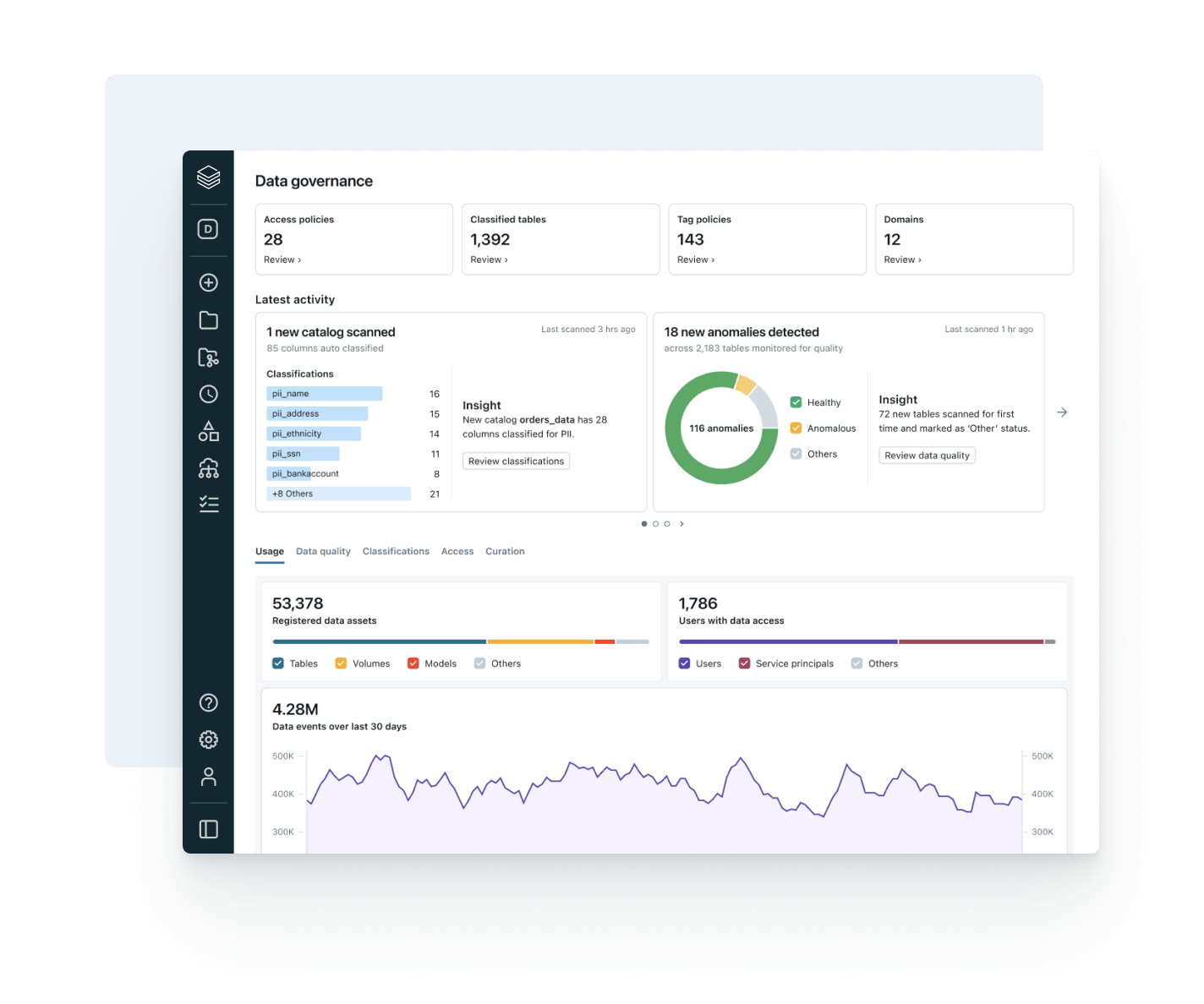
Align data usage with business value and operational cost
Use built-in observability to optimize spend, boost governance adoption and increase ROI.
- Track data consumption trends across users, teams and business units
- Link lineage to compute and storage usage to identify optimization levers
- Monitor policy adoption and data access patterns in one UI
- Enable data product owners to measure and report on data value

Discover more
Explore products that extend the power of Unity Catalog across governance, collaboration and data intelligence.
Databricks Clean Rooms
Analyze shared data from multiple parties without providing direct access to the raw data.

Databricks Marketplace
An open marketplace for data, as well as AI and analytics assets such as ML models and notebooks.

Delta Sharing
An open source approach to data and AI sharing across platforms. Share live data with centralized governance and no replication.

AI/BI Genie
A conversational experience, powered by generative AI, for business teams to explore data and self-serve insights in real time through natural language.

Databricks Assistant
Describe your task in natural language and let the Assistant generate SQL queries, explain complex code and automatically fix errors.
Databricks Data Intelligence Platform
Explore the full range of tools available on the Databricks Data Intelligence Platform to seamlessly integrate data and AI across your organization.
Take the next step




Unity Catalog FAQ
Ready to become a data + AI company?
Take the first steps in your data transformation