New Methods for Improving Supply Chain Demand Forecasting
Fine-Grained Demand Forecasting with Causal Factors
by Bryan Smith and Rob Saker
Quick link to notebooks referenced through this post.
Organizations Are Rapidly Embracing Fine-Grained Demand Forecasting
Retailers and Consumer Goods manufacturers are increasingly seeking improvements to their supply chain management in order to reduce costs, free up working capital and create a foundation for omnichannel innovation. Changes in consumer purchasing behavior are placing new strains on the supply chain. Developing a better understanding of consumer demand via a demand forecast is considered a good starting point for most of these efforts as the demand for products and services drives decisions about the labor, inventory management, supply and production planning, freight and logistics and many other areas.
In Notes from the AI Frontier, McKinsey & Company highlight that, a 10 to 20% improvement in retail supply chain forecasting accuracy is likely to produce a 5% reduction in inventory costs and a 2 to 3% increase in revenues. Traditional supply chain forecasting tools have failed to deliver the desired results. With claims of industry-average inaccuracies of 32% in retailer supply chain demand forecasting, the potential impact of even modest forecasting improvements is immense for most retailers. As a result, many organizations are moving away from pre-packaged forecasting solutions, exploring ways to bring demand forecasting skills in-house and revisiting past practices which compromised forecast accuracy for computational efficiency.
A key focus of these efforts is the generation of forecasts at a finer level of temporal and (location/product) hierarchical granularity. Fine-grain demand forecasts have the potential to capture the patterns that influence demand closer to the level at which that demand must be met. Whereas in the past a retailer might have predicted short-term demand for a class of products at a market level or distribution level, for a month or week period, and then used the forecasted values to allocate units of a specific product in that class should be placed in a given store and day, fine-grain demand forecasting allows forecasters to build more localized models that reflect the dynamics of that specific product in a particular location.
Fine-grain Demand Forecasting Comes with Challenges
As exciting as fine-grain demand forecasting sounds, it comes with many challenges. First, by moving away from aggregate forecasts, the number of forecasting models and predictions which must be generated explodes. The level of processing required is either unattainable by existing forecasting tools, or it greatly exceeds the service windows for this information to be useful. This limitation leads to companies making tradeoffs in the number of categories being processed, or the level of grain in the analysis.
As examined in a prior blog post, Apache Spark can be employed to overcome this challenge, allowing modelers to parallelize the work for timely, efficient execution. When deployed on cloud-native platforms such as Databricks, computational resources can be quickly allocated and then released, keeping the cost of this work within budget.
The second and more difficult challenge to overcome is understanding that demand patterns that exist in aggregate may not be present when examining data at a finer level of granularity. To paraphrase Aristotle, the whole may often be greater than the sum of its parts. As we move to lower levels of detail in our analysis, patterns more easily modeled at higher levels of granularity may no longer be reliably present, making the generation of forecasts with techniques applicable at higher levels more challenging. This problem within the context of forecasting is noted by many practitioners going all the way back to Henri Theil in the 1950s.
As we move closer to the transaction level of granularity, we also need to consider the external causal factors that influence individual customer demand and purchase decisions. In aggregate, these may be reflected in the averages, trends and seasonality that make up a time series but at finer levels of granularity, we may need to incorporate these directly into our forecasting models.
Finally, moving to a finer level of granularity increases the likelihood the structure of our data will not allow for the use of traditional forecasting techniques. The closer we move to the transaction grain, the higher the likelihood we will need to address periods of inactivity in our data. At this level of granularity, our dependent variables, especially when dealing with count data such as units sold, may take on a skewed distribution that’s not amenable to simple transformations and which may require the use of forecasting techniques outside the comfort zone of many Data Scientists.
Accessing the Historical Data
See the Data Preparation notebook for details.
In order to examine these challenges, we will leverage public trip history data from the New York City Bike Share program, also known as Citi Bike NYC. Citi Bike NYC is a company that promises to help people, “Unlock a Bike. Unlock New York.” Their service allows people to go to any of over 850 various rental locations throughout the NYC area and rent bikes. The company has an inventory of over 13,000 bikes with plans to increase the number to 40,000. Citi Bike has well over 100,000 subscribers who make nearly 14,000 rides per day.
