Introducing Databricks Library Utilities for Notebooks
by Srinath Shankar and Todd Greenstein
Databricks has introduced a new feature, Library Utilities for Notebooks, as part of Databricks Runtime version 5.1. It allows you to install and manage Python dependencies from within a notebook. This provides several important benefits:
- Install libraries when and where they're needed, from within a notebook. This eliminates the need to globally install libraries on a cluster before you can attach a notebook that requires those libraries.
- Notebooks are completely portable between clusters (as long as they're running Databricks 5.1 or later, of course).
- Library environments are scoped to individual sessions. Multiple notebooks using different versions of a particular library can be attached to a cluster without interference.
- Different users on the same cluster can add and remove dependencies without affecting other users. You don't need to restart your cluster to reinstall libraries.
- When a notebook is detached, the session is garbage collected. Resources on the cluster for libraries installed during that session are released.
Let's take a closer look at how you can install libraries from within a notebook. It's as easy as it is flexible. All library management interaction from within a notebook uses Databricks Utilities (dbutils).
To demonstrate the power of this feature, I'm going to install SciPy version 1.2.0, a different version than is shipped with the version of the Databricks runtime I'm running on this cluster (DBR 5.1). You can install from DBFS (or S3 if you're using Databricks on AWS) as the file path, and we've included a convenience method for installing using PyPI.
First lets verify the installed version of SciPy on the cluster I've attached to.
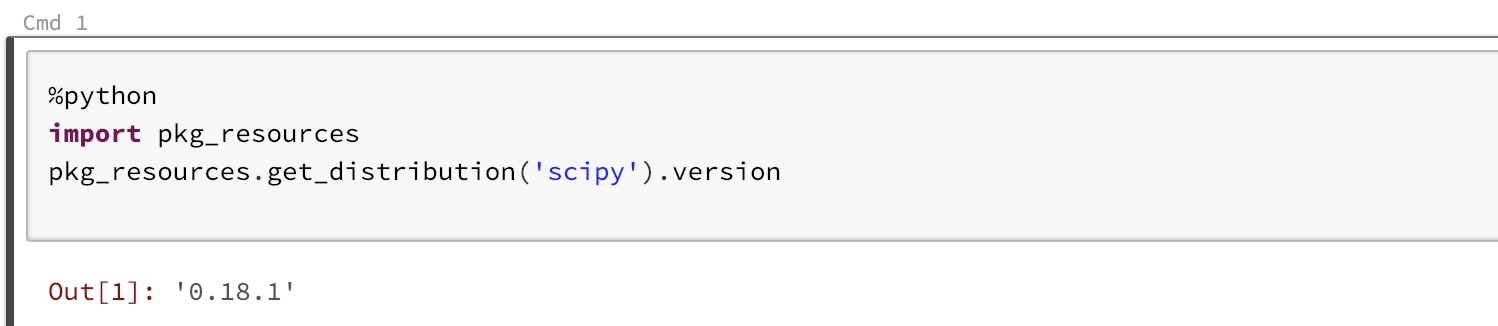
We can see the default version on this cluster of SciPy is 0.18.1. This is a cluster wide default. Any notebook that attaches to this cluster and imports SciPy will get this version. We have a helper function that lists any libraries installed and scoped specifically to our attached notebook session on this cluster. Lets run that now.

We can see that there are no libraries installed and scoped specifically to this notebook. Now I'm going to install a later version of SciPy, restart the python interpreter, and then run that same helper function we ran previously to list any libraries installed and scoped specifically to this notebook session. When using the list() function PyPI libraries scoped to this notebook session are displayed as

If you would like to reinstall a different version of a library, it is advisable to restart the Python interpreter. This must happen in a different cell before the newly-installed library can be used. Dbutils includes a convenience method to do this. All transient state in Python is lost when the interpreter is restarted. Now, when we import SciPy into this notebook, we can verify we are using the newer version.

Even with libraries that are prepackaged in the Databricks Runtime, the notebook-installed versions will always take precedence once the Python interpreter is restarted. These steps can be combined. For example, a cell in the top of your notebook can include installing all your notebook library dependencies along with a restart of the interpreter.
When I detach this notebook from the cluster, this notebook scoped environment will be garbage collected on the cluster. Notebook environments do not persist after detaching from the cluster. I can take this library to any cluster running Databricks Runtime 5.1 or newer and install my dependencies straight from within the notebook! In addition to being completely portable, different notebook sessions on the same cluster can utilize different versions of libraries without any interference.
Library Utilities for Notebooks is currently in preview as of Databricks Runtime 5.1. The documentation can be found
Azure: Library Utilities
AWS: Library Utilities
We look forward to hearing from you with any feedback or suggestions on how to improve this feature.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.