Efficient Upserts into Data Lakes with Databricks Delta
Simplify building big data pipelines for change data capture (CDC) and GDPR use cases.
Databricks Delta Lake, the next-generation engine built on top of Apache Spark™, now supports the MERGE command, which allows you to efficiently upsert and delete records in your data lakes. MERGE dramatically simplifies how a number of common data pipelines can be built; all the complicated multi-hop processes that inefficiently rewrote entire partitions can now be replaced by simple MERGE queries. This finer-grained update capability simplifies how you build your big data pipelines for various use cases ranging from change data capture to GDPR.
Need for upserts in various use cases
There are a number of common use cases where existing data in a data lake needs to be updated or deleted:
- General Data Protection Regulation (GDPR) compliance: With the introduction of the right to be forgotten (also known as data erasure) in GDPR, organizations must remove a user’s information upon request. This data erasure includes deleting user information in the data lakes as well.
- Change data capture from traditional databases: In a service-oriented architecture, typically web and mobile applications are served by microservices built on traditional SQL/NoSQL databases that are optimized for low latency. One of the biggest challenges organizations face is joining data across these various siloed data systems and hence data engineers build pipelines to consolidate all data sources into a central data lake to facilitate analytics. These pipelines often have to periodically read changes made on a traditional SQL/NoSQL table and apply them to corresponding tables in the data lake. Such changes can take various forms: table with slowly changing dimensions, change data capture of all inserted/updated/deleted rows, etc.
- Sessionization: Grouping multiple events into a single session is a common use case in many areas ranging from product analytics to targeted advertising to predictive maintenance. Building continuous applications to track sessions and recording the results that write into data lakes is difficult because data lakes have always been optimized for appending data.
- Deduplication: A common data pipeline use case is to collect system logs into a Databricks Delta table by appending data to the table. However, often the sources can generate duplicate records and downstream deduplication steps are needed to take care of them.
Challenges of upserts into data lakes
Since data lakes are fundamentally based on files, they have always been optimized for appending data than for changing existing data. Hence, building the above use case has always been challenging. Users typically read the entire table (or a subset of partitions) and then overwrite them. Therefore, every organization tries to reinvent the wheel for their requirement by hand-writing complicated queries in SQL, Spark, etc. This approach is:
- Inefficient: Reading and rewriting entire partitions (or entire tables) to update a few records causes pipelines to be slow and costly. Hand-tuning the table layout and query optimization is tedious and requires deep domain knowledge.
- Possibly incorrect: Hand-written code modifying data is very prone to logical and human errors. For example, multiple pipelines concurrently modifying the same table without any transactional support can lead to unpredictable data inconsistencies and in the worst case, data losses. Often, even a single hand-written pipeline can easily cause data corruptions due to errors in encoding the business logic.
- Hard to maintain: Fundamentally such hand-written code is hard to understand, keep track, and maintain. In the long term, this alone can significantly increase the organizational and infrastructural costs.
Introducing Merge in Databricks Delta
With Databricks Delta, you can easily address the use cases above without any of the aforementioned problems using the following MERGE command:
See our docs (Azure | AWS) for a more detailed explanation of the syntax.
Let’s understand how to use MERGE with a simple example. Suppose you have a slowly changing dimension table that maintains user information like addresses. Furthermore, you have a table of new addresses for both existing and new users. To merge all the new addresses to the main user table, you can run the following:
This will perform exactly what the syntax says - for existing users (i.e. MATCHED clause), it will update the address column, and for new users (i.e. NOT MATCHED clause) it will insert all the columns. For large tables with TBs of data, this Databricks Delta MERGE operation can be orders of magnitude faster than overwriting entire partitions or tables since Delta reads only relevant files and updates them. Specifically, Delta’s MERGE has the following advantages:
- Fine-grained: The operation rewrites data at the granularity of files and not partitions. This eliminates all the complications of rewriting partitions, updating the Hive metastore with MSCK, and so on.
