Simplify Python environment management on Databricks Runtime for Machine Learning using %pip and %conda
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Today we announce the release of %pip and %conda notebook magic commands to significantly simplify python environment management in Databricks Runtime for Machine Learning. With the new magic commands, you can manage Python package dependencies within a notebook scope using familiar pip and conda syntax. For example, you can run %pip install -U koalas in a Python notebook to install the latest koalas release. The change only impacts the current notebook session and associated Spark jobs. With simplified environment management, you can save time in testing different libraries and versions and spend more time applying them to solve business problems and making your organization successful.
Why We Are Introducing This Feature
Enable %pip and %conda magic commands
Adding Python packages to a notebook session
Managing notebook-scoped environments
Reproducing environments across notebooks
Best Practices & Limitations
Future Plan
Why We Are Introducing This Feature
Managing Python library dependencies is one of the most frustrating tasks for data scientists. Library conflicts significantly impede the productivity of data scientists, as it prevents them from getting started quickly. Oftentimes the person responsible for providing an environment is not the same person who will ultimately perform development tasks using that environment. In some organizations, data scientists need to file a ticket to a different department (ie IT, Data Engineering), further delaying resolution time.
Databricks Runtime for Machine Learning (aka Databricks Runtime ML) pre-installs the most popular ML libraries and resolves any conflicts associated with pre packaging these dependencies. The feedback has been overwhelmingly positive evident by the rapid adoption among Databricks customers. However, ML is a rapidly evolving field, and new packages are being introduced and updated frequently. Databricks users often want to customize their environments further by installing additional packages on top of the pre-configured packages or upgrading/downgrading pre-configured packages. It’s important to note that environment changes need to be propagated to all nodes within a cluster before it can be leveraged by the user.
Improving dependency management within Databricks Runtime ML has three primary use cases:
- Use familiar pip and conda commands to customize Python environments and handle dependency management.
- Make environment changes scoped to a notebook session and propagate session dependency changes across cluster nodes.
- Enable better notebook transportability.
Enable %pip and %conda magic commands
Starting with Databricks Runtime ML version 6.4 this feature can be enabled when creating a cluster. To perform this set spark.databricks.conda.condaMagic.enabled to true under “Spark Config” (Edit > Advanced Options > Spark). See Figure 1.
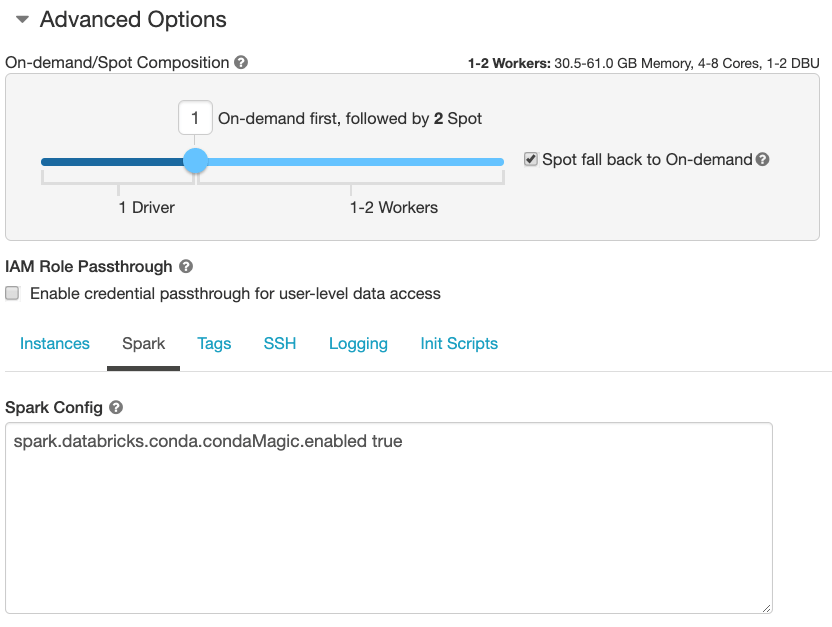
After the cluster has started, you can simply attach a Python notebook and start using %pip and %conda magic commands within Databricks!
Note: This feature is not yet available in PVC deployments and Databricks Community Edition.
