Application Spotlight: Arimo
In early 2012, a group of engineers with background in distributed systems and machine learning came together to form Arimo. We saw a major unsolved problem in the nascent Hadoop ecosystem: it was largely a storage play. Data was sitting passively on HDFS, with very little value being extracted. To be sure, there was MapReduce, Hive, Pig, etc., but value is a strong function of (a) speed of computation, (b) sophistication of logic, and (c) ease of use. While Hadoop ecosystem was being developed well at the substrate, there was enormous opportunities above it left uncaptured.
On speed: we had seen data move at-scale and at enormously faster rates in systems like Dremel and PowerDrill at Google. It enabled interactive behavior simply not available to Hadoop users. Without doubt, we knew that interactive speed was necessary, and that in-memory computing was key to the solution. As Cloudera’s Mike Olson has quipped, “We’re lucky to live in an age where there’s a Google. They live about 5 years in the future, and occasionally send messages back to the rest of us.” Google does indeed “live in the future”, in terms of the demands of scale and the value it is extracting from data.
On sophistication: for Arimo, the essential difference between “small” and “big” data is whether data is big enough to learn from. For some questions, such as “Does it hurt to hit my head against a brick wall?”, 100 samples suffice. To classify large images, a million samples aren’t enough. We knew this was the second missing key in Big Data: aggregates and descriptives were necessary but insufficient. The Big-Data world needed the sophistication of machine learning. Big Data needed Big Compute. “Predictive” isn’t just another adjective in a long string of X-analytics; it is the quantum change, separating the value of big from small.
Thus Arimo was born as a “Big Data/Machine Learning” company. Our exact product features would be driven by customer conversations, but the core thesis was clear. We wanted to bring “Data Intelligence for All”, specifically with the speed and sophistication discussed above.
If in-memory compute and machine-learning logic were the key to unlocking the value of Big Data, why hadn’t this been solved already in 2012? Because cost/benefit trade-offs matter, in any technology transition. In the chart below, the crossover points happened at different times for different endeavors; it hit critical mass on Wall Street about 2000-2005, at Google c. 2006-2010, and we project for the enterprise world at-large: about now (2013-2015).
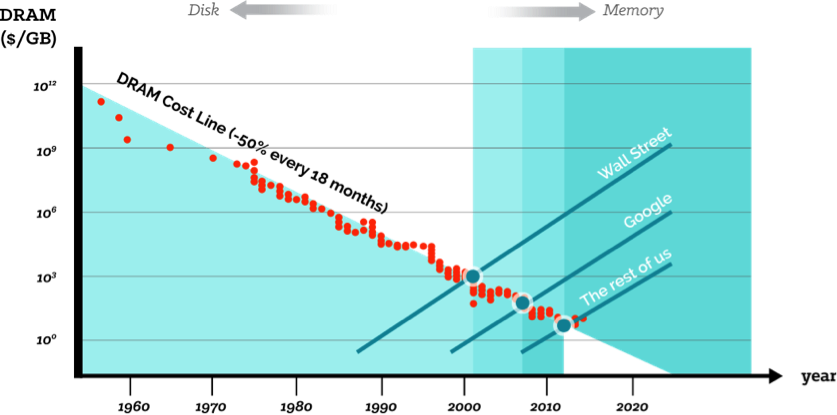
Fig 1. Cross-over points for transitions to in-memory computing
If this isn’t clearly happening for your organization or industry yet, relax. It will, soon. Because as the latency and bandwidth trend charts below show, the future increasingly favors RAM.
