Introducing GraphFrames
by Ankur Dave, Joseph Bradley and Tim Hunter
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
We would like to thank Ankur Dave from UC Berkeley AMPLab for his contribution to this blog post.
Databricks is excited to announce the release of GraphFrames, a graph processing library for Apache Spark. Collaborating with UC Berkeley and MIT, we have built a graph library based on DataFrames. GraphFrames benefit from the scalability and high performance of DataFrames, and they provide a uniform API for graph processing available from Scala, Java, and Python.
What are GraphFrames?
GraphFrames support general graph processing, similar to Apache Spark’s GraphX library. However, GraphFrames are built on top of Spark DataFrames, resulting in some key advantages:
- Python, Java & Scala APIs: GraphFrames provide uniform APIs for all 3 languages. For the first time, all algorithms in GraphX are available from Python & Java.
- Powerful queries: GraphFrames allow users to phrase queries in the familiar, powerful APIs of Spark SQL and DataFrames.
- Saving & loading graphs: GraphFrames fully support DataFrame data sources, allowing writing and reading graphs using many formats like Parquet, JSON, and CSV.
In GraphFrames, vertices and edges are represented as DataFrames, allowing us to store arbitrary data with each vertex and edge.
An example social network
Say we have a social network with users connected by relationships. We can represent the network as a graph, which is a set of vertices (users) and edges (connections between users). A toy example is shown below.
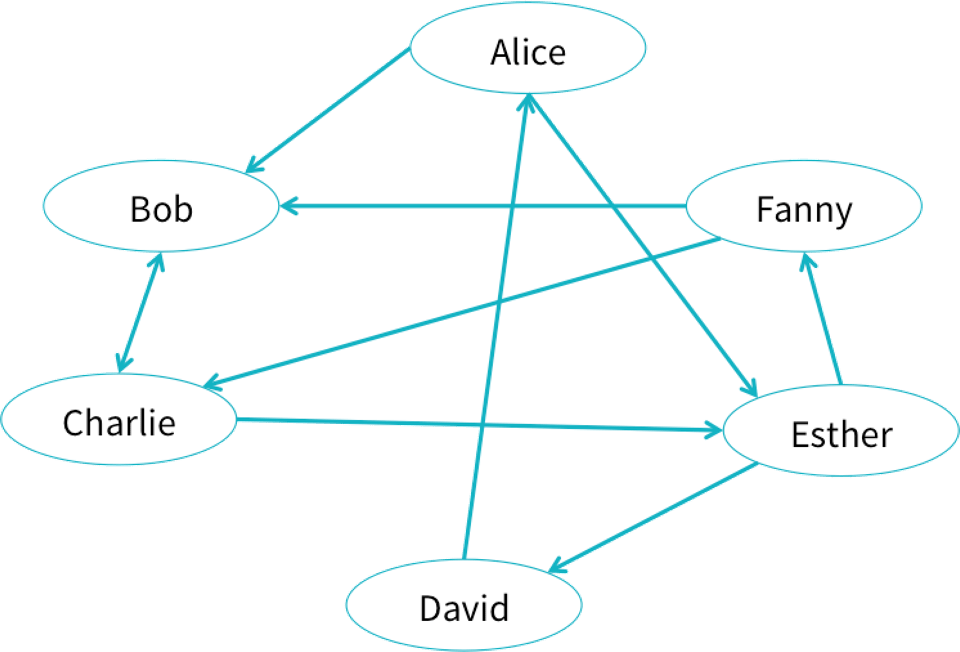
Click on the image to see the full example notebook
We might then ask questions such as “Which users are most influential?” or “Users A and B do not know each other, but should they be introduced?” These types of questions can be answered using graph queries and algorithms.
GraphFrames can store data with each vertex and edge. In a social network, each user might have an age and name, and each connection might have a relationship type.
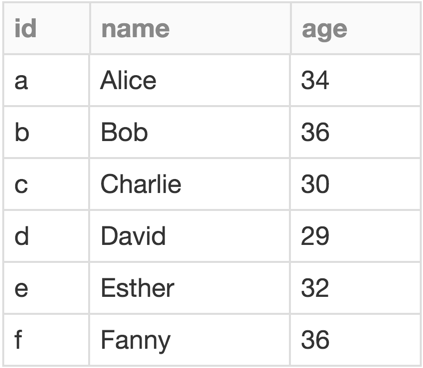

Click on the table to see the full example notebook
Simple queries are simple
GraphFrames make it easy to express queries over graphs. Since GraphFrame vertices and edges are stored as DataFrames, many queries are just DataFrame (or SQL) queries.
Example:
How many users in our social network have “age” > 35?
We can query the vertices DataFrame:g.vertices.filter("age > 35")
Example:
How many users have at least 2 followers?