Citi Bike NYC reallocates bikes from where they were left to where they anticipate future demand. Citi Bike NYC has a challenge that is similar to what retailers and consumer goods companies deal with on a daily basis. How do we best predict demand to allocate resources to the right areas? If we underestimate demand, we miss revenue opportunities and potentially hurt customer sentiment. If we overestimate demand, we have excess bike inventory being unused.
This publicly available dataset provides information on each bicycle rental from the end of the prior month all the way back to the inception of the program in mid-2013. The trip history data identifies the exact time a bicycle is rented from a specific rental station and the time that bicycle is returned to another rental station. If we treat stations in the Citi Bike NYC program as store locations and consider the initiation of a rental as a transaction, we have something closely approximating a long and detailed transaction history with which we can produce forecasts.
As part of this exercise, we will need to identify external factors to incorporate into our modeling efforts. We will leverage both holiday events as well as historical (and predicted) weather data as external influencers. For the holiday dataset, we will simply identify standard holidays from 2013 to present using the holidays library in Python. For the weather data, we will employ hourly extracts from Visual Crossing, a popular weather data aggregator.
Citi Bike NYC and Visual Crossing data sets have terms and conditions that prohibit our directly sharing of their data. Those wishing to recreate our results should visit the data providers’ websites, review their Terms & Conditions, and download their datasets to their environments in an appropriate manner. We will provide the data preparation logic required to transform these raw data assets into the data objects used in our analysis.
Examining the Transactional Data
See the Exploratory Analysis notebook for details.
As of January 2020, the Citi Bike NYC bike share program consists of 864 active stations operating in the New York City metropolitan area, primarily in Manhattan. In 2019 alone, a little over 4-million unique rentals were initiated by customers with as many as nearly 14,000 rentals taking place on peak days.
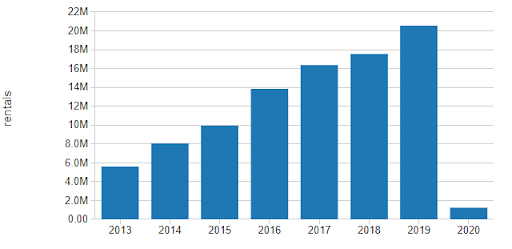
Since the start of the program, we can see the number of rentals has increased year over year. Some of this growth is likely due to the increased utilization of the bicycles, but much of it seems to be aligned with the expansion of the overall station network.
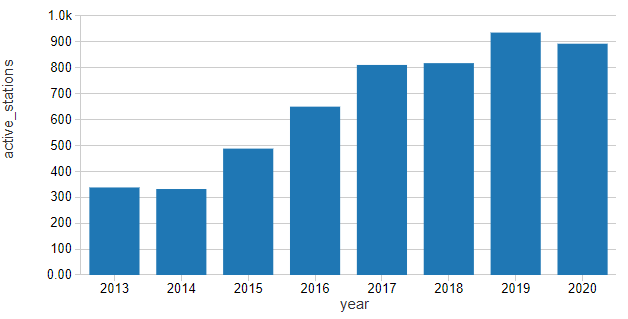
Normalizing rentals by the number of active stations in the network shows that growth in ridership on a per-station basis has been slowly ticking up for the last few years in what we might consider to be a slight linear upward trend.
