Anonymizing Datasets at Scale Leveraging Databricks Interoperability
by Don Hillborn
A key challenge for data-driven companies across a wide range of industries is how to leverage the benefits of analytics at scale when working with Personally Identifiable Information (PII). In this blog, we walk through how to leverage Databricks and the 3rd party Faker library to anonymize sensitive datasets in the context of broader analytical pipelines.
Problem Overview
Data anonymization is often the first step performed when preparing data for analysis. It is important that anonymization preserves the integrity of the data. This blog focuses on a simple example that requires the anonymization of four fields: name, email, social security number and phone number. This sounds easy, right? The challenge is we must preserve the semantic relationships and distributions from the source dataset in our target dataset. This allows us to later analyze and mine the data for important patterns related to the semantic relationships and distribution. So, what happens if there are multiple rows per user? Real data often contains redundant data like rows with repeated full names, emails etcetera that may or may not have different features associated with them. Therefore, we will need to maintain a mapping of profile information.
We want to anonymize the data but maintain the relationship between a given person and their features. So, if John Doe appears in our data set multiple times, we want to anonymize all of John Doe’s PII data while maintaining the relationship between John Doe and the different feature sets associated with John. However, we also must guard against someone reverse engineering our anonymization. To do this, we will use a Python package, known as Faker, designed to generate fake data. Each call to the method fake.name() yields a different random result. This means that the same source file will yield a different set of anonymized data in the target file each time Faker is run against the source file. However, the semantic relationships and distributions will be maintained.
The Solution: Anonymizing Data While Maintaining Semantic Relationships and Distributions.
First, let’s install Faker for anonymization and unicodecsv so we can handle unicode strings without a hassle.
Second, let’s import our packages into the Databricks Notebook. The unicodecsv is a drop-in replacement for Python 2.7's csv module which supports unicode strings without a hassle. Faker is a Python package that generates fake data.
Third, let’s build the function that will anonymize the data
Next, let’s build the function that takes our source file and outputs our target file:
Finally, we will pass our source file to the anonymize function and provide the name and location of the target file we would like it to create. Here we are using the DBFS functionality of Databricks, see the DBFS documentation to learn more about how it works.
You can see all the code in a Databricks notebook here.
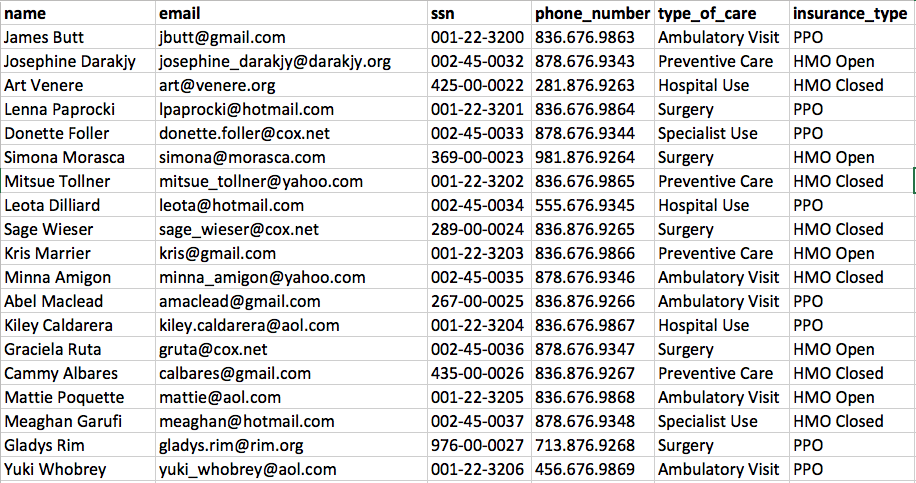
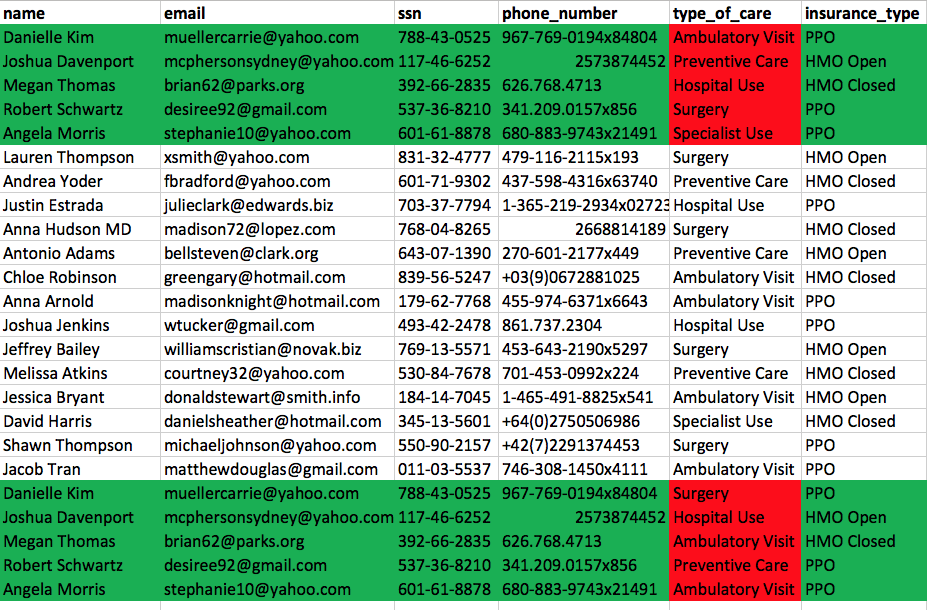
Our source data, shown in Figure 3, has the same patients, highlighted in green appearing multiple times, with different types of care, highlighted in red.
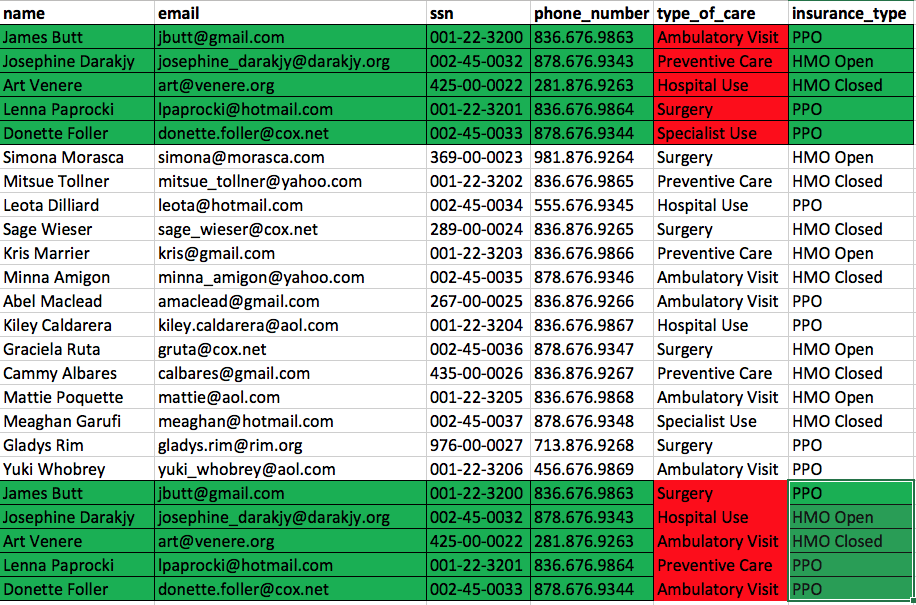
Our anonymization process should anonymize the patient’s PII while maintaining the semantic relationships and distributions. Figure 4 demonstrates that the relationships and distributions are maintained while the PII is completely anonymized.
