Announcing Databricks Runtime 4.3
I'm pleased to announce the release of Databricks Runtime 4.3, powered by Apache Spark. We've packed this release with an assortment of new features, performance improvements, and quality improvements to the platform. We recommend moving to Databricks Runtime 4.3 in order to take advantage of these improvements.
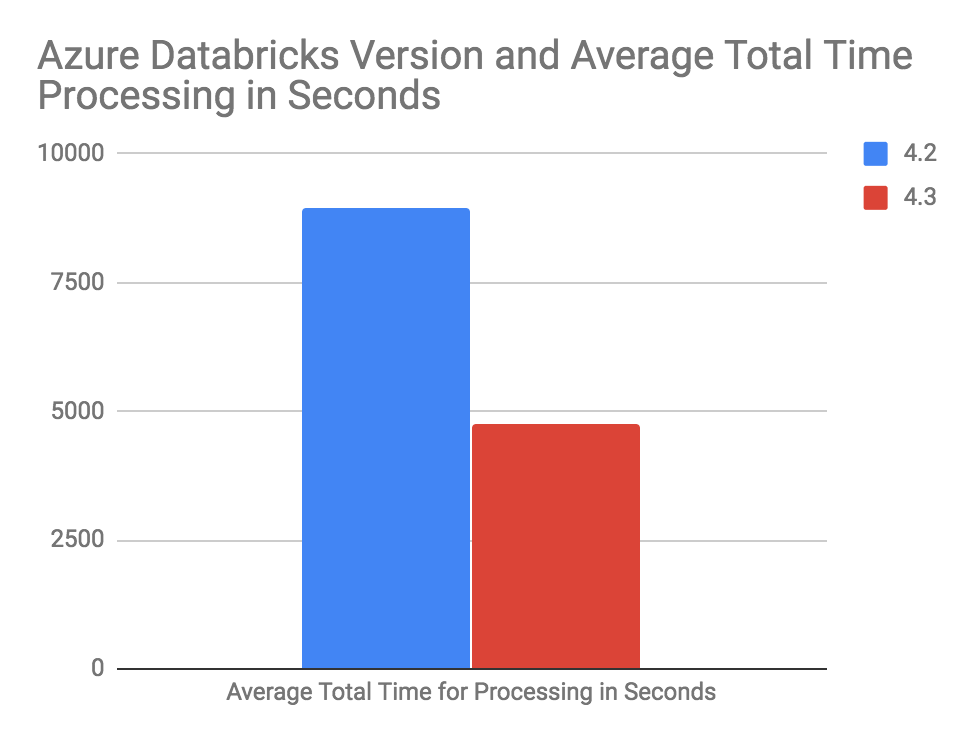
In our obsession to continually improve our platform’s performance, the Databricks Runtime 4.3 release benefits from substantial performance gains over previous versions of the Databricks Runtime. We have seen over 15% improvement in AWS with the performance improvements in 4.3. With improvements from DBIO caching to skip data more efficiently we’re experiencing over 55% performance improvements with TPC-DS at 1 Terabyte scale on Azure:
Find out more about the DBIO Caching capabilities in Azure Databricks premium SKU with Ls series VMs and how to enable caching with other VM types in Azure in the technical documentation.
In addition to the performance improvements, we've also added new functionality to Databricks Delta:
- Truncate Table: with Delta you can delete all rows in a table using truncate. It's important to note we do not support deleting specific partitions. Refer to the documentation for more information: Truncate Table
- Alter Table Replace columns: Replace columns in a Databricks Delta table, including changing the comment of a column, and we support reordering of multiple columns. Refer to the documentation for more information: Alter Table
- FSCK Repair Table: This command allows you to Remove the file entries from the transaction log of a Databricks Delta table that can no longer be found in the underlying file system. This can happen when these files have been manually deleted. Refer to the documentation for more information: Repair Table
- Scaling “Merge” Operations: This release comes with experimental support for larger source tables with “Merge” operations. Please contact support if you would like to try out this feature.
We’ve added great improvements to Structured Streaming that I’d also like to highlight:
- We now support streaming writes using the Azure SQL Data Warehouse Connector.
- Support for foreachBatch() in Python (already available in Scala). See foreach and foreachBatch documentation for more details.
- Changes to the watermark policy allow you to specify either a min or a max watermark when there are multiple input streams in a query instead of defaulting to the minimum timestamp. See the multiple watermark policy for more details.
To read more about the above new features and to see the full list of improvements included in Databricks Runtime 4.3, please refer to the release notes in the following locations:
- Amazon Web Services: Databricks Runtime 4.3 release notes
- Azure: Databricks Runtime 4.3 release notes
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.