Application Spotlight: Qlik
by Bill Kehoe
The Power of Qlik
Qlik provides software and services that help make understanding data a natural part of how people make decisions. Our product, QlikView, is the leading Business Discovery platform that incorporates a unique, associative experience that empowers business users to follow their own path to formulate and answer questions that lead to better decisions. Traditional, query-based BI tools force users thru pre-defined navigation paths which limit the kinds of questions that can be answered and require costly and time consuming revisions to address evolving business needs. In contrast, when a user selects data items using QlikView, all the fields and charts are immediately updated to reflect the relationships between the selected items and the other data items in the business model.
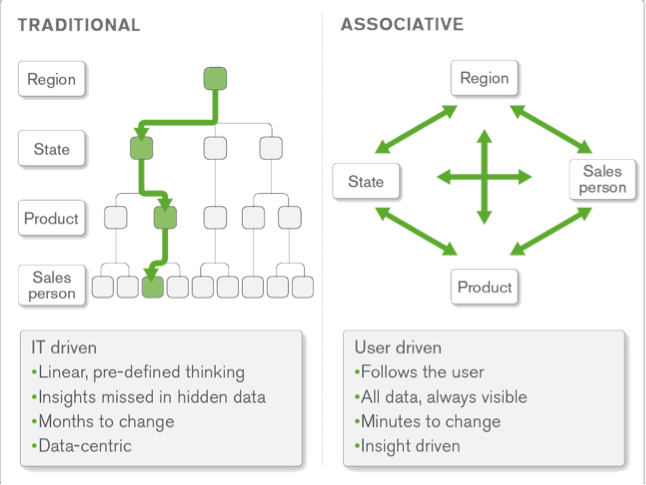
Using QlikView, it is always apparent what data is associated since the selected items are presented with a green background, all related values have a white background and unrelated items are shown with a gray background.
Expanding to larger data sets
Recognizing that many customers need the power of QlikView to analyze volumes of data too large to load into the QlikView in-memory engine, Qlik expanded its engine by adding Direct Discovery, a hybrid approach that combines both in-memory data with dynamic access to data residing in external, big data sources. With this hybrid model, the QlikView engine dynamically formulates and submits queries for external data whenever a user selects in-memory data values that are associated with external data. With Direct Discovery, users are taking full advantage of the QlikView Associative Experience without having to first ingest the raw data from big data sources into QlikView.
Naturally, the ability to run Direct Discovery applications on Hadoop was one of the very first use cases Qlik anticipated so we’ve worked closely with our Hadoop partners to ensure the fastest and easiest means to access HDFS data. We knew we had existing customers using MapReduce to aggregate HDFS data for loading into QlikView and that these same customers would not only want faster load times but also the option of using Direct Discovery on their pre-aggregated data.
Leveraging Apache Spark
Since the advent of Direct Discovery, we’ve followed the Apache Spark project noting its obvious performance benefit of using RAM for inter-stage caching rather than the much higher latency, disk-based approach of traditional MapReduce. We’ve been particularly impressed by the way Spark provides a high performance platform not just for SQL but other critical big data needs such as iterative machine learning algorithms and streaming.
Qlik is thrilled to participate in the Databricks “Certified on Spark” program because we know that Spark is accelerating our customers’ ability to deliver high performance applications that operate on the full spectrum of their HDFS data. For starters, using Shark, QlikView users are now able to use Direct Discovery to utilize the full power of the QlikView Associative Experience over their entire HDFS data set. Using Spark’s RDD API, customers are able to build very succinct, pipeline-style flows that dramatically reduce the time needed to execute their HDFS data reload tasks for batch loaded data.
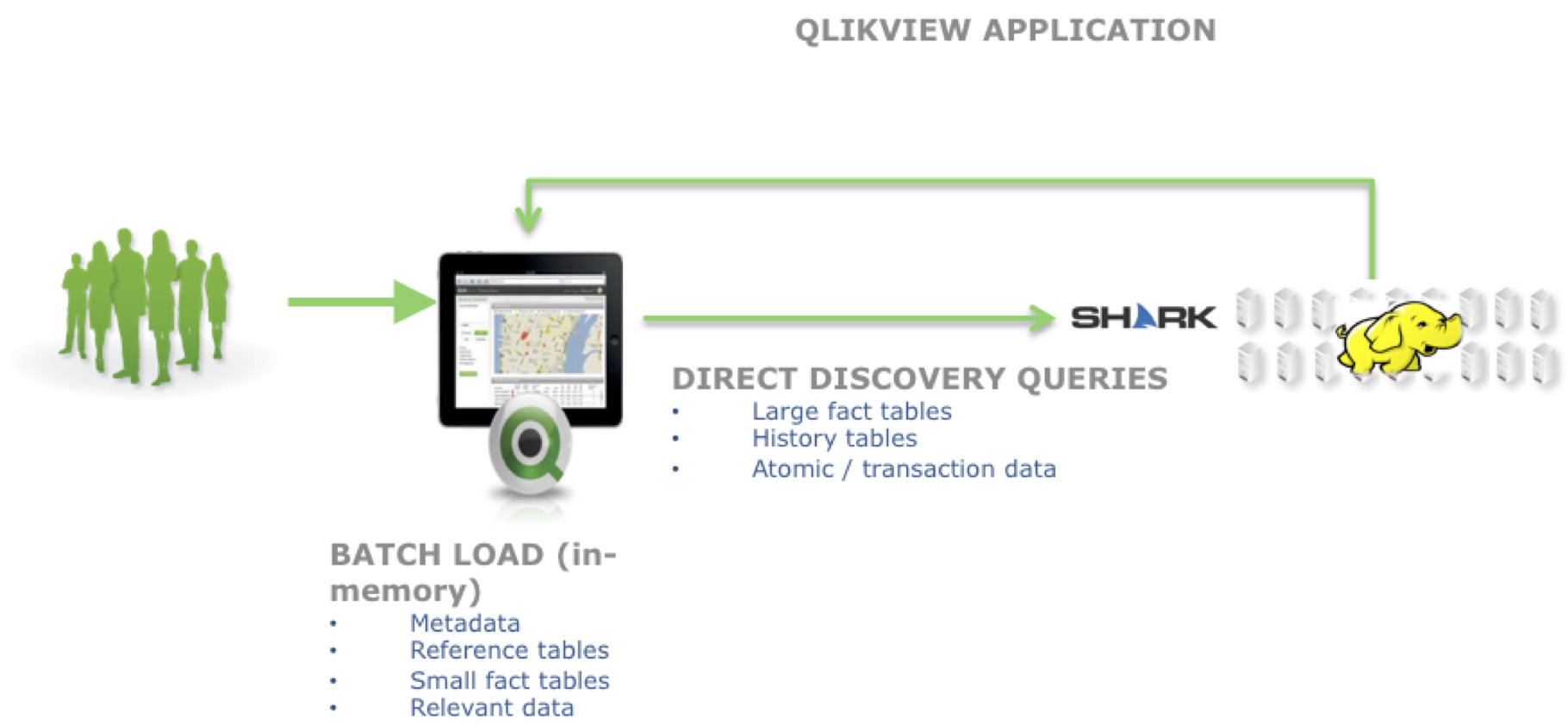
Qlik understands that fast, easy access to increasingly large and diverse sources of data is one of the most critical enablers for deriving maximal business value from data. Clearly Spark significantly advances the accessibility of big data and, by certifying QlikView on Apache Spark, Qlik delivers this enhanced data accessibility to its customers while encouraging the widespread adoption of this critical big data platform.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.