Make Your Oil and Gas Assets Smarter by Implementing Predictive Maintenance with Databricks
by Don Hillborn and Denny Lee
How to build an end-to-end predictive data pipeline with Databricks Delta and Spark Streaming
Maintaining assets such as compressors is an extremely complex endeavor: they are used in everything from small drilling rigs to deep-water platforms, the assets are located across the globe, and they generate terabytes of data daily. A failure for just one of these compressors costs millions of dollars of lost production per day. An important way to save time and money is to use machine learning to predict outages and issue maintenance work orders before the failure occurs.
Ultimately, you need to build an end-to-end predictive data pipeline that can provide a real-time database to maintain asset parts and sensor mappings, support a continuous application that processes a massive amount of telemetry, and allows you to predict compressor failures against these datasets.
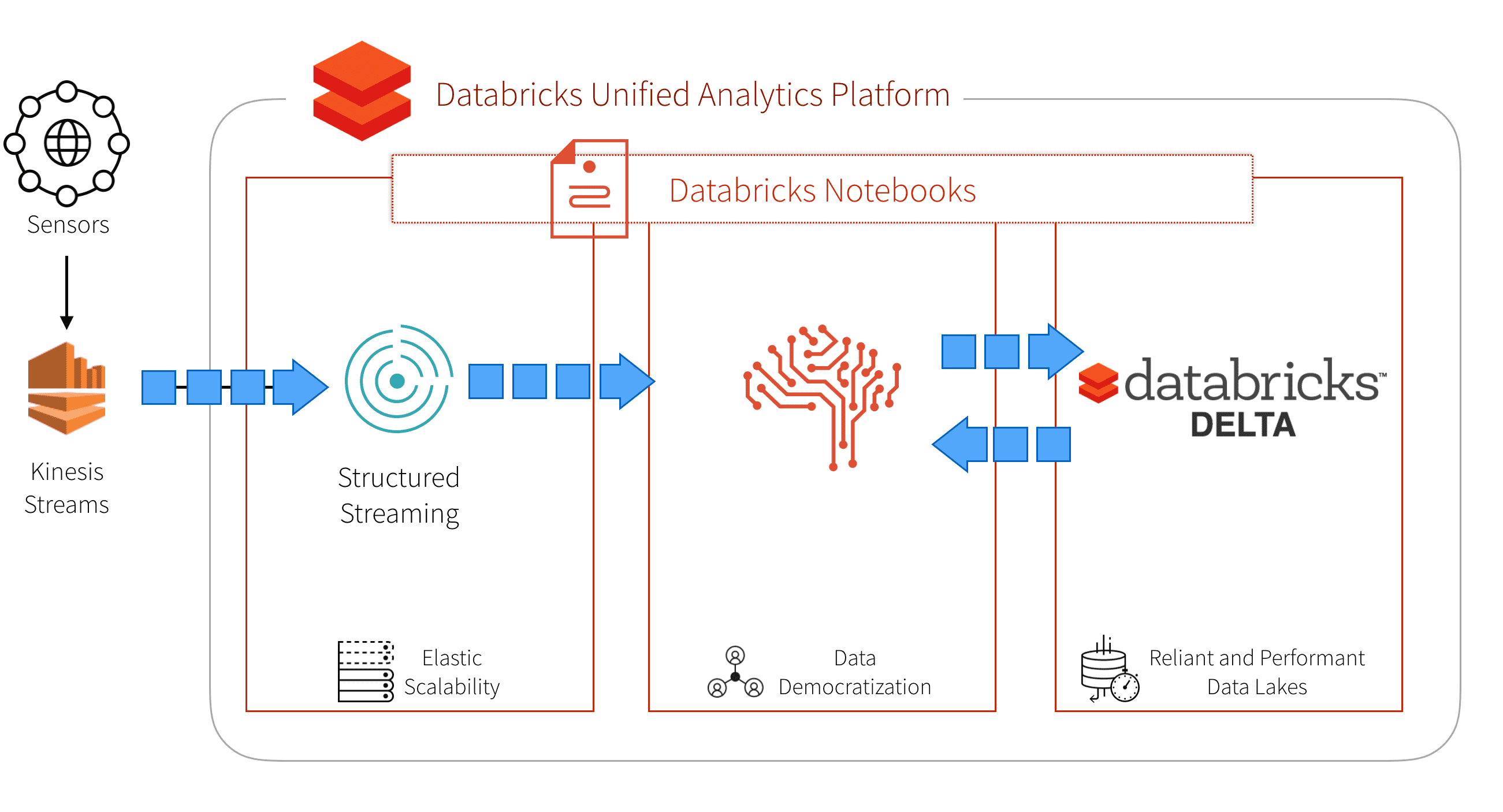
Our approach to addressing these issues is by selecting a unified platform that offers these capabilities. Databricks provides a Unified Analytics Platform that brings together big data and AI and allows the different personas of your organization to come together and collaborate in a single workspace. Other important advantages of the Databricks Unified Analytics Platform include the ability to:
- Spin up the necessary resources and have your data scientists, data engineers, and data analysts making sense of their data quickly.
