Simplifying Streaming Stock Analysis using Delta Lake and Apache Spark: On-Demand Webinar and FAQ Now Available!
by John O'Dwyer, Navin Albert and Denny Lee
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
On June 13th, we hosted a live webinar — Simplifying Streaming Stock Analysis using Delta Lake and Apache Spark — with Junta Nakai, Industry Leader - Financial Services at Databricks, John O’Dwyer, Solution Architect at Databricks, and Denny Lee, Technical Product Marketing Manager at Databricks. This is the first webinar in a series of financial services webinars from Databricks and is an extension of the blog post Simplify Streaming Stock Data Analysis Using Delta Lake.

Analyzing trading and stock data? Traditionally, real-time analysis of stock data was a complicated endeavor due to the complexities of maintaining a streaming system and ensuring transactional consistency of legacy and streaming data concurrently. Delta Lake helps solve many of the pain points of building a streaming system to analyze stock data in real-time.
In this webinar, we will review:
- The current problems of running such a system.
- How Delta Lake addresses these problems.
- How to implement the system in Databricks.
Delta Lake helps solve these problems by combining the scalability, streaming, and access to advanced analytics of Apache Spark with the performance and ACID compliance of a data warehouse.
During the webinar, we showcased Streaming Stock Analysis with a Delta Lake notebook. To run it yourself, please download the following notebooks:
- Streaming Stock Analysis with Delta Lake: Setup - First run this notebook so it can automatically download the generated source data and starts loading data into a file location.
- Streaming Stock Analysis with Delta Lake - This is the main notebook that showcases Delta Lake within the context of streaming stock analysis including unified streaming, batch sync and time travel.
We also showcase the update of data in real-time with streaming and batch stock analysis data joined together as noted in the following image.
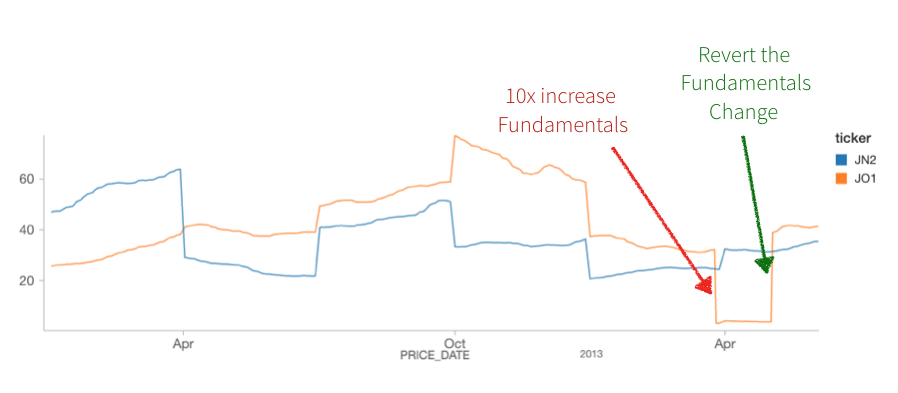
Toward the end, we also held a Q&A, and below are the questions and their answers.
Q: What is the difference between Delta Lake and Apache Parquet?
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads. While the Delta Lake stores data in Apache Parquet format, it includes features that allow data lakes to be reliable at scale. These features include:
- ACID Transactions: Delta Lake ensures data integrity and provides serializability.
- Scalable Metadata Handling: For Big Data systems, the metadata itself is often “big” enough to slow down any system that tries to make sense of it, let alone making sense of the actual underlying data. Delta Lake treats metadata like regular data and leverages Apache Spark’s distributed processing power. As a result, Delta Lake can handle petabyte-scale tables with billions of partitions and files at ease.
- Time Travel (data versioning): Creates snapshots of data, allowing you to access and revert to earlier versions of data for audits, rollbacks or to reproduce experiments.
- Open Format: All data in Delta Lake is stored in Apache Parquet format enabling Delta Lake to leverage the efficient compression and encoding schemes that are native to Parquet.
- Unified Batch and Streaming Source and Sink: A table in Delta Lake is both a batch table, as well as a streaming source and sink. Streaming data ingest, batch historic backfill, and interactive queries all just work out of the box.
- Schema Enforcement: Delta Lake provides the ability to specify your schema and enforce it. This helps ensure that the data types are correct and required columns are present, preventing bad data from causing data corruption.
- Schema Evolution: Big data is continuously changing. Delta Lake enables you to make changes to a table schema that can be applied automatically, without the need for cumbersome DDL.
- 100% Compatible with Apache Spark API: Developers can use Delta Lake with their existing data pipelines with minimal change as it is fully compatible with Spark, the commonly used big data processing engine.
Q: How can you view the Delta Lake table for both streaming and batch near the beginning of the notebook?
