Using AWS Lambda with Databricks for ETL Automation and ML Model Serving
As a Data Solutions Architect, I partner with clients to build end-to-end solutions with Databricks. Databricks is built on top of AWS, is natively compatible with all the AWS offerings, and all our clients are avid AWS users. Naturally, this means I often advise them on architectural issues such as how to integrate Databricks with the broader AWS ecosystem.
In this blog, I will show how to leverage AWS Lambda and Databricks together to tackle two use cases: an event-based ETL automation (e.g., partition creations for a Spark SQL table or job trigger using Databricks’ REST API) and serving Machine Learning model results trained with Apache Spark.
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
A Little Background on AWS Lambda
Lambda is a managed compute service that allows you to run a custom function in response to an event (e.g., writes to a specific AWS S3 bucket) without having to set up a server. Compute resources, capacity provisioning, automatic scaling, code monitoring, logging, and code and security patch deployment are all managed by AWS. It supports three programming languages, Java, Python and Node.Js.
Lambda is the perfect complement to Databricks to trigger an action based on an events in other AWS services. The Databricks REST API provides a mechanism to connect your Spark clusters with Lambda.
An Introduction to Databricks’ REST API
The Databricks REST API enables programmatic access to Databricks, (instead of going through the Web UI). It can automatically create and run jobs, productionalize a data flow, and much more. For more information on how the API works, read the documentation or this blog.
For this next example, I will demonstrate how to use the API to automate an ETL job.
Example #1: ETL Automation