- Have a multi-cloud strategy allowing everyone to use the same collaborative workspace in Azure or AWS.
- Stand up a diverse set of instance type combinations to optimally run your workloads
- Schedule commands (including REST API commands) that allows you to auto-create and auto-terminate your clusters.
- Quickly and easily enable access control to assign permissions as well as enable access tokens for secure REST API calls when productionizing your solution.
In this blog post, we will show how you can make your oil and gas assets smarter by:
- Using Spark Streaming in Databricks to process the immense amount of sensor telemetry.
- Building and deploying your machine learning models to predict asset failures before they happen.
- Creating a real-time database using Databricks Delta to store and stream sensor parts and assets.
Establishing your Kinesis Stream
To predict catastrophic failures, we need to combine the asset sensors continuous stream of data from Kinesis, Spark Streaming, and our Streaming K-Means model. Let’s start by configuring our Kinesis stream using the code snippet below. To dive deeper, refer to Databricks - Amazon Kinesis Integration.
With your credentials established, you can run a Spark Streaming query that reads words from Kinesis and counts them up with the following code snippet.
To configure your own Kinesis stream, write those words to your Kinesis Stream by creating a low-level Kinesis client such as the following code snippet that loops every 5s.
Explore your Sensor Data
Before we can build our model to predict healthy vs. damaged compressors, let’s start by doing a little data exploration. First, we need to import our healthy and damaged compressor data; the following code snippet imports the healthy compressor data that is in CSV format into a Spark SQL DataFrame.
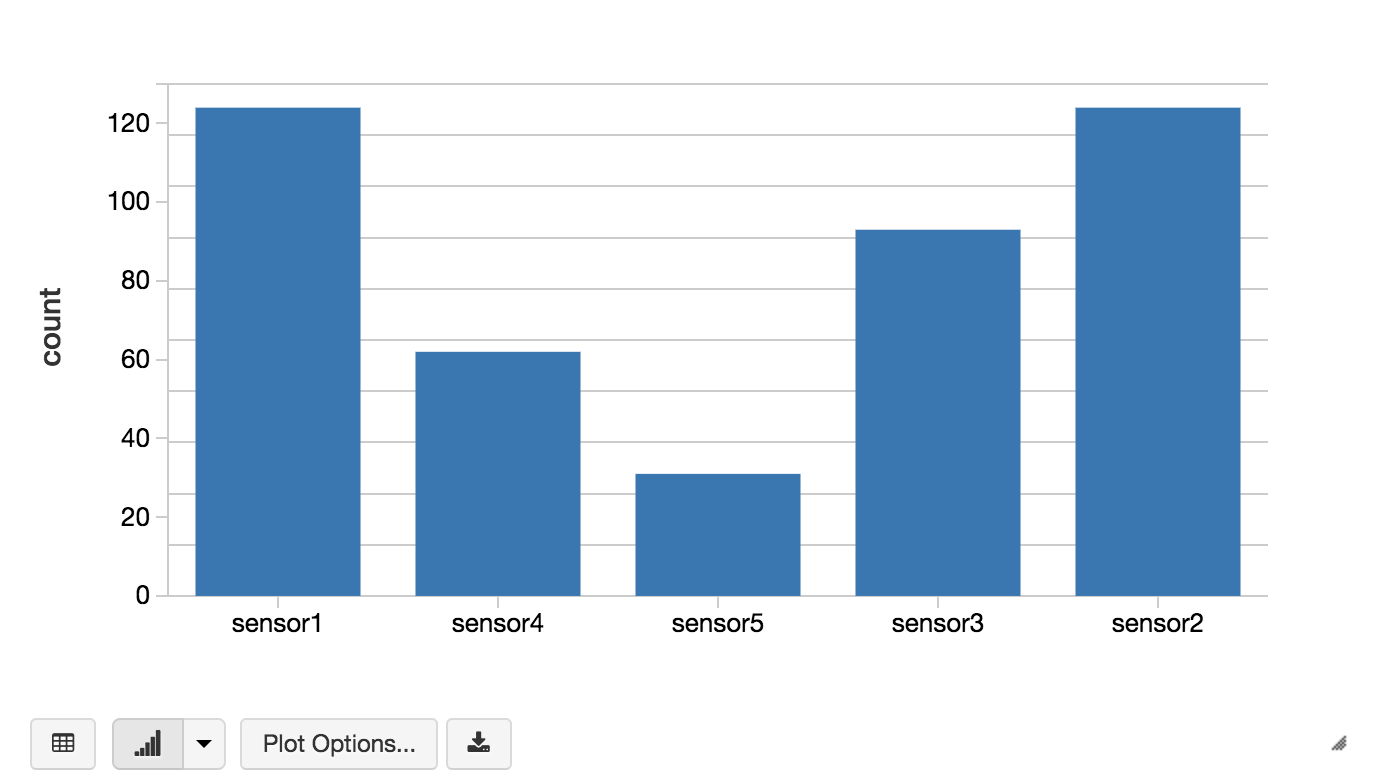
We also save the data as a Spark SQL table so we can query it using Spark SQL. For example, we can use the Databricks display command to view the table statistics of our damaged compressor table.

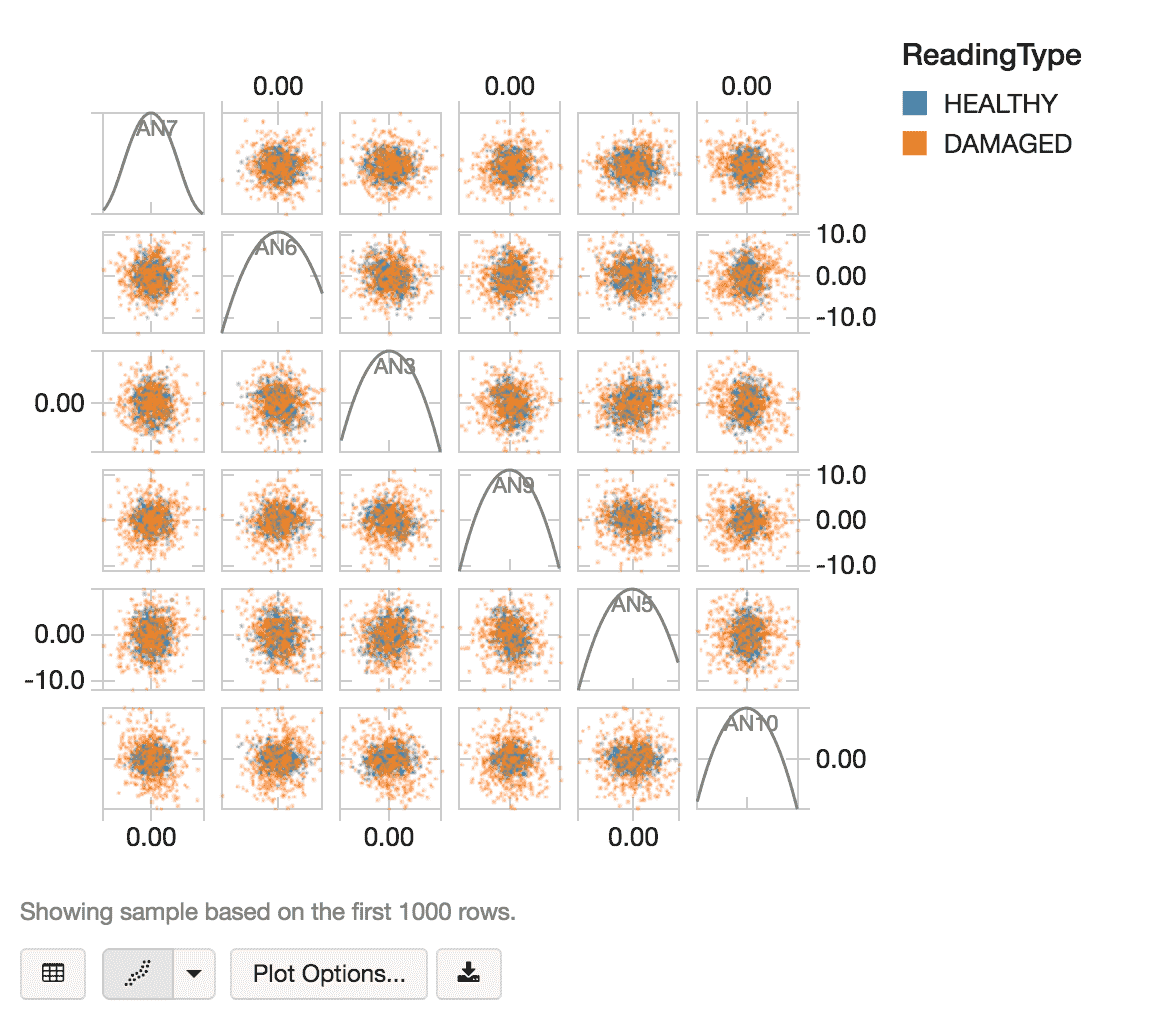
After taking a random sample of healthy and damaged data using the following code snippet:
we can use the Databricks display command to visualize our random sample of data using a scatter plot.
