Faster SQL Queries on Delta Lake with Dynamic File Pruning
by Ali Afroozeh, Bogdan Ghit and Greg Rahn
There are two time-honored optimization techniques for making queries run faster in data systems: process data at a faster rate or simply process less data by skipping non-relevant data. This blog post introduces Dynamic File Pruning (DFP), a new data-skipping technique, which can significantly improve queries with selective joins on non-partition columns on tables in Delta Lake, now enabled by default in Databricks Runtime."
Check out the Why the Data Lakehouse is Your Next Data Warehouse ebook to discover the inner workings of the Databricks Lakehouse Platform.
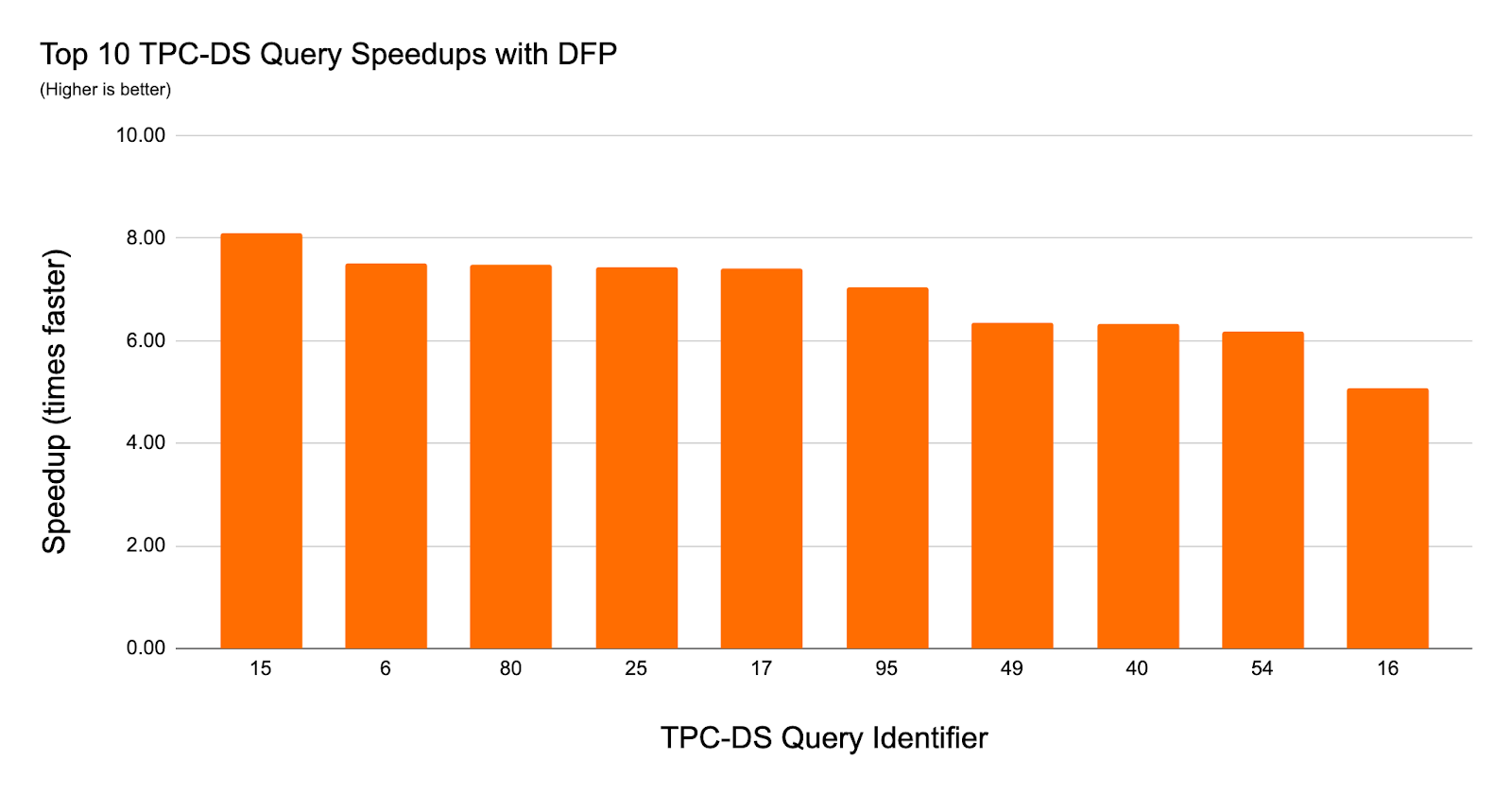
In our experiments using TPC-DS data and queries with Dynamic File Pruning, we observed up to an 8x speedup in query performance and 36 queries had a 2x or larger speedup.