There are cases where a daily ETL job cannot be scheduled on a set time. For example, sometimes you need a specific number of data points to be available, or there could be considerable daily variability - making a simple CRON job not a good option. In this and other similar situations, an AWS Lambda function can be used to check for the condition(s) across a variety of systems (e.g. whether data landing is in S3 or Kinesis) and start the job via Databricks’ REST API.In the example illustrated by the diagram below, the custom function is triggered by S3 as new data lands in a bucket. The lambda function triggers Databricks’ job is using the REST API. Specifically, a variety of data lands in S3 (step 1); an event notification is pushed to the custom function in Amazon Lambda (step 2); a custom function makes a REST API call to Databricks to start a new job (step 3); and as part of the ETL job Databricks reads and write data to/from S3 (step 4).
In the example illustrated by the diagram below, the custom function is triggered by S3 as new data lands in a bucket. AWS Lambda triggers Databricks’ job is using the REST API. Specifically, a variety of data lands in S3 (step 1); an event notification is pushed to the custom function in AWS Lambda (step 2); a custom function makes a REST API call to Databricks to start a new job (step 3); and as part of the ETL job Databricks reads and write data to/from S3 (step 4).
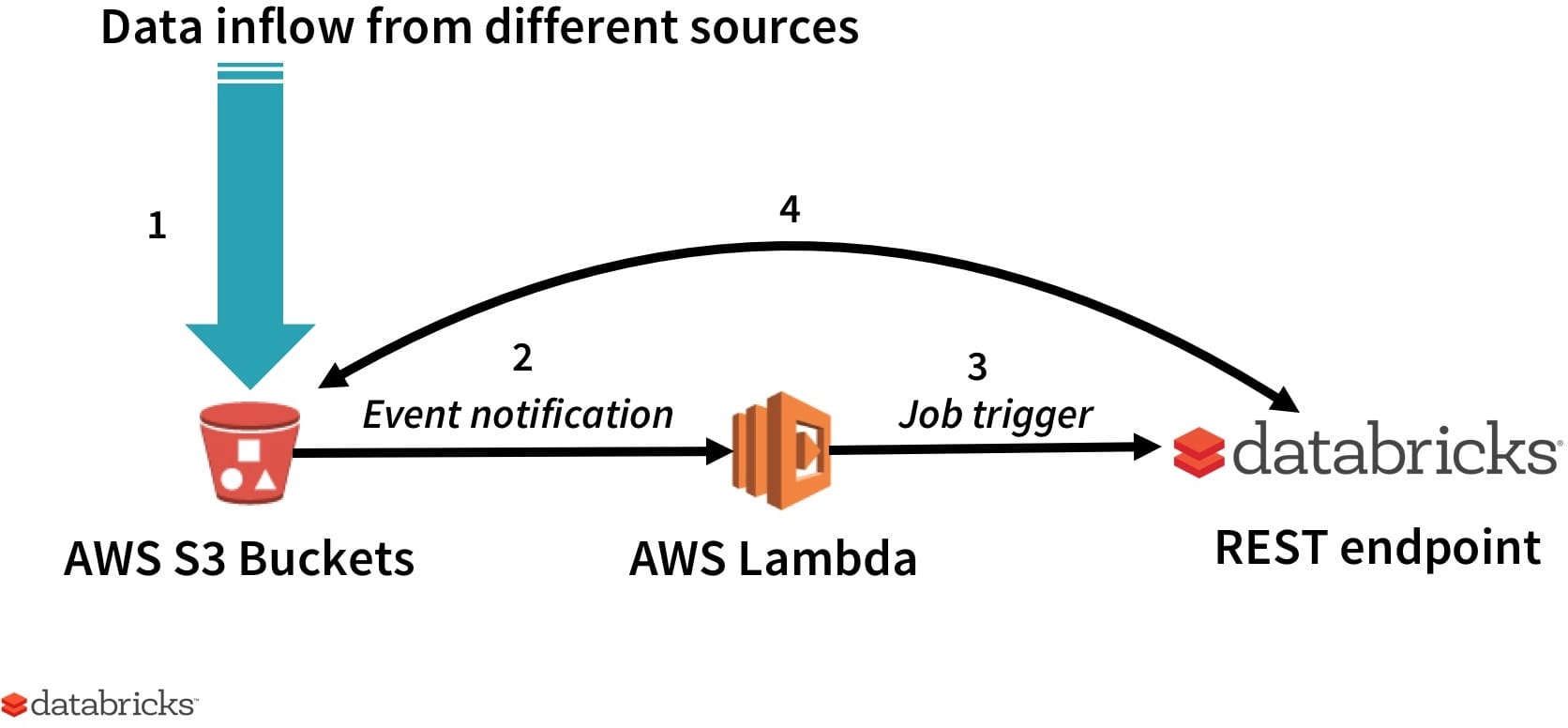
Figure 1: ETL automation: 1) Data lands is S3 from variety of sources, 2) An event is triggered and a call is made to the custom function in AWS Lambda, 3) Custom function makes a REST API call to Databricks to start a new job, 4) As part of the ETL job Databricks reads and writes data to/from S3.
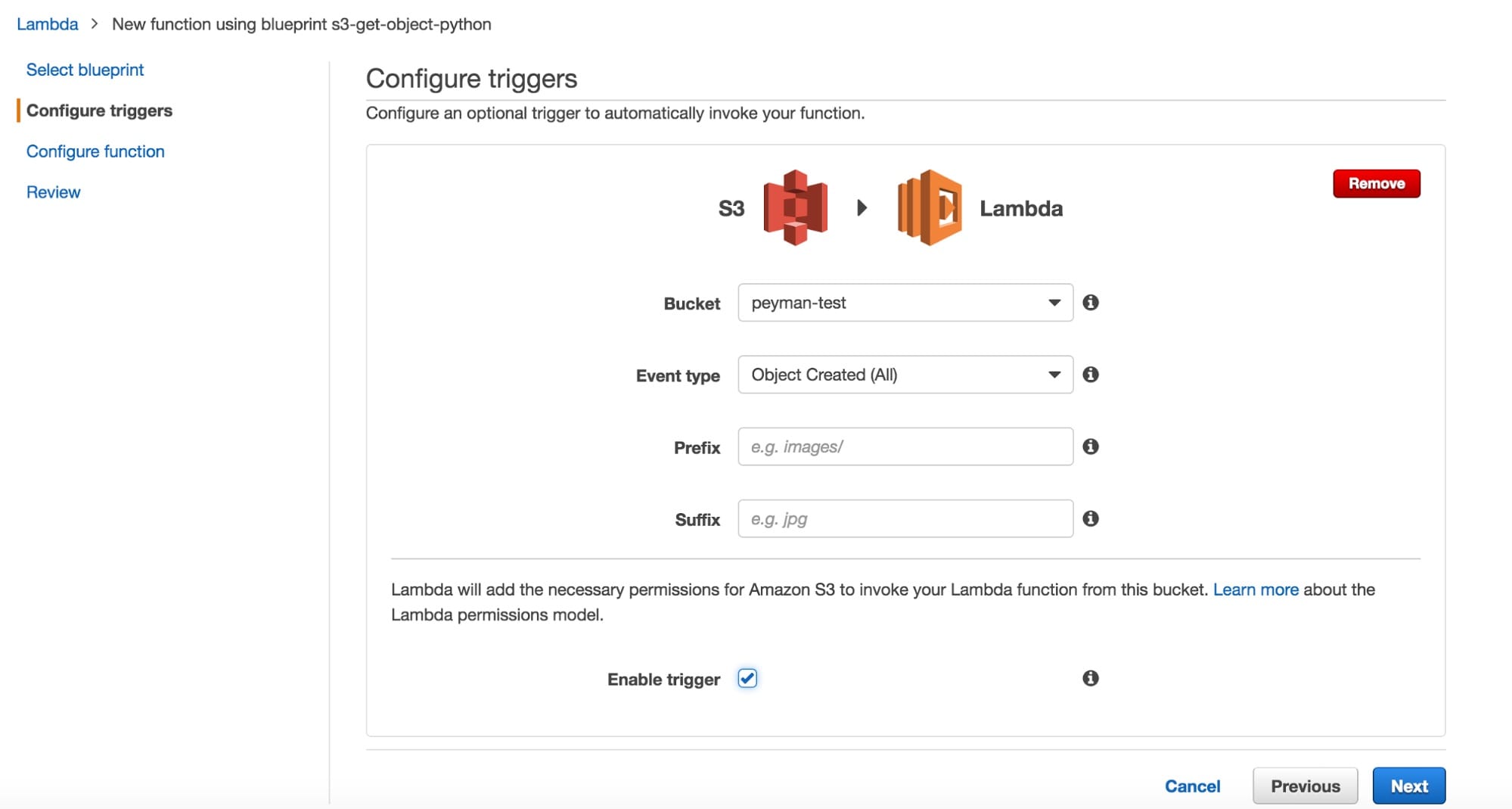
Figure 2: Screen-shot of Amazon Lambda’s configuration page. In the Prefix and Suffix fields, you could further limit the scope that will trigger the notifications by providing a prefix or suffix such as file extension. If not specified, all the objects created in the bucket trigger the notification.
The code below shows the custom lambda function written in Node.js. It makes an HTTPs post call to a REST endpoint in Databricks. The JSON load is a key / value (job_id and the actual job number), of a preconfigured Spark job in Databricks. You can learn how Spark jobs work in Databricks in this video.