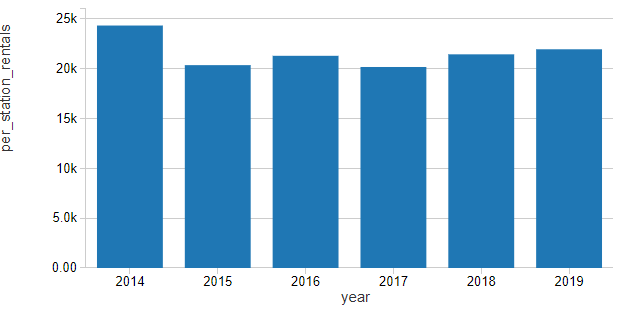
Using this normalized value for rentals, ridership seems to follow a distinctly seasonal pattern, rising in the Spring, Summer and Fall and then dropping in Winter as the weather outside becomes less conducive to bike riding
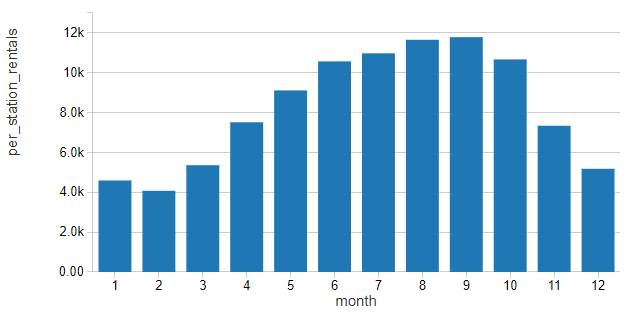
his pattern appears to closely follow patterns in the maximum temperatures (in degrees Fahrenheit) for the city.
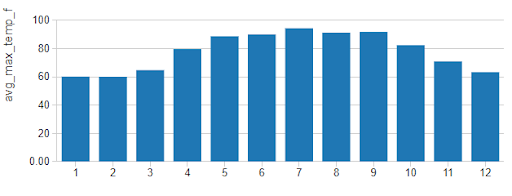
While it can be hard to separate monthly ridership from patterns in temperatures, rainfall (in average monthly inches) does not mirror these patterns quite so readily
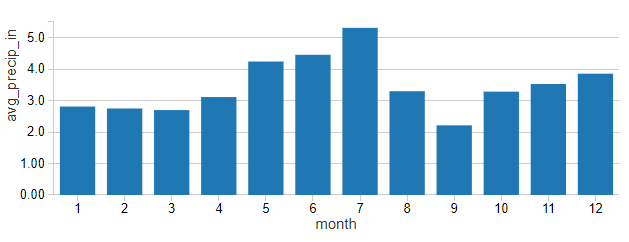
Examining weekly patterns of ridership with Sunday identified as 1 and Saturday identified as 7, it would appear that New Yorkers are using the bicycles as commuter devices, a pattern seen in many other bike share programs.
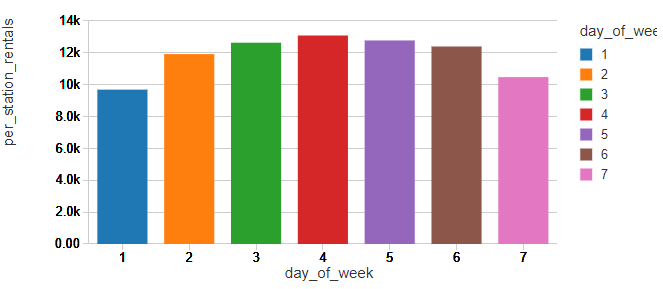
Breaking down these ridership patterns by hour of the day, we see distinct weekday patterns where ridership spikes during standard commute hours. On the weekends, patterns indicate more leisurely utilization of the program, supporting our earlier hypothesis.
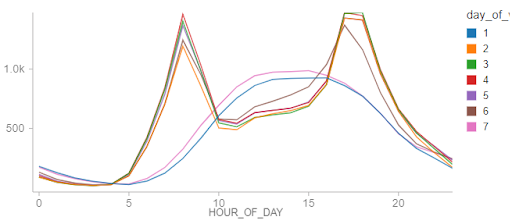
An interesting pattern is that holidays, regardless of their day of week, show consumption patterns that roughly mimic weekend usage patterns. The infrequent occurrence of holidays may be the cause of erraticism of these trends. Still, the chart seems to support that the identification of holidays is important to producing a reliable forecast.
