Learn about Apache Spark APIs and Best Practices
by Jules Damji and Silvio Fiorito
Since Apache Spark 1.3, Spark and its APIs have evolved to make them easier, faster, and smarter. The goal has been to unify concepts in Spark 2.0 and beyond so that big data developers are productive and have fewer concepts to grapple with.
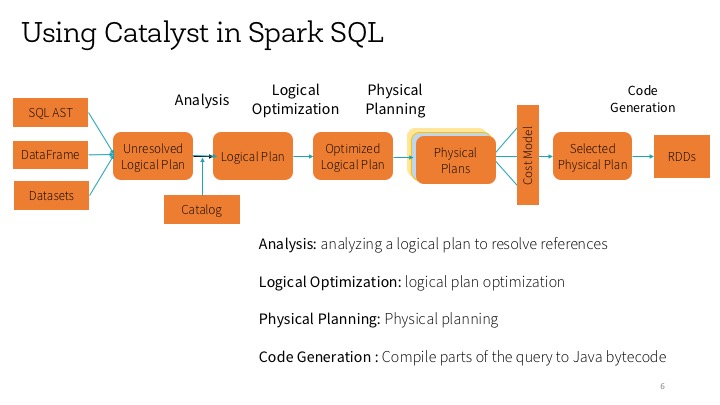
Built atop the Spark SQL engine, with Catalyst optimizer and whole-stage code generation, it helps developers to understand how to use these APIs and employ best practices for data storage, file formats, and query optimization to write their Spark applications.
At the Spark Summit in Dublin, we will present talks on how Spark APIs have evolved, lessons learned, and best practices from the field on how to optimize and tune your Spark applications for machine learning, ETL, and data warehousing. Here are our talks:
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets
- Lessons from the Field: Applying Best Practices to your Apache Spark Applications
Why should you attend these sessions? If you are a data scientist, data analyst or data engineer who wants to comprehend which of the three Spark APIs to use and when or build optimized and well-tuned Spark applications for scale, then attend our talks.
See you in Dublin!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.