Application Spotlight: Bedrock
Bedrock’s Managed Data Pipeline now includes Apache Spark
It was evident from the all the buzz at the Strata + Hadoop World conference that Apache Spark has now shifted from the early adopter phase to establishing itself as an integral and permanent part of the Hadoop ecosystem. The rapid pace of adoption is impressive!
Given the entrance of Spark into the mainstream Hadoop world, we are glad to announce that Bedrock is now officially Certified on Spark.
How does Spark enhance Bedrock?
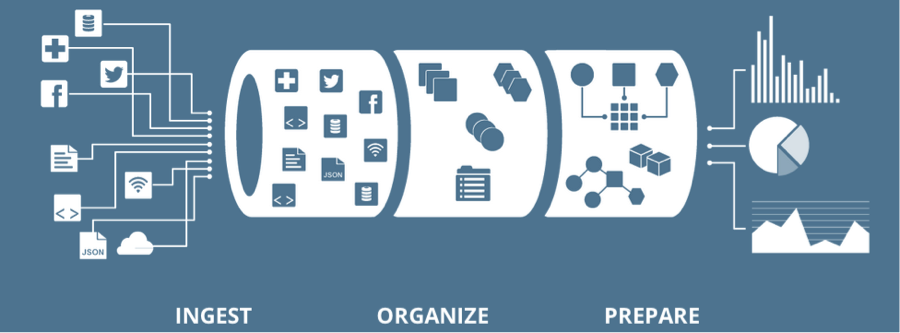
Bedrock™ defines a Managed Data Pipeline as consisting of Ingest, Organize, and Prepare stages. Bedrock’s strength lies in the integrated nature of the way data is handled through these stages.
● Ingest: Bring data from various sources into Hadoop
● Organize: Apply business, technical, and operational metadata to the incoming data
● Prepare: Orchestrate workflows that perform data quality checks, mask sensitive fields, run change data capture actions and transformations.
The Prepare stage of the Managed Data Pipeline is where Bedrock and Spark truly complement each other. Data preparation is all aspects of getting raw data ready for analytics and reporting. Spark is ideally suited to perform the type of processing required for data preparation. Combining high-speed, in-memory execution with a robust set of native actions and transformations makes Spark a natural fit. In Bedrock 3.1, Spark is now part of Bedrock’s workflow design palette that supports 20+ built in workflow actions that you can drag and drop onto the canvas to create your preparation workflow. If you prefer using SQL, you can use the Bedrock SparkSQL action.
Let us look at a typical Bedrock Managed Data Pipeline to see where Spark fits. One very common use-case for Bedrock is moving data from a traditional relational database into HDFS and making the data available in Hive. To create this Managed Data Pipeline in Bedrock, we start with the Bedrock landing zone to reliably ingest the data into HDFS. Business and technical metadata is managed and operational metadata is captured as the data arrives and loads into Hadoop. In the Prepare phase, the built-in Bedrock capabilities for checking data quality, masking sensitive data, or merging incremental changes may be required. We finally round out the Prepare stage of the Managed Data Pipeline through the use of Spark or SparkSQL to implement custom or proprietary transformations, aggregations, and analysis.
Looking to the Future
This is only the beginning of the value that Bedrock and Spark together can bring to the Managed Data Pipeline. In the future, Bedrock will be extended to support the full Spark ecosystem and existing Bedrock preparation actions, such as masking, data quality checks, and change data capture, will be available with Spark implementations.
To learn more about Bedrock and a Spark enabled Managed Data Pipeline, visit us online zaloni.com, or feel free to contact me directly at mmackinnon@zaloni.com
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.