Databricks and Apache Spark 2016 Year in Review
by Reynold Xin, Jules Damji, Dave Wang and Matei Zaharia
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Spark Summit will be held in Boston on Feb 7-9, 2017. Check out the full agenda and get your ticket before it sells out!
In 2016, Apache Spark released its second major version 2.0 and outgrew our wildest expectations: 4X growth in meetup members reaching 240,000 globally, and 2X growth in code contributors reaching 1000.
In addition to contributing to the success of Spark, Databricks also had a phenomenal year. We have rolled out a large number of features such as end-to-end security, seen a 40X increase in our number of active users, enterprise thought leaders adopting Databricks across industries, and last but not least our series C funding enabling us to expand and broaden the horizon of big data.
In the remainder of this blog post, we want to reflect on the major milestones we achieved in this short year—and to look forward to the next year:
- SQL-2003: the most advanced and standard-compliant Big Data SQL engine
- CloudSort Record: Spark and Databricks as the most efficient platform
- Structured Streaming: dramatically simpler streaming
- Deep Learning and GPUs on Databricks
- DBES, HIPAA, GovCloud, and SOC 2: End-to-end Security for Spark
- Databricks Community Edition: Best Place to Learn Spark
SQL-2003 and Advanced SQL
SQL is a universal language used by data engineers, scientists, analysts for data big and small. As of Spark 2.0, Spark SQL has become one of the most feature-rich and standard-compliant SQL query engines in the Big Data space.
To build a high-performing SQL engine, we first introduced Spark SQL with a query optimizer called Catalyst in 2014. Leveraging advanced programming language features, Catalyst is the most flexible and advanced production-grade query optimizer. With Catalyst, we were able to quickly implement functionalities that used to take years to implement in traditional MPP SQL query engines.
In May, we announced that Spark SQL could run all 99 TPC-DS queries without modifications. TPC-DS is a standard benchmark for SQL analytic workloads and it poses great challenges for query engines due to its use of complex features such as subqueries and analytic functions. Most of the Big Data SQL query engines that you have heard of, such as Apache Hive, Apache Impala and Presto, are not capable of running all the queries in this benchmark.
At the same time, we announced phase two of Project Tungsten, inspired by ideas in state-of-the-art research in both database systems and modern compilers. Tungsten is capable of running modern database operations (e.g. filter, hash join) in roughly one nanosecond per simple row, making it the most advanced execution engine you can find in open source databases.
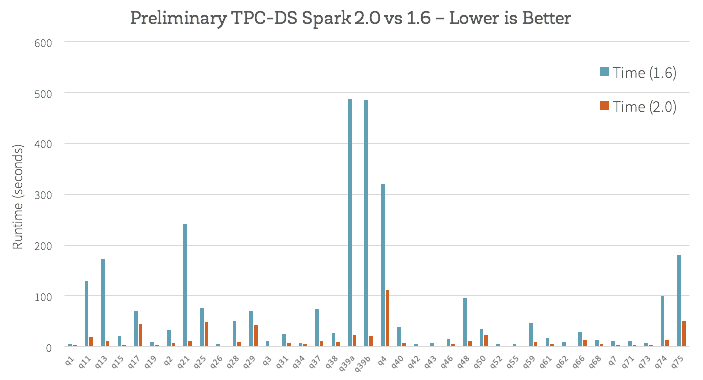
In 2016, Spark SQL emerged as one of the most feature-rich, standard-compliant, and performant Big Data SQL query engines. This investment reduces the friction for our customers to scale out their workloads over Spark SQL.