The Benefits of Dynamic File Pruning
Data engineers frequently choose a partitioning strategy for large Delta Lake tables that allows the queries and jobs accessing those tables to skip considerable amounts of data thus significantly speeding up query execution times. Partition pruning can take place at query compilation time when queries include an explicit literal predicate on the partition key column or it can take place at runtime via Dynamic Partition Pruning.
Delta Lake on Databricks Performance Tuning
In addition to eliminating data at partition granularity, Delta Lake on Databricks dynamically skips unnecessary files when possible. This can be achieved because Delta Lake automatically collects metadata about data files managed by Delta Lake and so, data can be skipped without data file access. Prior to Dynamic File Pruning, file pruning only took place when queries contained a literal value in the predicate but now this works for both literal filters as well as join filters. This means that Dynamic File Pruning now allows star schema queries to take advantage of data skipping at file granularity.
| Per Partition | Per File (Delta Lake on Databricks only) | |
| Static (based on filters) | Partition Pruning | File Pruning |
| Dynamic (based on joins) | Dynamic Partition Pruning | Dynamic File Pruning (NEW!) |
How Does Dynamic File Pruning Work?
Before we dive into the details of how Dynamic File Pruning works, let's briefly present how file pruning works with literal predicates.
Example 1 - Static File Pruning
For simplicity, let's consider the following query derived from the TPC-DS schema to explain how file pruning can reduce the size of the SCAN operation.
Delta Lake stores the minimum and maximum values for each column on a per file basis. Therefore, files in which the filtered values (40, 41, 42) fall outside the min-max range of the ss_item_sk column can be skipped entirely. We can reduce the length of value ranges per file by using data clustering techniques such as Z-Ordering. This is very attractive for Dynamic File Pruning because having tighter ranges per file results in better skipping effectiveness. Therefore, we have Z-ordered the store_sales table by the ss_item_sk column.
In query Q1 the predicate pushdown takes place and thus file pruning happens as a metadata-operation as part of the SCAN operator but is also followed by a FILTER operation to remove any remaining non-matching rows.

When the filter contains literal predicates, the query compiler can embed these literal values in the query plan. However, when predicates are specified as part of a join, as is commonly found in most data warehouse queries (e.g., star schema join), a different approach is needed. In such cases, the join filters on the fact table are unknown at query compilation time.
Example 2 - Star Schema Join without DFP
Below is an example of a query with a typical star schema join.
Query Q2 returns the same results as Q1, however, it specifies the predicate on the dimension table (item), not the fact table (store_sales). This means that filtering of rows for store_sales would typically be done as part of the JOIN operation since the values of ss_item_sk are not known until after the SCAN and FILTER operations take place on the item table.
Below is a logical query execution plan for Q2.
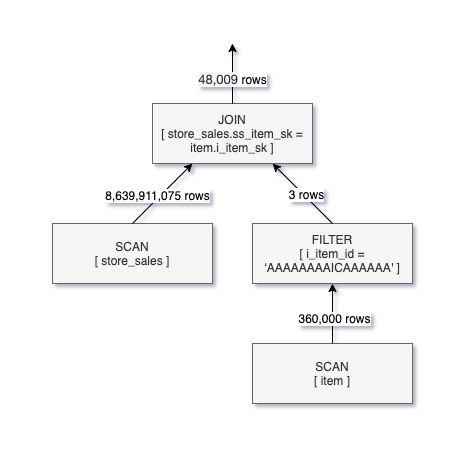
As you can see in the query plan for Q2, only 48K rows meet the JOIN criteria yet over 8.6B records had to be read from the store_sales table. This means that the query runtime can be significantly reduced as well as the amount of data scanned if there was a way to push down the JOIN filter into the SCAN of store_sales.
