Sharethrough Uses Apache Spark Streaming to Optimize Bidding in Real Time
by Russell Cardullo and Michael Ruggiero
At Sharethrough, which offers an advertising exchange for delivering in-feed ads, we’ve been running on CDH for the past three years (after migrating from Amazon EMR), primarily for ETL. With the launch of our exchange platform in early 2013 and our desire to optimize content distribution in real time, our needs changed, yet CDH remains an important part of our infrastructure.
In mid-2013, we began to examine stream-based approaches to accessing click-stream data from our pipeline. We asked ourselves: Rather than “warm up our cold path” by running those larger batches more frequently, can we give our developers a programmatic model and framework optimized for incremental, small batch processing, yet continue to rely on the Cloudera platform? Ideally, our engineering team focuses on the data itself, rather than worrying about details like consistency of state across the pipeline or fault recovery.
Spark (and Spark Streaming)
Apache Spark is a fast and general framework for large-scale data processing, with a programming model that supports building applications that would be more complex or less feasible using conventional MapReduce. (Spark ships inside Cloudera Enterprise 5, and is already supported for use with CDH 4.4 and later.) With an in-memory persistent storage abstraction, Spark supports complete MapReduce functionality without the long execution times required by things like data replication, disk I/O, and serialization.
Because Spark Streaming shares the same API as Spark’s batch and interactive modes, we now use Spark Streaming to aggregate business-critical data in real time. A consistent API means that we can develop and test locally in the less complex batch mode and have that job work seamlessly in production streaming. For example, we can now optimize bidding in real time, using the entire dataset for that campaign without waiting for our less frequently run ETL flows to complete. We are also able to perform real-time experiments and measure results as they come in.
Before and After
Our batch-processing system looks like this:
- Apache Flume writes out files based on optimal HDFS block size (64MB) to hourly buckets.
- MapReduce (Scalding) jobs are scheduled N times per day.
- Apache Sqoop moves results into the data warehouse.
- Latency is ~1 hour behind, plus Hadoop processing time.
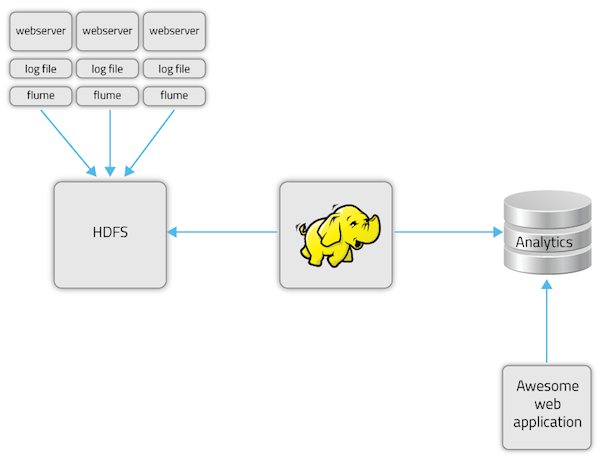
Sharethrough’s former batch-processing dataflow
For our particular use case, this batch-processing workflow wouldn’t provide access to performance data while the results of those calculations would still be valuable. For example, knowing that a client’s optimized content performance is 4.2 percent an hour after their daily budget is spent, means our advertisers aren’t getting their money’s worth, and our publishers aren’t seeing the fill they need. Even when the batch jobs take minutes, a spike in traffic could slow down a given batch job, causing it to “bump into” newly launched jobs.
For these use cases, a streaming dataflow is the viable solution:
- Flume writes out clickstream data to HDFS.
- Spark reads from HDFS at batch sizes of five seconds.
- Output to a key-value store, updating our predictive modeling.
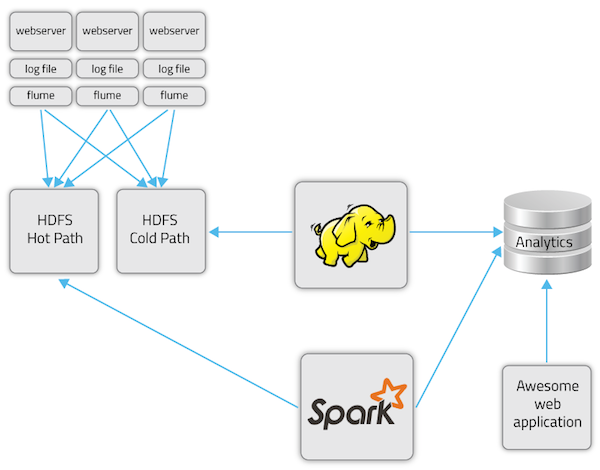
Sharethrough’s new Spark Streaming-based dataflow
In this new model, our latency is only Spark processing time and the time it takes Flume to transmit files to HDFS; in practice, this works out to be about five seconds.
On the Journey
When we began using Spark Streaming, we shipped quickly with minimal fuss. To get the most out of our new streaming jobs, we quickly adjusted to the Spark programming model.
Here are some things we discovered along the way:
- The profile of a 24 x 7 streaming app is different than an hourly batch job — you may need finer-grained alerting and more patience with repeated errors. And with a streaming application, good exception handling is your friend. (Be prepared to answer questions like: “What if the Spark receiver is unavailable? Should the application retry? Should it forget data that was lost? Should it alert you?”)
- Take time to validate output against the input. A stateful job that, for example, keeps a count of clicks, may return results you didn’t expect in testing.
- Confirm that supporting objects are being serialized. The Scala DSL makes it easy to close over a non-serializable variable or reference. In our case, a GeoCoder object was not getting serialized and our app became very slow; it had to return to the driver program for the original, non-distributed object.
- The output of your Spark Streaming job is only as reliable as the queue that feeds Spark. If the producing queue drops, say, 1 percent of messages, you may need a periodic reconciliation strategy (such as merging your lossy “hot path” with “cold path” persistent data). For these kinds of merges, the monoid abstraction can be helpful when you need certainty that associative calculations (counts, for example) are accurate and reliable. For more on this, see merge-able stores like Twitter’s Storehaus or Oscar Boykin’s “Algebra for Analytics“.
Conclusion
Sharethrough Engineering intends to do a lot more with Spark Streaming. Our engineers can interactively craft an application, test it in batch, move it into streaming and it just works. We’d encourage others interested in unlocking real-time processing to look at Spark Streaming. Because of the concise Spark API, engineers comfortable with MapReduce can build streaming applications today without having to learn a completely new programming model.
Spark Streaming equips your organization with the kind of insights only available from up-to-the-minute data, either in the form of machine-learning algorithms or real-time dashboards: It’s up to you!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.