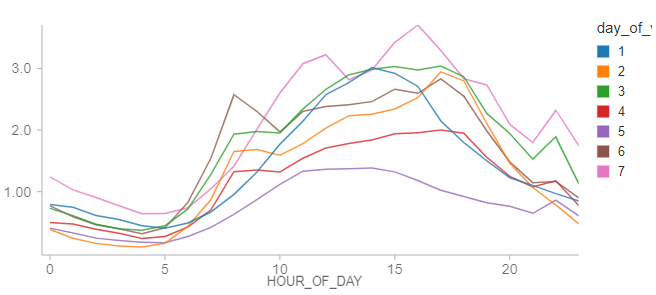
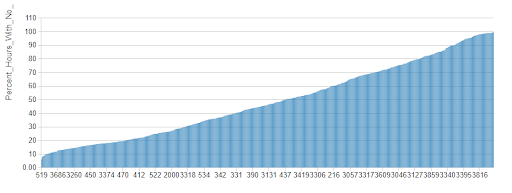
In aggregate, the hourly data appear to show that New York City is truly the city that never sleeps. In reality, there are many stations for which there are a large proportion of hours during which no bicycles are rented.
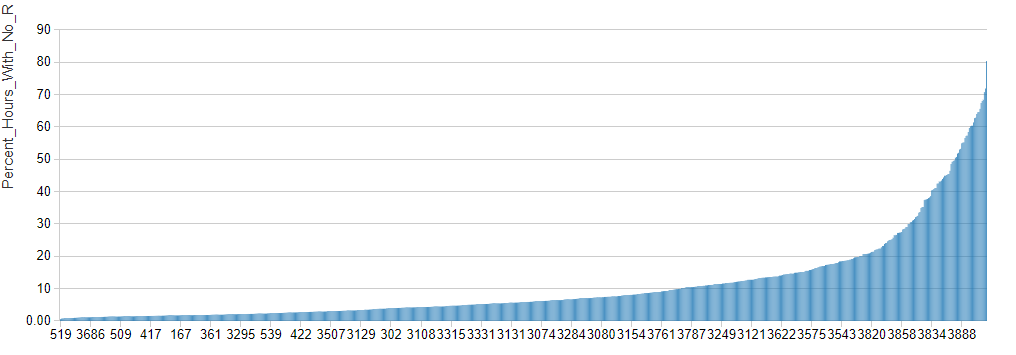
These gaps in activity can be problematic when attempting to generate a forecast. By moving from 1-hour to 4-hour intervals, the number of periods within which individual stations experience no rental activity drops considerably though there are still many stations that are inactive across this timeframe.
Instead of ducking the problem of inactive periods by moving towards even higher-levels of granularity, we will attempt to make a forecast at the hourly level, exploring how an alternative forecasting technique may help us deal with this dataset. As forecasting for stations that are largely inactive isn’t terribly interesting, we’ll limit our analysis to the top 200 most active stations.
Forecasting Bike Share Rentals with Facebook Prophet
In an initial attempt to forecast bike rentals at the per-station level, we made use of Facebook Prophet, a popular Python library for time series forecasting. The model was configured to explore a linear growth pattern with daily, weekly and yearly seasonal patterns. Periods in the dataset associated with holidays were also identified so that anomalous behavior on these dates would not affect the average, trend and seasonal patterns detected by the algorithm.
Using the scale-out pattern documented in the previously referenced blog post, models were trained for most active 200 stations and 36-hour forecasts were generated for each. Collectively, the models had a Root Mean Squared Error (RMSE) of 5.44 with a Mean Average Proportional Error (MAPE) of 0.73. (Zero-value actuals were adjusted to 1 for the MAPE calculation.)