Example 3 - Star Schema Join with Dynamic File Pruning
If we take Q2 and enable Dynamic File Pruning we can see that a dynamic filter is created from the build side of the join and passed into the SCAN operation for store_sales. The below logical plan diagram represents this optimization.
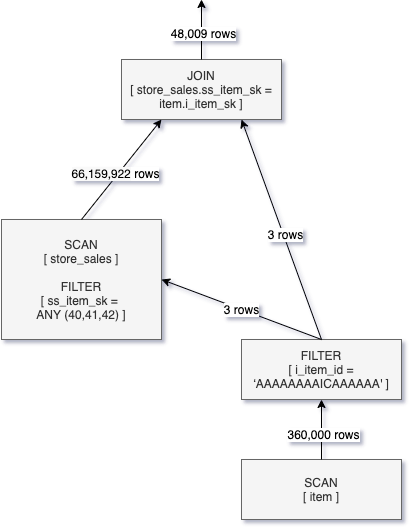
The result of applying Dynamic File Pruning in the SCAN operation for store_sales is that the number of scanned rows has been reduced from 8.6 billion to 66 million rows. Whereas the improvement is significant, we still read more data than needed because DFP operates at the granularity of files instead of rows.
We can observe the impact of Dynamic File Pruning by looking at the DAG from the Spark UI (snippets below) for this query and expanding the SCAN operation for the store_sales table. In particular, using Dynamic File Pruning in this query eliminates more than 99% of the input data which improves the query runtime from 10s to less than 1s.

Without dynamic file pruning
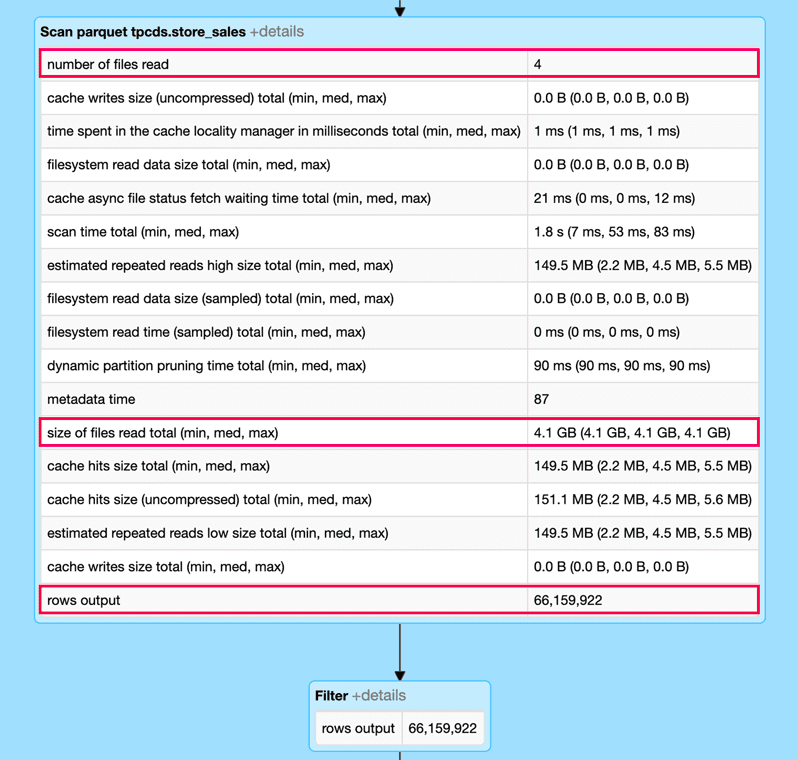
With dynamic file pruning
Enabling Dynamic File Pruning
DFP is automatically enabled in Databricks Runtime 6.1 and higher, and applies if a query meets the following criteria:
- The inner table (probe side) being joined is in Delta Lake format
- The join type is INNER or LEFT-SEMI
- The join strategy is BROADCAST HASH JOIN
- The number of files in the inner table is greater than the value for spark.databricks.optimizer.deltaTableFilesThreshold
DFP can be controlled by the following configuration parameters:
- spark.databricks.optimizer.dynamicFilePruning (default is true) is the main flag that enables the optimizer to push down DFP filters.