- Efficient: Delta’s data skipping makes the MERGE efficient at finding files to rewrite thus eliminating the need to hand optimize your pipeline. Furthermore, Delta with all its I/O and processing optimizations makes all the reading and writing data by MERGE significantly faster than similar operations in Apache Spark.
- Transactional: Delta uses optimistic concurrency control to ensure that concurrent writers update the data correctly with ACID transactions, and concurrent readers always see a consistent snapshot of the data.
Here is a visual explanation of how MERGE compares with hand-written pipelines.
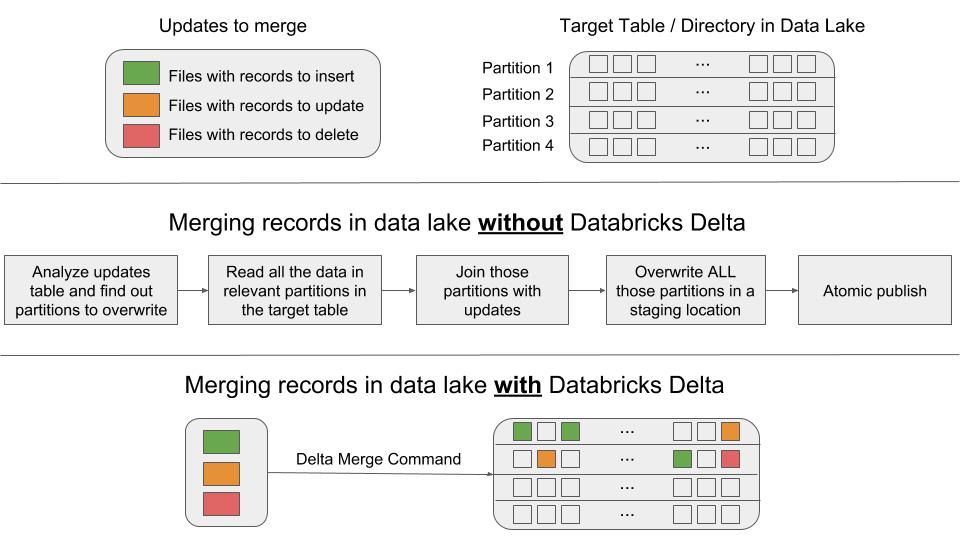
Figure showing the steps involved to merge records into data lake with and without Databricks Delta
Simplifying use cases with MERGE
Deleting data due to GDPR
Complying with the “right to be forgotten” clause of GDPR for data in data lakes cannot get easier. You can set up a simple scheduled job with an example code like below to delete all the users who have opted out of your service.
Applying change data from databases
You can easily apply all data changes - updates, deletes, inserts - generated from an external database into a Databricks Delta table with the MERGE syntax as follows:
Updating session information from streaming pipelines
If you have streaming event data flowing in and if you want to sessionize the streaming event data and incrementally update and store sessions in a Databricks Delta table, you can accomplish using the foreachBatch in Structured Streaming and MERGE. For example, suppose you have a Structured Streaming DataFrame that computes updated session information for each user. You can start a streaming query that applies all the sessions update to a Delta table as follows (Scala).
For a complete working example of foreachBatch and MERGE, see this notebook (Azure | AWS).
Conclusion
The fine-grained update capability in Databricks Delta simplifies how you build your big data pipelines. You no longer need to write complicated logic to overwrite tables and overcome a lack of snapshot isolation. With fine-grained updates, your pipelines will also be more efficient since you don’t need to read and overwrite entire tables. With changing data, another critical capability required is the ability to roll back in case of bad writes. Databricks Delta also offers rollback capabilities with the time travel feature, so that if you do a bad merge, you can easily roll back.
Read more (Azure | AWS) about the fine-grained updates feature. To see the feature in action, sign up for a free trial of Databricks and try it out.
Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.