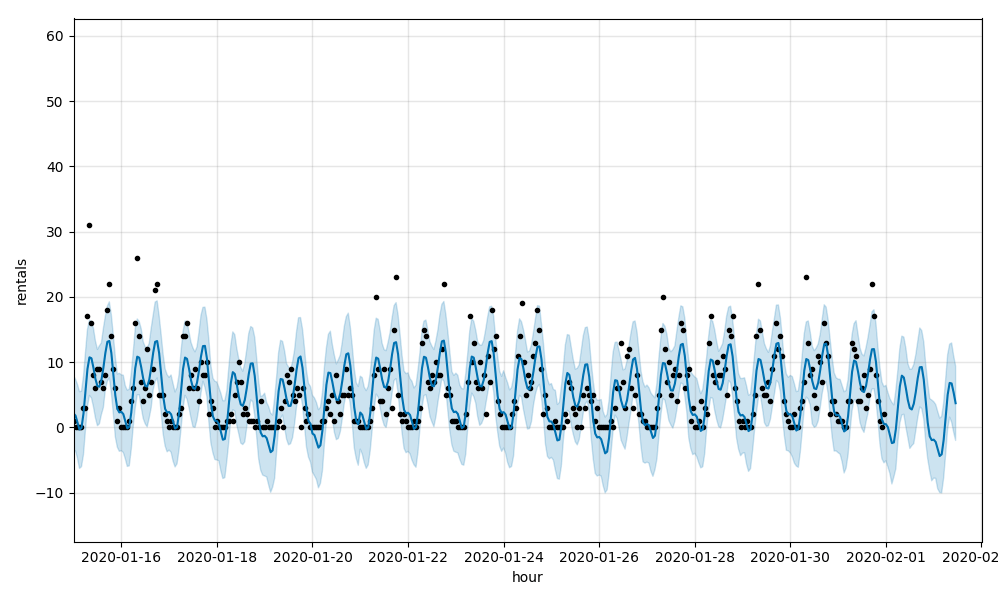
These metrics indicate that the models do a reasonably good job of predicting rentals but are missing when hourly rental rates move higher. Visualizing sales data for individual stations, you can see this graphically such as in this chart for Station 518, E 39 St & 2 Ave, which has an RMSE of 4.58 and a MAPE of 0.69:
See the Time Series notebook for details.
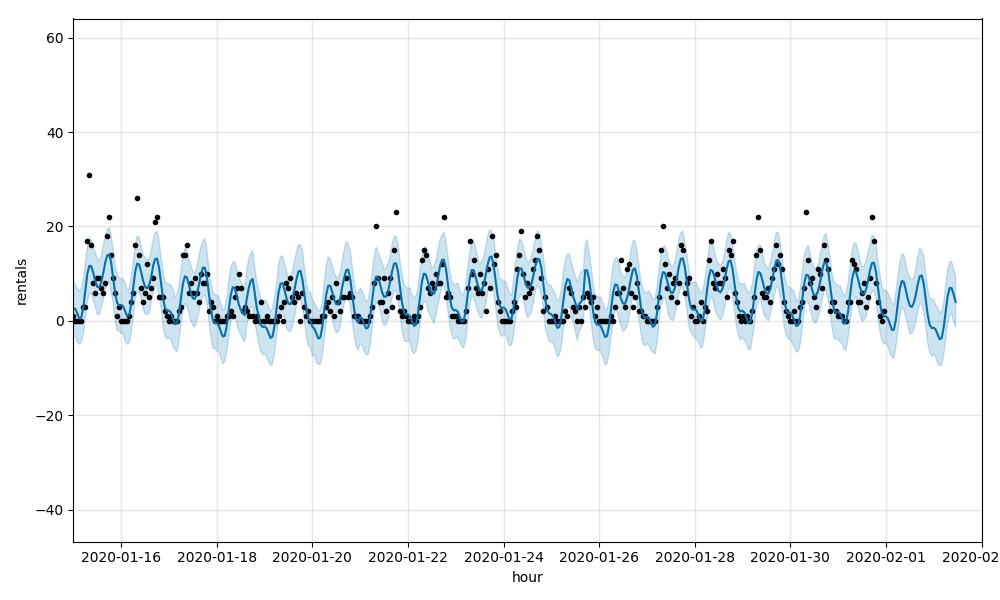
The model was then adjusted to incorporate temperature and precipitation as regressors. Collectively, the resulting forecasts had a RMSE of 5.35 and a MAPE of 0.72. While a very slight improvement, the models are still having difficulty picking up on the large swings in ridership found at the station level, as demonstrated again by Station 518 which had an RMSE of 4.51 and a MAPE of 0.68:
See the Time Series with Regressors notebook for details.
This pattern of difficulty modeling the higher values in both the time series models is typical of working with data having a Poisson distribution. In such a distribution, we will have a large number of values around an average with a long-tail of values above it. On the other side of the average, a floor of zero leaves the data skewed. Today, Facebook Prophet expects data to have a normal (Gaussian) distribution but plans for the incorporation of Poisson regression have been discussed.