Example #2: Machine Learning Model Serving
In this example, we use a prediction model trained in Databricks using Spark ML’s Random Forest Regressor. This data is an hourly snapshot of riders in a bike sharing system. For each hour, we are given the count of registered, casual, and total riders currently using a bike as well as information regarding the date and weather. Based on the data, we train a machine learning model to predict the number of riders in the D.C. bike sharing system for a given hour. Once the model is trained, we apply it to a test set of data and write the resulting predictions to a NoSQL database (in this case Riak TS). For more information about this model, take a look at part 3 and 4 of the Data Modeling notebook.
In the example above, training data are stored in S3 and model creation and prediction results are written to Riak TS in batch mode. AWS Lambda is a good solution to serve the results of model prediction out of a persistence layer without dealing with any headaches around scaling, versioning, and security. Similarly, Lambda can be used to serve prediction results out of DynamoDB, Redis, or other appropriate data storage systems. This approach is not limited to regression models: it can be used for building a recommender system or a classifier just as well. One of the issues with this approach is that it is limited to prediction with categorical features (e.g. city, and state in this case). For continuous features like temperature with unbounded number of possible values, one can discretize the continuous feature (i.e., using QuantileDiscretizer), details of which are beyond the scope of this blog.
It is also possible to expand on this use case and ingest training data as a stream using Kinesis (or Kafka) with Spark Streaming. In the cases where the ML algorithm allows streaming updates (e.g. K-Means or Logistic Regression), we can update the model in near real-time. There is going to be some latency between near real-time model updates and refreshing of the prediction results in the database.