Building our Model
The next steps for implementing our predictive maintenance model is to create a K-Means model to cluster our datasets to predict damaged vs. healthy compressors. In addition to K-Means being a popular and well-understood clustering algorithm, there is also the benefit of using a streaming k-means model allowing us to easily execute the same model in batch and in streaming scenarios.
The first thing we want to do is to determine the optimal k value (i.e. optimal number of clusters). As we are currently identifying the difference between healthy and damaged, intuitively the value of k is 2 but let’s validate. As noted in the following code snippet, we will build an ML pipeline so we can easily re-use the model for our new dataset (i.e. the streaming dataset upstream). Our ML pipeline is relatively straightforward using VectorAssembler to define our features involving the Air and Noise columns (i.e. columns preceding with AN) and scaling it using MinMaxScaler.
Now that we have identified the optimal k value, we can now build our model with 2 clusters. The code snippet below creates our KMeans model (bestModel) against our healthy compressor data (prepData) and calculates the WSSSE (wssse).
We can quickly observe the difference between the healthy vs. damaged compressors via the WSSSE values by applying the damaged compressor data to the same ML pipeline and model.
Deploying the model using Streaming K-Means
While we have a potentially viable model to predict compressor failure, executing this model in real-time (vs. batch) allows us to build a continuous application that constantly receives asset sensor streams. We can now potentially predict compressor failure even earlier thus providing us more time to fix or replace the compressor prior to a catastrophic failure.
The following code snippet creates our Streaming KMeans model using the same bestK value for the setK property (i.e. 2 clusters). To dive deeper into the Streaming K-Means algorithm, refer to the MLlib Programming Guide > MLlib Clustering > Streaming K-Means.
Next we create our streaming function using the StreamingContext to calculate the WSSSE for each mini-batch.
With Streaming K-Means model and Spark Streaming function created, the following code snippet now starts our Spark Streaming context.
To persist our data, as noted in the Spark Streaming function, we have saved the timestamp and WSSSE values as JSON to DBFS (in this example, within /tmp/compressors). Files in DBFS persist to blob storage, so you won’t lose data even after you terminate a cluster. The following code snippet allows you to view the stream of WSSSE calculations by timestamp thus allowing you to predict the failure rate of your compressors as the sensor data is being received.