CloudSort Record: The Most Efficient Platform
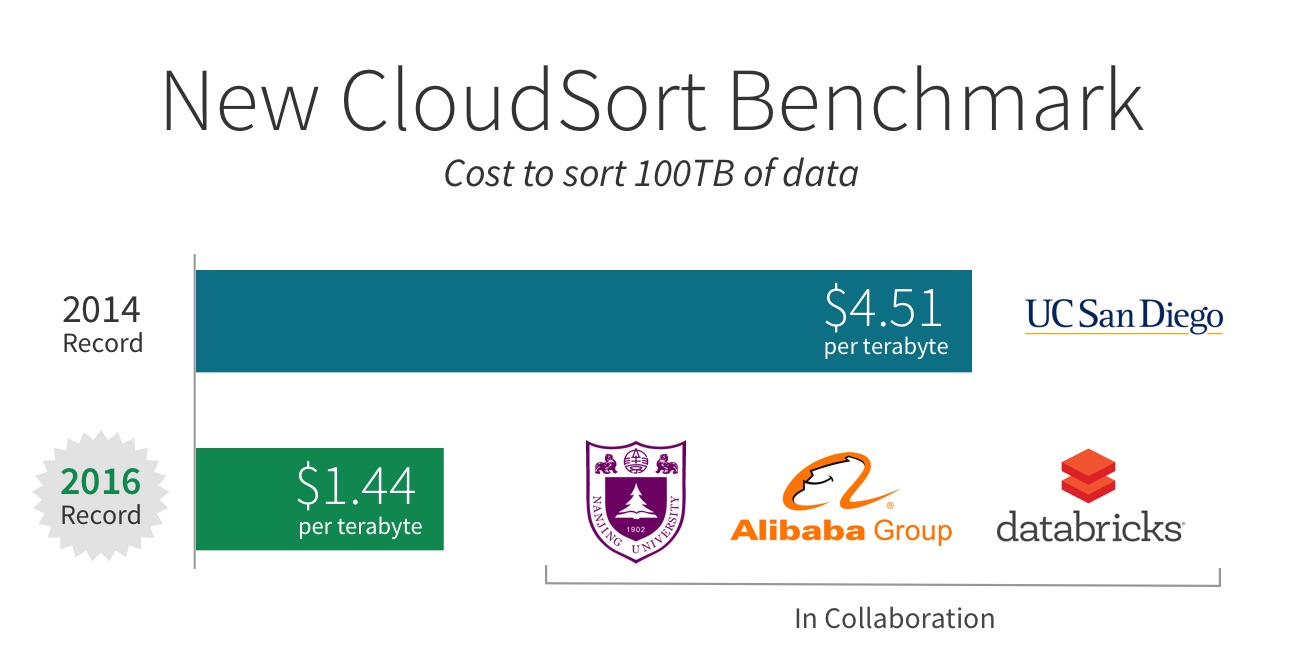
Apache Spark is known for its speed, and we have been using various third-party, independent benchmarks in order to evaluate the progress made in this area. In 2014, Databricks entered the Sort Benchmark and set a world record in GraySort for the fastest time to sort 100TB of data using Spark.
Earlier this year, in order to validate our ability to architect the most performant and cost-efficient cloud data platform, we again entered the competition in the CloudSort category, which picks the winner with the lowest cost, measured by public cloud pricing. This benchmark effectively measures the efficiency, i.e. ratio of performance to cost, of the cloud architecture (combination of software stack, hardware stack, and tuning).
As joint effort with Nanjing University, Alibaba Group, and Databricks, we architected the most efficient way to sort 100 TB of data, beating out all other competitors using only $144.22 USD worth of cloud resources. Through this benchmark, Databricks demonstrated it offers the most efficient way to process data in the cloud.
Structured Streaming: Dramatically Simpler Streaming
Spark 2.0 adds the first version of a new higher-level API, Structured Streaming, for building continuous applications. The main goal is to make it easier to build end-to-end real-time applications, which integrate with storage, serving systems, and batch jobs in a consistent and fault-tolerant way.
Having learned from hundreds of Spark users, we designed Structured Streaming with a number of unique properties that are extremely important to real-life applications:
- Same programming model and API as batch: Unlike other streaming engines that have separate APIs for batch and streaming, Structured Streaming simply uses the same programming model for both, making streaming easy to reason about.
- Transactional semantics and exactly-once processing: We understand that insights from data is only as good as the quality of the data itself, so we have built Structured Streaming to be transactional and exactly-once from the beginning. Users can be sure of the correctness of the results they get from the engine.