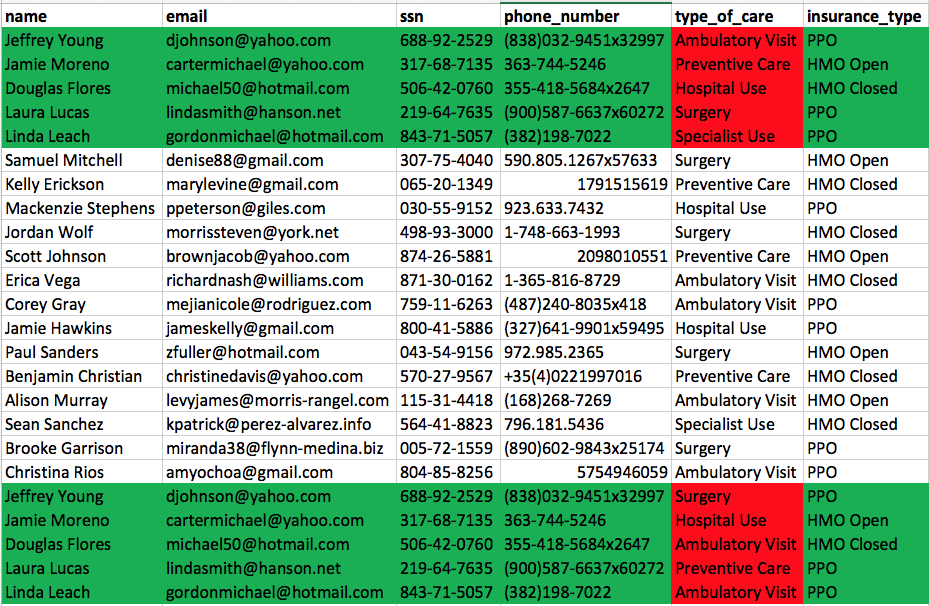
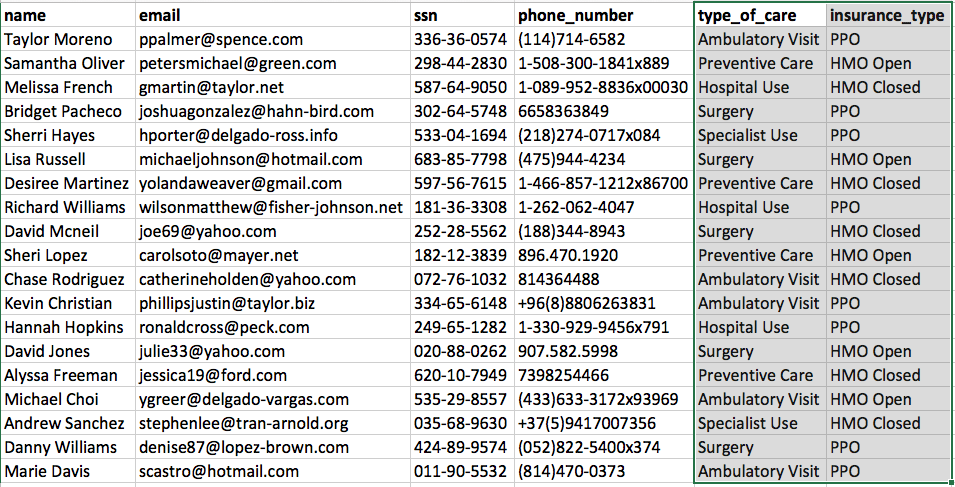
Figure 5 demonstrates that our anonymization is completely random because when we run the source dataset against Faker again we get a completely different set of anonymized data while still maintaining relationships and distributions.
What�’s next
The example code we used in this blog is available as a Databricks notebook, you can try it with a free trial of Databricks. If you are interested in more examples of Apache Spark in action, check out my earlier blog on asset optimization in the oil & gas industry.
This just one of many examples of how Databricks can seamlessly enable innovation in the healthcare industry. In the next installation of this blog, we will build a predictive model using this anonymized data. If you want to get started with Databricks, sign-up for a free trial or contact us.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.