- spark.databricks.optimizer.deltaTableSizeThreshold (default is 10GB) This parameter represents the minimum size in bytes of the Delta table on the probe side of the join required to trigger dynamic file pruning.
- spark.databricks.optimizer.deltaTableFilesThreshold (default is 1000) This parameter represents the number of files of the Delta table on the probe side of the join required to trigger dynamic file pruning.
Note: In the experiments reported in this article we set spark.databricks.optimizer.deltaTableFilesThreshold to 100 in order to trigger DFP because the store_sales table has less than 1000 files
Experiments and Results with TPC-DS
To understand the impact of Dynamic File Pruning on SQL workloads we compared the performance of TPC-DS queries on unpartitioned schemas from a 1TB dataset. We used Z-Ordering to cluster the joined fact tables on the date and item key columns. DFP delivers good performance in nearly every query. In 36 out of 103 queries we observed a speedup of over 2x with the largest speedup achieved for a single query of roughly 8x. The chart below highlights the impact of DFP by showing the top 10 most improved queries.
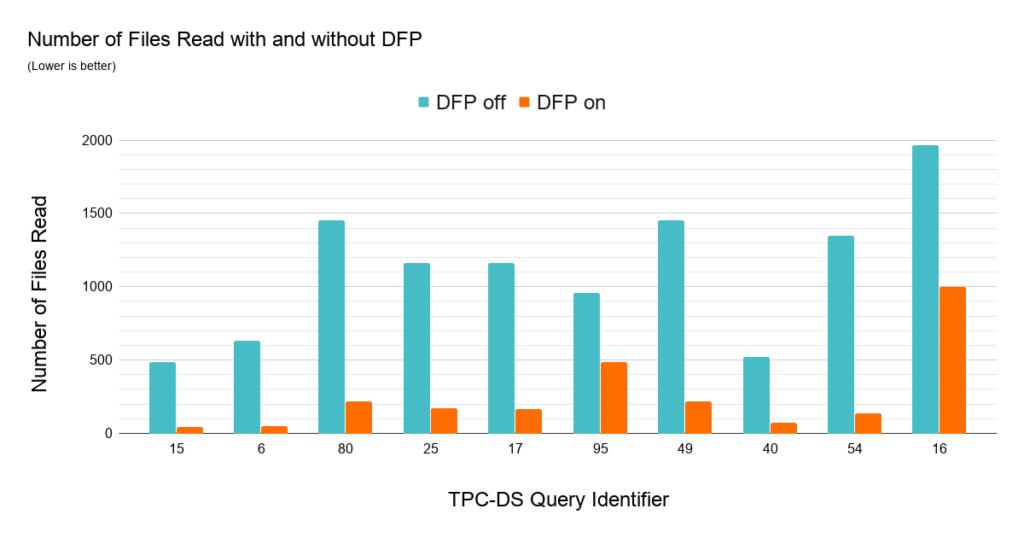
Many TPC-DS queries use a typical star schema join between a date dimension table and a fact table (or multiple fact tables) to filter date ranges which makes it a great workload to showcase the impact of DFP. The data presented in the above chart explains why DFP is so effective for this set of queries -- they are now able to reduce a significant amount of data read. Each query has a join filter on the fact tables limiting the period of time to a range between 30 and 90 days (fact tables store 5 years of data). DFP is very attractive for this workload as some of the queries may access up to three fact tables.
Getting Started with Dynamic File Pruning
Dynamic File Pruning (DFP), a new feature now enabled by default in Databricks Runtime, can significantly improve the performance of many queries on Delta Lake. DFP is especially efficient when running join queries on non-partitioned tables. The better performance provided by DFP is often correlated to the clustering of data and so, users may consider using Z-Ordering to maximize the benefit of DFP. To leverage these latest performance optimizations, sign up for a Databricks account today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.