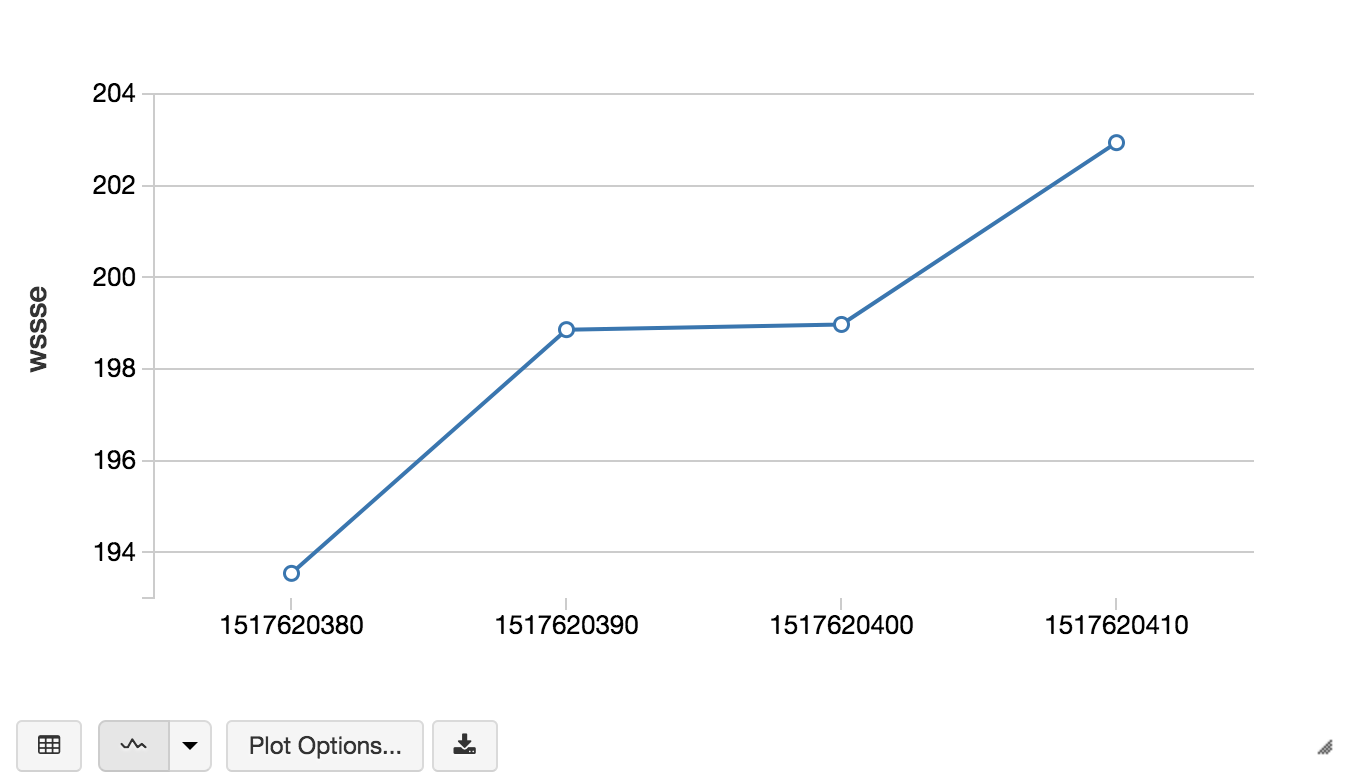
We can rely on Apache Spark Streaming to process all of our asset telemetries because it provides strong guarantees about system state: at any time, the output of the application is equivalent to executing a batch job on a prefix of the data. This consistency rule makes it easy to reason about past streaming challenges. Spark Streaming in Databricks provides the power of easily creating continuous applications, simplifying the maintenance of your streaming applications, and the power of the Databricks integrated workspace.
Re-train your model using a real-time database using Databricks Delta
While we have a viable Streaming K-Means model, it is very common to re-train our model as new rows and/or new attributes of data are received. A powerful option would be to create a real-time database that has the ability to store both your legacy (e.g. healthy and damaged compressor data) and new transactions as they are streaming in a consistent manner. To do this, we can use Databricks Delta which provides the performance and reliability of a data warehouse (for the large volumes of legacy compressor data) and the ability to allow for ‘real-time’ updates (for asset telemetry).
In the previous section, we created the table using saveAsTable instead we can use the USING DELTA option such as the following code snippet.
This Spark SQL statement creates a Databricks Delta table on which you can train and retrain your model that also provides:
- Ensure data integrity with transactional guarantees.
- Enable the most consistent view of your streaming writes.
- Accelerate query speeds through indexing and caching.
Summary
In this blog post, we demonstrated how you can implement predictive maintenance with the Databricks Unified Analytics Platform by combining Spark Streaming, machine learning, and Databricks Delta. Within a single notebook, you can read and write to a Kinesis stream, build a K-Means model within a ML pipeline, and apply a model to Spark Streaming so you can predict compressor failures as the data is received. With the Databricks Unified Analytics Platform you can remove the data engineering complexities commonly associated with such data pipelines and easily work with three different data paradigms - streaming, SQL, and machine learning - to potentially prevent failures for any of your assets.
Read More
For more information on Databricks Delta and Structured Streaming read these sources:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.