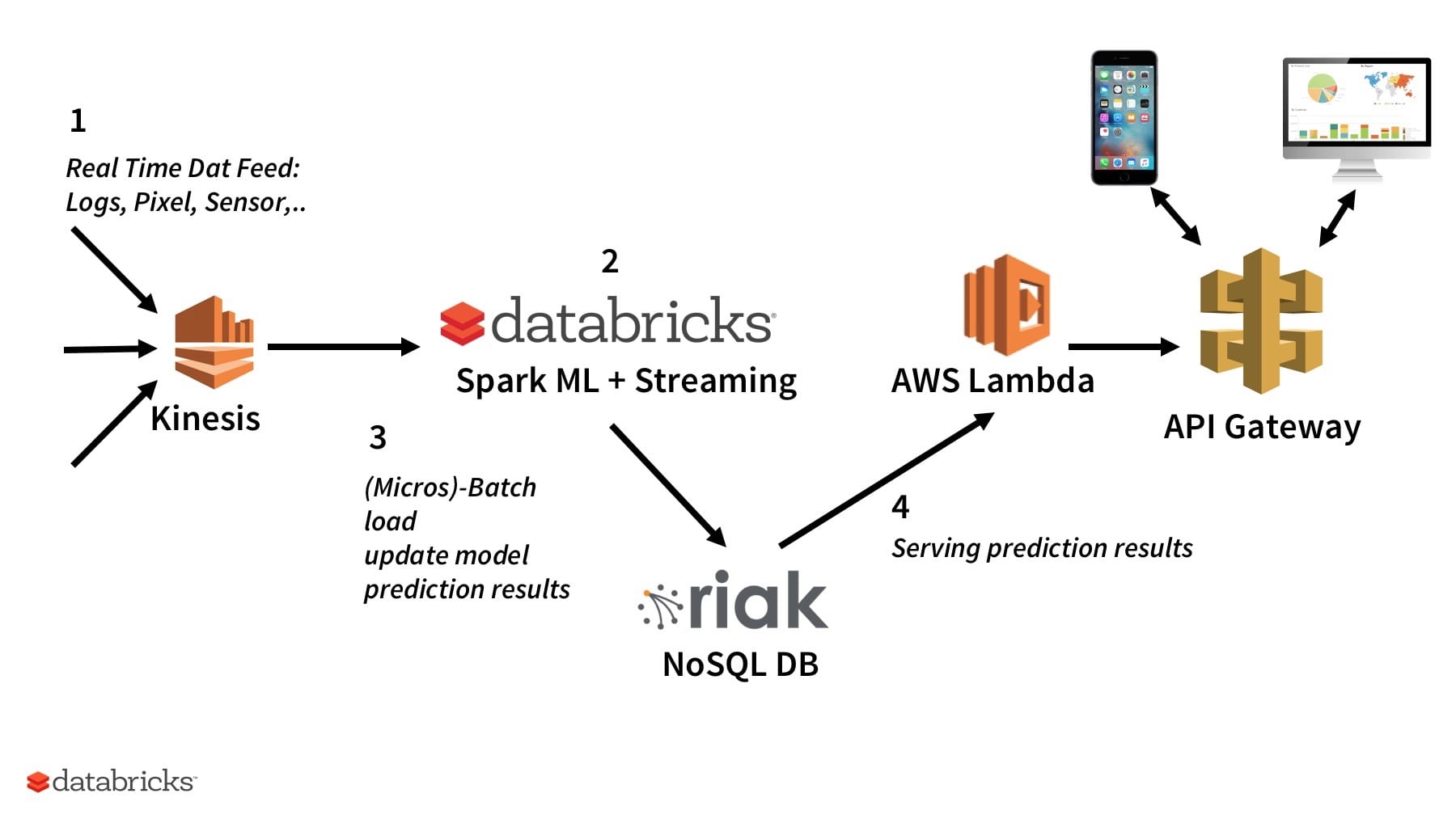
Figure 3: Machine Learning Model Serving: 1) real-time data feed, e.g. logs, pixels or sensory data land on Kinesis, 2) Spark’s Structured Streaming pulls data for storage and processing, both batch or near-real time ML model creation / update, 3) Output model predictions are written to Riak TS, 4) AWS Lambda and AWS API Gateway are used to serve the prediction results to a variety of clients.