As noted in the Streaming Stock Analysis with Delta Lake notebook, in cell 8 we ran the following batch query:
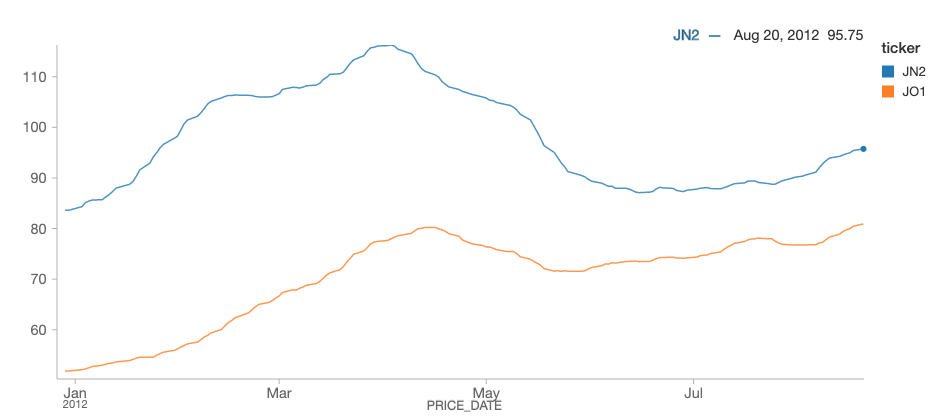
Notice that we ran this query earlier in the cycle with data up until August 20th, 2012. Using the same folder path (deltaPricePath), we also created a structured streaming DataFrame via the following code snippet in cell 4:
We can then run the following real-time Spark SQL query that will continuously refresh.
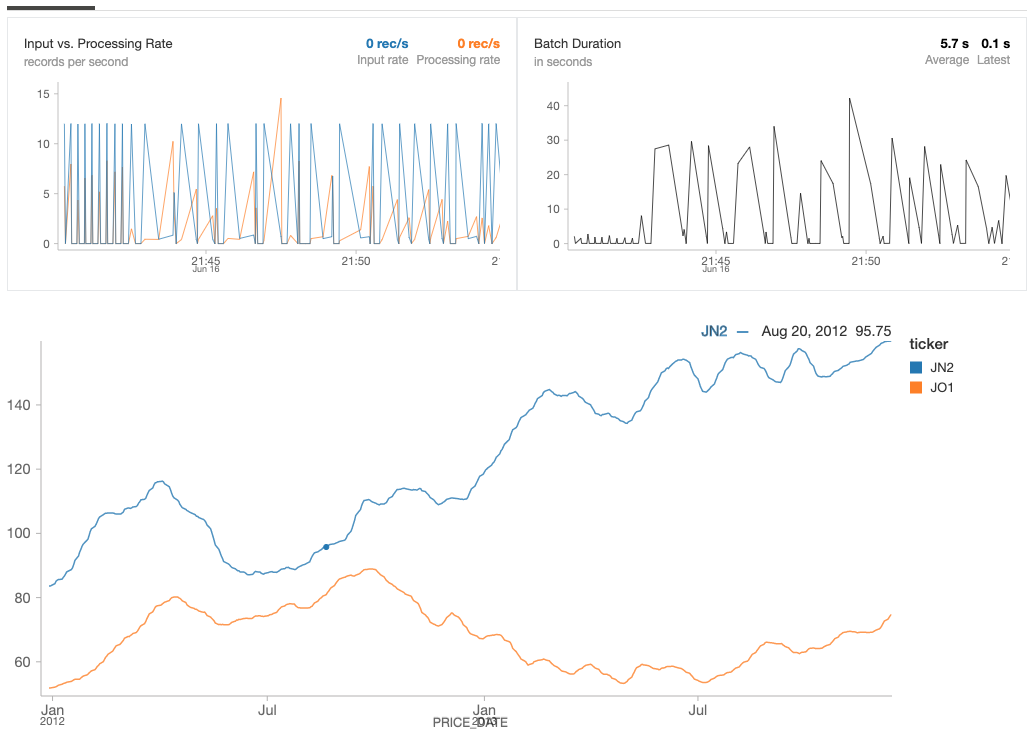
deltaPricePath.
Q: With the "mistake" that you had entered into the data, can I go back and find it and possibly correct it for auditing purposes?
Delta Lake has a data versioning feature called Time Travel. It provides snapshots of data, allowing you to access and revert to earlier versions of data for audits, rollbacks or to reproduce experiments. To visualize this, note cells 36 onwards in the Streaming Stock Analysis with Delta Lake notebook. The following screenshot shows three different queries using the VERSION AS OF syntax allowing you to view your data by version (or by timestamp using the TIMESTAMP syntax).