Alternative Approaches to Forecasting Supply Chain Demand
How might we then proceed with generating a forecast for these data? One solution, as the caretakers of Facebook Prophet are considering, is to leverage Poisson regression capabilities in the context of a traditional time series model. While this may be an excellent approach, it is not widely documented so tackling this on our own before considering other techniques may not be the best approach for our needs.
Another potential solution is to model the scale of non-zero values and the frequency of the occurrence of the zero-valued periods. The output of each model can then be combined to assemble a forecast. This method, known as Croston’s method, is supported by the recently released croston Python library while another data scientist has implemented his own function for it. Still, this is not a widely adopted method (despite the technique dating back to the 1970s) and our preference is to explore something a bit more out-of-the-box.
Given this preference, a random forest regressor would seem to make quite a bit of sense. Decision trees, in general, do not impose the same constraints on data distribution as many statistical methods. The range of values for the predicted variable is such that it may make sense to transform rentals using something like a square root transformation before training the model, but even then, we might see how well the algorithm performs without it.
To leverage this model, we’ll need to engineer a few features. It’s clear from the exploratory analysis that there are strong seasonal patterns in the data, both at the annual, weekly and daily levels. This leads us to extract year, month, day of week and hour of the day as features. We may also include a flag for holiday.
Using a random forest regressor and nothing but time-derived features, we arrive at an overall RMSE of 3.4 and MAPE of 0.39. For Station 518, the RMSE and MAPE values are 3.09 and 0.38, respectively:
See Temporal Notebook for details.
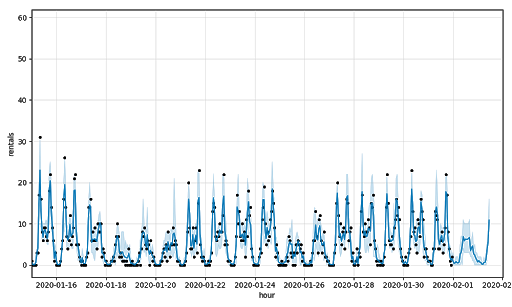
By leveraging precipitation and temperature data in combination with some of these same temporal features, we are able to better (though not perfectly) address some of the higher rental values. The RMSE for Station 518 drops to 2.14 and the MAPE to 0.26. Overall, the RMSE drops to 2.37 and MAPE to 0.26 indicating weather data is valuable in forecasting demand for bicycles.
See the Random Forest with Temporal & Weather Features notebook for details.
Implications of the Results
Demand forecasting at finer levels of granularity may require us to think differently about our approach to modeling. External influencers which may be safely considered summarized in high-level time series patterns may need to be more explicitly incorporated into our models. Patterns in data distribution hidden at the aggregate level may become more readily exposed and necessitate changes in modeling approaches. In this dataset, these challenges were best addressed by the inclusion of hourly weather data and a shift away from traditional time series techniques towards an algorithm which makes fewer assumptions about our input data.
There may be many other external influencers and algorithms worth exploring, and as we go down this path, we may find that some of these work better for some subset of our data than for others. We may also find that as new data arrives, techniques that previously worked well may need to be abandoned and new techniques considered.
A common pattern we are seeing with customers exploring fine-grain demand forecasting is the evaluation of multiple techniques with each training and forecasting cycle, something we might describe as an automated model bake-off. In a bake-off round, the model producing the best results for a given subset of the data wins the round with each subset able to decide its own winning model type. In the end, we want to ensure we are performing good Data Science where our data is properly aligned with the algorithms we employ, but as is noted in article after article, there isn’t always just one solution to a problem and some may work better at one time than at others. The power of what we have available today with platforms like Apache Spark and Databricks is that we have access to the computational capacity to explore all these paths and deliver the best solution to our business.
Additional Retail/CPG and Demand Forecasting Resources
- Sign-up for a free trial and download these notebooks to start experimenting:
- Download our Guide to Data Analytics and AI at Scale for Retail and CPG
- Visit our Retail and CPG page to learn how Dollar Shave Club and Zalando are innovating with Databricks
- Read our recent blog Fine-Grained Time Series Forecasting At Scale With Facebook Prophet And Apache Spark to learn how Databricks Unified Data Analytics Platform addresses challenges in a timely manner and at a level of granularity that allows the business to make precise adjustments to product inventories
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.