- Interactive queries: Users can use the batch API to perform interactive queries directly on live streams.
- SQL support: Thanks to the programming model, SQL support is built into the engine.
The recently released Spark 2.1 made measurable strides in the production readiness of Structured Streaming, with added support for event time watermarks and Apache Kafka 0.10.
At Databricks, we religiously believe in dogfooding. We have ported many of our internal data pipelines as well as worked with some of our customers to port their production pipelines using Structured Streaming. In coming weeks, we will be publishing a series of blog posts on various aspects of Structured Streaming as well as our experience with it. Stay tuned for more deep dives.
Deep Learning and GPUs: Boris Brexit Johnson Daydreamed on Databricks
Neural networks have seen spectacular progress during the last few years and they are now the state of the art in image recognition and automated translation. With our customer-first mantra, and by listening to the needs of our customers from a wide variety of industries, we worked on adding deep learning functionalities to the Databricks platform as well as releasing an open source library called TensorFrames that integrates Apache Spark and TensorFlow.
Databricks now offers a simple way to leverage GPUs to power image processing, text analysis, and other machine learning tasks. Users can create GPU-enabled clusters with EC2 P2 instance types. Databricks includes pre-installed NVIDIA drivers and libraries, Apache Spark deployments configured for GPUs, and material for getting started with several popular deep learning libraries.
At Spark Summit Europe, we conducted a live demo applying a deep learning model called “Deep Dream” on Boris Johnson:

This blog post covers how to use popular deep learning libraries such as TensorFlow, Caffe, MXNet, and Theano on Databricks, with GPUs ready to go.
DBES, HIPAA, GovCloud, and SOC 2: End-to-end Security for Apache Spark
Enterprise-grade data platforms must be secure, easy-to-use, and performant. Historically, new shiny technologies often focus more on performance and capabilities while lagging behind in security, and as a result enterprises have to choose among two out of the three properties they desire.
That’s not the case with Apache Spark on Databricks. Databricks Enterprise Security (DBES) is a suite of security features that includes SAML 2.0 compatibility, role-based access control, end-to-end encryption, and comprehensive audit logs. DBES will provide holistic security in every aspect of the entire big data lifecycle.
For customers in regulated industries such as the public sector and healthcare, we also expanded into the AWS GovCloud (US) and created a HIPAA-compliant offering. These enhancements enable IT and platform technology teams to focus on architecture and administer corporate policy, bypassing the difficult process of building, configuring, and maintaining Spark infrastructure. To bolster end-to-end enterprise security, we achieved SOC 2 Type 1 certification, where auditors endorsed Databricks' platform as architected, from the ground up, according to security best practices.
At Databricks, we are proud to be the only Apache Spark platform with all these capabilities.
Databricks Community Edition: Best Place to Learn Spark
When we founded Databricks, we recognized that one of the largest challenges to Big Data is not in the technologies themselves, but in the talent gap. The number of engineers, data scientists, and business analysts that can understand and manipulate Big Data is too small. To address this challenge, we create tools that are simpler to use and build training curriculums and platforms to educate the next generation.
Launched in February, Databricks Community Edition is designed for developers, data scientists, engineers and anyone who wants to learn Spark. On this free platform, users have access to a micro-cluster, a cluster manager, and the notebook environment to prototype simple applications. All users can share their notebooks and host them free of charge with Databricks.

In addition to the platform itself, Databricks Community Edition comes with a rich portfolio of Spark training resources, including our award-winning Massive Open Online Courses, e.g. “Introduction to Big Data with Apache Spark.”
Today, Databricks Community Edition is used as a default platform for learning at MOOCs, EdX courses. Numerous universities such as UC Berkeley have also started computer science courses using this platform. At Apache Spark meetups and workshops, presenters use Databricks to demonstrate notebooks and attendees follow presenter-led workshops. We have trained over 50,000 Spark users across our various training platforms.