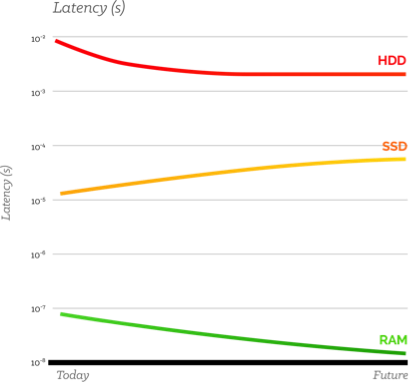
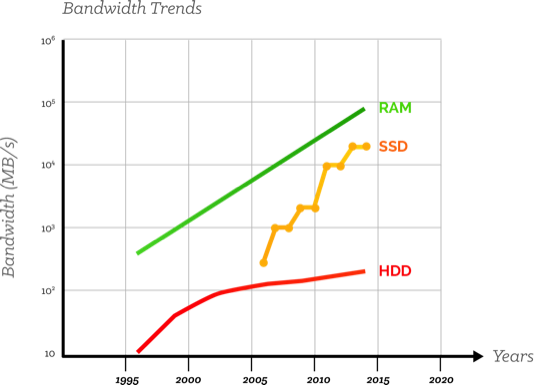
Fig 2. The future increasingly favors a shift to RAM
As the Arimo team set out to build this big-compute analytic stack on Hadoop, we wanted our solution to reach all the way to the business users, while also exposing convenient APIs for data engineers and scientists. This required a combination of a great collaborative user interface, solid data-mining and machine-learning logic, backed by a powerful big-compute engine. We did a survey of the in-memory landscape, and found a small number of teams also working in the same direction. But virtually all were either too incremental or too aggressive. Some were developing work-arounds such as caching data between MR iterations, or maintaining a low-level memory cache with no persistent, high-level data structures. Others promoted yet-slow & expensive “virtualized memory” architectures, still too early for prime time.
Then we came across Spark and the Berkeley AMPLab team. Immediately, we knew they had identified the right problem statements, and made the right architectural decisions for the times. Here are some key design choices correctly made for widespread adoption c. 2012:
- Data model: Spark was the only architecture that supported the concept of a high-level, persistent distributed in-memory dataset. All “in-memory” systems are not equivalent. Spark’s RDDs exist independently of any given compute step, allowing for not only speedy iterative algorithms, with high-level data sets readily available to each iteration without delay. Equally importantly, they made long-running interactive memory-speed applications possible.
- Resiliency by recomputation: with replication being the other option, Spark made the timely choice to prefer recomputation. Memory had gotten cheaper, but not yet cheap enough for replication to be the order of the day, as it is with HDFS disks.
- General DAG support: while it was possible to build dedicated SQL query engines to overcome Hadoop MapReduce’s limitations (and others did choose this path), Spark’s general DAG model meant we could build arbitrary algorithms and applications on it.
We were ecstatic. Spark represented years of R&D we didn’t have to spend building an engine before building sophisticated, user-facing applications. When we made the decision to support the AMPLab Spark effort, there were only 1 or 2 others that had made similar commitments. We were seriously betting the company on Spark.
But thanks to Spark, we were able to move ahead quietly and quickly on Arimo pInsights and pAnalytics, iterating on customer feedback while passing our inputs and market data along to the Spark team. We promoted Spark’s goodness in every relevant conversation. By late summer 2013, Databricks was about to be born, further increasing our confidence on the Spark-on-Hadoop ecosystem. There was now going to be an official, commercial entity with an existence predicated on developing the growth of the ecosystem and maintaining its health. And the team at Databricks is doing an excellent job at that stewardship.
Today, Arimo is one of the first applications to be Certified on Spark. We’re seeing remarkable enterprise adoption speeds for Arimo-on-Spark. The most sophisticated customers tend to be companies that have already deployed Hadoop, who are all too familiar with the failed promises of Big Data. We see immediate excitement in customers the moment they see the Arimo solution: a user-facing analytics application that is interactive, easy-to-use, supports both basic analytics and machine learning, and is actually running in seconds of real time over large Hadoop datasets. Finally, users are truly able to extract data intelligence from data storage. Value creation is no longer just about Big Data. It’s about Big Compute, and Spark has delivered that capability for us.
Spark has made it as a top-level Apache project, going from incubation to graduation in record time. It is also one of Apache’s most active projects with hundreds of contributors. This is because of its superior architecture and timeliness of engineering choices, as discussed above. With that plus appropriate care and feeding, Apache Spark will have a bright future even as it evolves and adapts to changing technology and business drivers.
Christopher Nguyen is co-founder and CEO of Arimo. He is a former engineering director of Google Apps, a Stanford PhD who co-founded two enterprise startups with successful exits, and a professor and co-founder of the Computer Engineering program at HKUST. He graduated from U.C. Berkeley summa cum laude. Christopher has extensive experience building technology companies that solve enterprise business challenges. Come hear his talk on Distributed DataFrames (DDF) on Spark: Simplifying Big Data for the Rest of Us at the Spark Summit 2014.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.