Apache Spark In MapReduce (SIMR)
by Ali Ghodsi and Ahir Reddy
Apache Hadoop integration has always been a key goal of Apache Spark and YARN users have long been able to run Spark on YARN. However, up to now, it has been relatively hard to run Spark on Hadoop MapReduce v1 clusters, i.e. clusters that do not have YARN installed. Typically, users would have to get permission to install Spark/Scala on some subset of the machines, a process that could be time consuming. Enter SIMR (Spark In MapReduce), which has been released in conjunction with Apache Spark 0.8.1.
SIMR allows anyone with access to a Hadoop MapReduce v1 cluster to run Spark out of the box. A user can run Spark directly on top of Hadoop MapReduce v1 without any administrative rights, and without having Spark or Scala installed on any of the nodes. The only requirements are HDFS access and MapReduce v1. SIMR is open sourced under the Apache license and was jointly developed by Databricks and UC Berkeley AMPLab.
The basic idea is that a user can download the package of SIMR (3 files) that matches their Hadoop cluster and immediately start using Spark. SIMR includes the interactive Spark shell, and allows users to use the shell backed by the computational power of the cluster. It is a simple as ./simr --shell:
Running a Spark program simply requires bundling it along with its dependencies into a jar and launching the job through SIMR. SIMR uses the following command line syntax for running jobs:
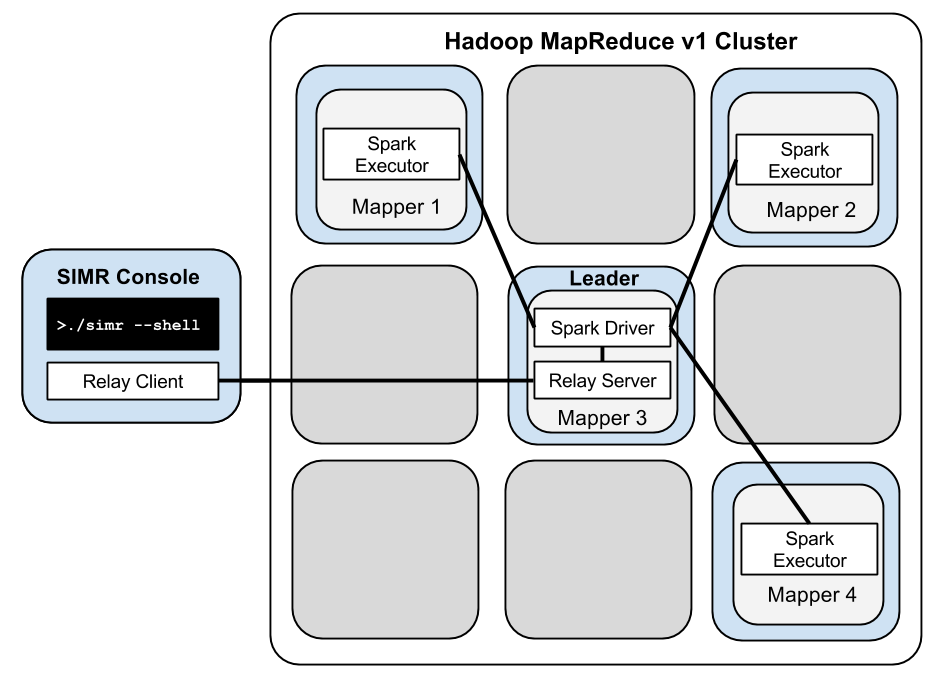
SIMR simply launches a MapReduce job with the desired number of map slots, and ensures that Spark/Scala and your job gets shipped to all those nodes. It then designates one of the mappers as the master and runs the Spark driver inside it. On the rest of the mappers it launches Spark executors that will execute tasks on behalf of the driver. Voila, your Spark job is running inside MapReduce on the cluster.
SIMR lets users interact with the driver program. For example, users can type into the Spark shell and see its output interactively. The way this works is that SIMR runs a relay server on the master mapper and a relay client on the machine that launched SIMR. Any input from the client and output from the driver are relayed back and forth between the client and the master mapper.
To make all this work, SIMR makes extensive use of HDFS. The master mapper is elected using leader election by writing to HDFS and picking the mapper that firsts gets to write to HDFS. Similarly, the executors launched inside the rest of the mappers find out the driver’s URL by reading it from a specific file from HDFS. Thus, SIMR uses MapReduce and HDFS in place of a cluster manager.
SIMR is not intended to be used in production mode, but rather to enable users to explore and use Spark before running it on a proper resource manager, such as YARN, Mesos, or Standalone Mode. MapReduce 2 (YARN) users can of course use the existing Spark on YARN solution, or explore other Spark deployment options.
We hope SIMR will enable users to try out Spark without any heavy operational burden. Towards this goal, we have pre-built several SIMR binaries for different versions of Hadoop. Please go ahead and try it and let us know if you have any feedback.
SIMR resources:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.