In Closing
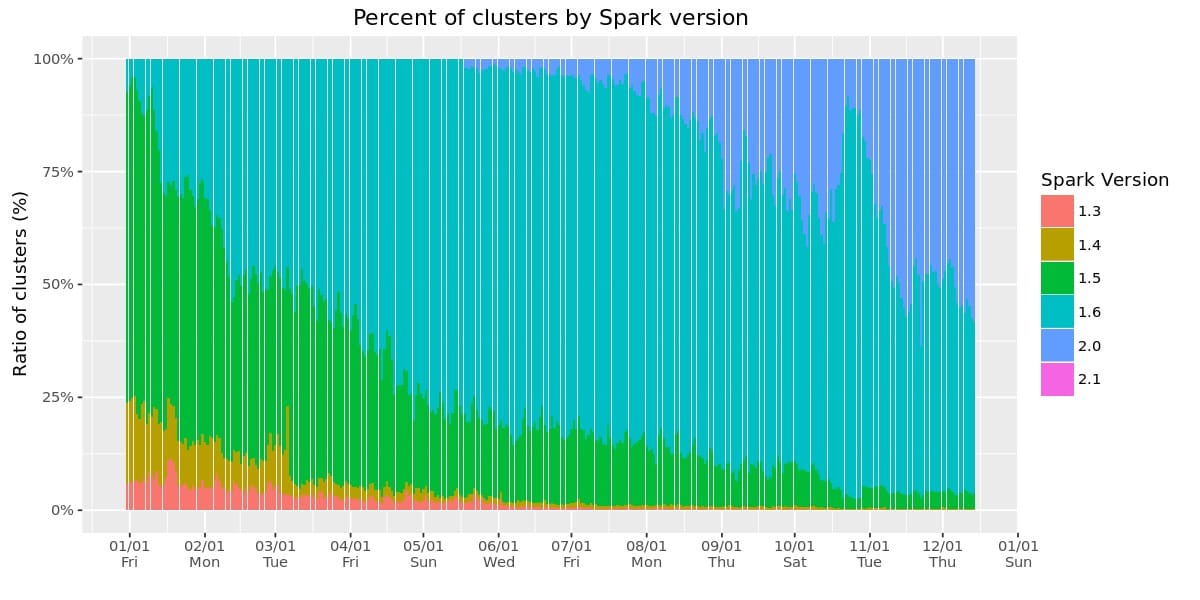
With this rapid pace of development, we are also happy to see how quickly users adopt new versions of Spark. For example, the graph below shows the Spark versions run by over 500 customers at Databricks (note that a single customer can also run multiple Spark versions). The majority of the clusters are now running Spark 2.0 and higher.
2016 is the year Spark reached ubiquity in both the real world and the digital world: We have seen Boris “Brexit” Johnson “daydreamed” using Deep Learning and Spark, Spark t-shirts worn at various gyms across the world (see below), and last but not least, thanks to IBM’s investment, Spark being able to run on mainframe computers in addition to servers.

Through our hard work, the Databricks team has also established ourselves as a trusted partner among many major industry leaders ranging from financial tech, healthcare, advertising tech, media, energy and the public sector. To name a few, DNV GL (the largest technical consultancy for the energy industry in the world), American Diabetes Association, and Viacom all presented about their use cases with Databricks this year at Spark Summit.

In December, we raised $60MM in series C to fuel our mission, to take us forward, to expand and to broaden the horizon of big data into newer Spark applications across a broad range of vertical industries. We will deepen our commitment to open source Apache Spark by investing more engineering resources to contribute code and engage the community. At the same time, we will also continue to expand our platform to make data science and engineering at scale with Spark even easier and faster.
That together we’ve achieved so much this past year is a testament that innovation happens in collaboration and not in isolation.
We want to thank the Spark community for all their hard work in evangelizing Spark at meetups and Spark Summits, sharing best practices, and contributing to Spark’s success. The immense code contributions all over the world are what make the project great. Additionally, we want to thank our customers for providing invaluable feedback.
Our goal at Databricks is to make Big Data simple, and we are only at the beginning of our journey. In 2017, expect tremendous innovations coming from us to make Spark and Databricks more secure, robust, performant, and easier to use, and working with our customers to expand the use of big data across even more industry verticals.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.