The code below shows a custom lambda function written in Java. It makes a call to the Riak server to pull the predicted number of riders based on the city, state and time information. The JSON load is, e.g. {"city": "Washington", "state": "D.C.", "time": "1356436800000"}, same parameters as the notebook.
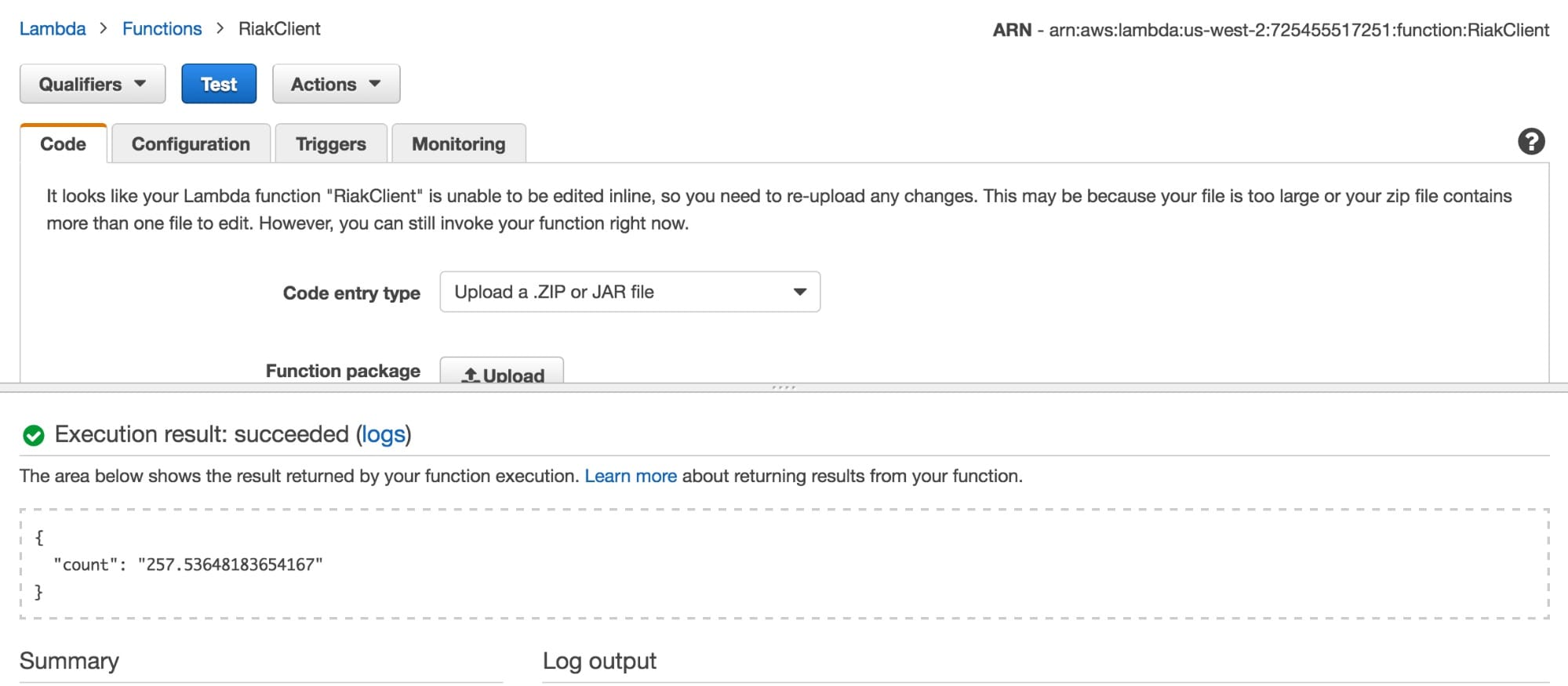
Figure 4: Screenshot of AWS Lambda’s configuration page. Predicted count for Christmas 2012 at 12 noon riders matches section 4 of the notebook.
What’s Next
Now that you have seen how Databricks can work with AWS Lambda, you can try it for yourself. Sign-up for a free trial to start experimenting with Databricks’ Apache Spark clusters, APIs, and more (choose the platform trial to get full access to the API).
This is the first in a series of blogs on how to use Databricks with other services in the AWS ecosystem, follow us on Twitter or sign-up for our newsletter to get notified when a new blog gets posted.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.