We can combine the built-in inDegrees method with a DataFrame query.g.inDegrees.filter("inDegree >= 2")
Graph algorithms support complex workflows
GraphFrames support the full set of algorithms available in GraphX, in all 3 language APIs. Results from graph algorithms are either DataFrames or GraphFrames. For example, what are the most important users? We can run PageRank:
results = g.pageRank(resetProbability=0.15, maxIter=10)
display(results.vertices)
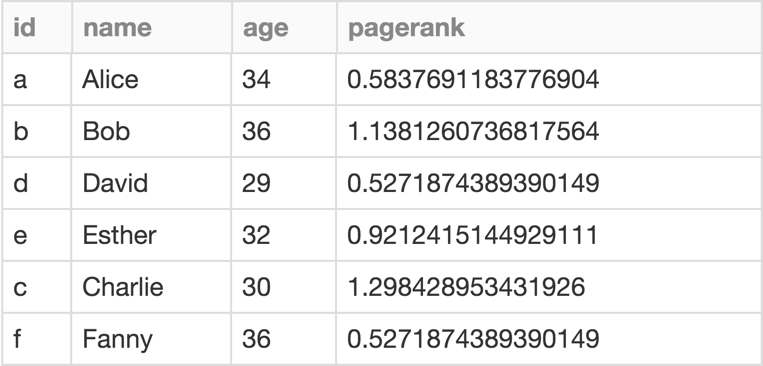
Click on the table to see the full example notebook
GraphFrames also support new algorithms:
- Breadth-first search (BFS): Find shortest paths from one set of vertices to another
- Motif finding: Search for structural patterns in a graph
Motif finding lets us make powerful queries. For example, to recommend whom to follow, we might search for triplets of users A,B,C where A follows B and B follows C, but A does not follow C.
Motif: A->B->C but not A->C
results = g.find("(A)-[]->(B); (B)-[]->(C); !(A)-[]->(C)")
Filter out loops (with DataFrame operation)
results = results.filter("A.id != C.id")
Select recommendations for A to follow C
results = results.select("A", "C")
display(results)
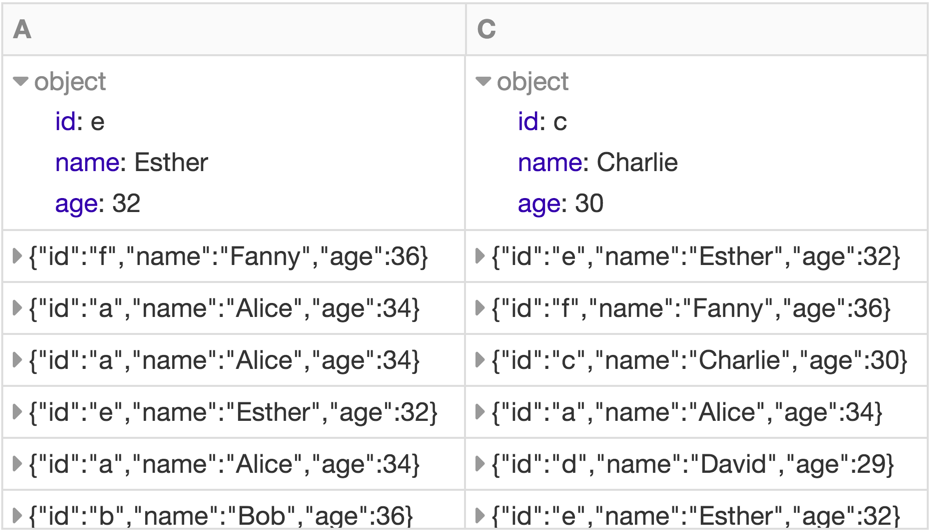
Click on the table to see the full example notebook
The full set of GraphX algorithms supported by GraphFrames is:
- PageRank: Identify important vertices in a graph
- Shortest paths: Find shortest paths from each vertex to landmark vertices
- Connected components: Group vertices into connected subgraphs
- Strongly connected components: Soft version of connected components
- Triangle count: Count the number of triangles each vertex is part of
- Label Propagation Algorithm (LPA): Detect communities in a graph
GraphFrames integrate with GraphX
GraphFrames fully integrate with GraphX via conversions between the two representations, without any data loss. We can convert our social network to a GraphX graph and back to a GraphFrame.
val gx: Graph[Row, Row] = g.toGraphX()
val g2: GraphFrame = GraphFrame.fromGraphX(gx)
What's next?
Graph-specific optimizations for DataFrames are under active research and development. Watch Ankur Dave’s Spark Summit East 2016 talk to learn more. We plan to include some of these optimizations in GraphFrames for its next release!
Get started with these tutorial notebooks in Scala and Python in the free Databricks Community Edition.
Download the GraphFrames package from the Spark Packages website. GraphFrames are compatible with Spark 1.4, 1.5, and 1.6.
The code is available on Github under the Apache 2.0 license. We welcome contributions! Check the Github issues for ideas to work on.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.