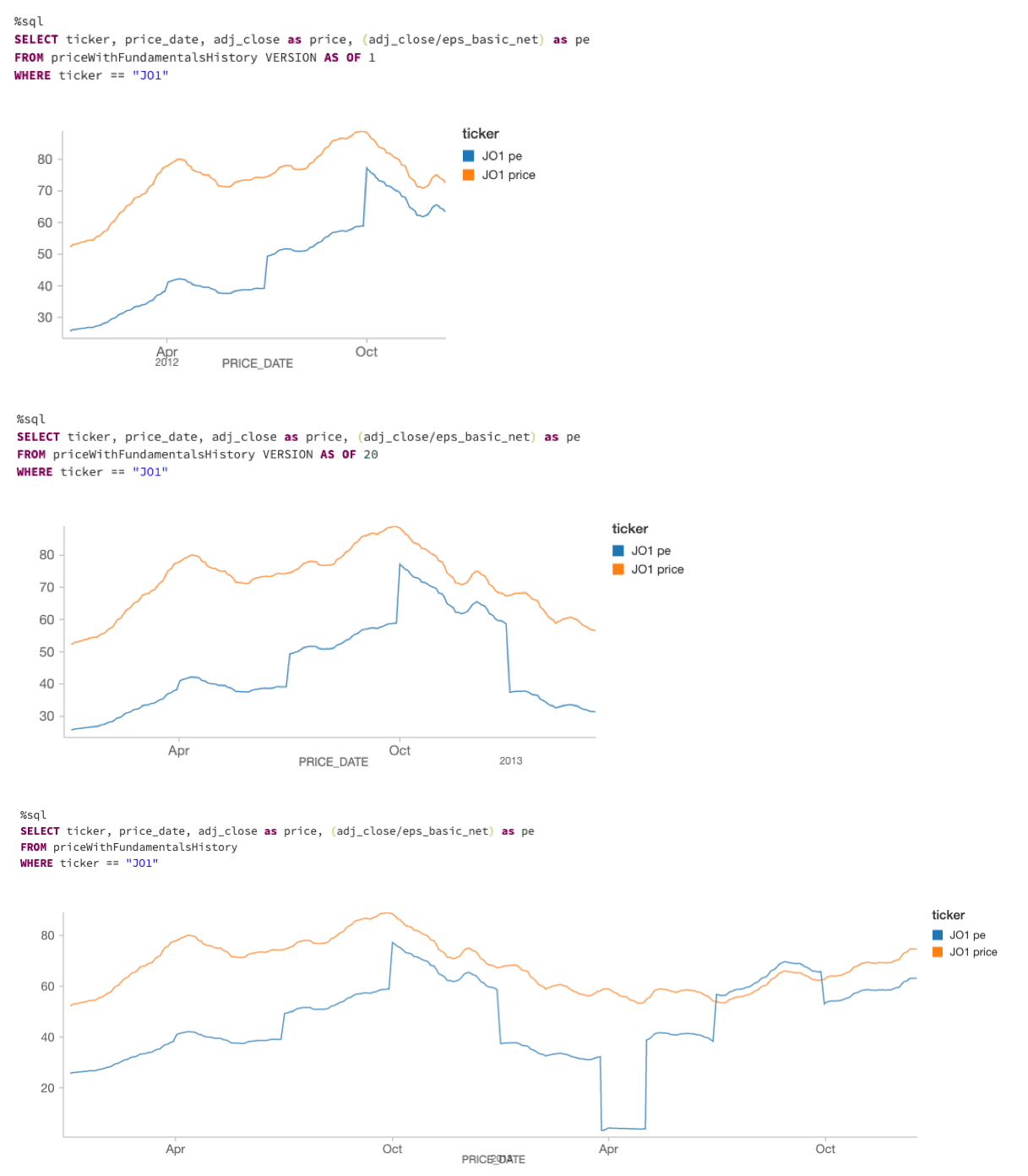
With this capability, you can know what changes to your data were made and when those transactions had occurred.
Q: I saw that the stock streaming data update was accomplished via a view; I wonder if updates can be done on actual data files themselves. For instance, do we need to refresh the whole partition parquet files to achieve updates? What is the solution under Delta Lake?
While the changes were done to a Spark SQL view, the changes are actually happening to the underlying files on storage. Delta Lake itself determines which Parquet files need to be updated to reflect the new changes.
Q: Can we query Delta Lake Tables in Apache Hive
Currently (as of version 0.1.0) it is not possible to query Delta Lake tables with Apache Hive nor is the Hive metastore supported (though this feature is on the roadmap). For the latest on this particular issue, please refer to the GitHub issue #18.
Q: Is there any guide that covers detailed usage of Delta Lake?
For the latest guidance on Delta Lake, please refer to the delta.io as well as the Delta Lake documentation. Join the Delta Lake Community to communicate with fellow Delta Lake users and contributors through our Slack channel or Google Groups.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.