Adding Python packages to a notebook session
If you want to add additional libraries or change the versions of pre-installed libraries, you can use %pip install. For example, the following command line adds koalas 0.32.0 to the Python environment scoped to the notebook session:
%pip install koalas==0.32.0
Pinning the version is highly recommended for reproducibility. The change only impacts the current notebook session, i.e., other notebooks connected to this same cluster won’t be affected. The installed libraries will be available on the driver node as well as on all the worker nodes of the cluster in Databricks for your PySpark jobs launched from the notebook.
Databricks recommends using %pip if it works for your package. If the package you want to install is distributed via conda, you can use %conda instead. For example, the following command upgrades Intel MKL to the latest version:
%conda update mkl
The notebook session restarts after installation to ensure that the newly installed libraries can be successfully loaded. To best facilitate easily transportable notebooks, Databricks recommends putting %pip and %conda commands at the top of your notebook.
Managing notebook-scoped environments
In Databricks Runtime ML, the notebook-scoped environments are managed by conda. You can use %conda list to inspect the Python environment associated with the notebook.
%conda list.
Conda provides several advantages for managing Python dependencies and environments within Databricks:
- Environment and dependency management are handled seamlessly by the same tool.
- Conda environments support both pip and conda to install packages.
- Conda’s powerful import/export functionality makes it the ideal package manager for data scientists.
Through conda, Notebook-scoped environments are ephemeral to the notebook session. So if a library installation goes away or dependencies become messy, you can always reset the environment to the default one provided by Databricks Runtime ML and start again by detaching and reattaching the notebook.
For advanced conda users, you can use %conda config to change the configuration of the notebook-scoped environment, e.g., to add channels or to config proxy servers.
Reproducing environments across notebooks
For a team of data scientists, easy collaboration is one of the key reasons for adopting a cloud-based solution. The %conda magic command makes it easy to replicate Python dependencies from one notebook to another.
You can use %conda env export -f /dbfs/path/to/env.yml to export the notebook environment specifications as a yaml file to a designated location. Figure 4 saves the yaml file to a DBFS folder using its local file interface:

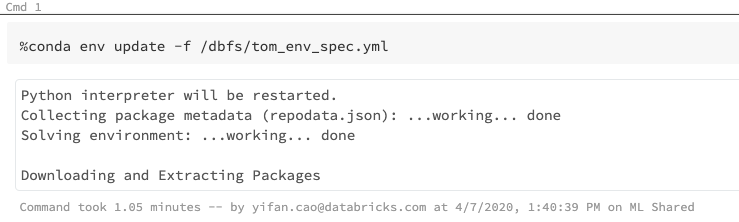
A different user can import the yaml file in her notebook by using %conda env update -f. By doing so, she will be installing all the libraries and dependencies from the yaml file to her current notebook session. See Figure 5.
Databricks recommends using the same Databricks Runtime version to export and import the environment file for better compatibility.
Best Practices & Limitations
Databricks does not recommend users to use %sh pip/conda install in Databricks Runtime ML. %sh commands might not change the notebook-scoped environment and it might change the driver node only. It’s not a stable way to interface with dependency management from within a notebook.
As discussed above, libraries installed via %conda commands are “ephemeral”, and the notebook will revert back to the default environment after it is detached and reattached to the cluster. If you need some libraries that are always available on the cluster, you can install them in an init script or using a docker container. Libraries installed via Databricks Library UI/APIs (supports only pip packages will also be available across all notebooks on the cluster that are attached after library installation. Conda package installation is currently not available in Library UI/API.
Currently, %conda activate and %conda env create are not supported. We are actively working on making these features available.
Future Plans
We introduced dbutils.library.* APIs in Databricks Runtime to install libraries scoped to a notebook, but it is not available in Databricks Runtime ML. Conversely, this new %conda/%pip feature is only available in Databricks Runtime ML, but not in Databricks Runtime. Our long-term goal is to unify the two experiences with a minimal-effort migration path. We will be starting by bringing %pip to the Databricks Runtime, soon.
We introduced Databricks Runtime with Conda (Beta) in the past. This Runtime is meant to be experimental. With the new %pip and %conda feature now available in Databricks Runtime for ML, we recommend users running workloads in Databricks Runtime with Conda (Beta) to migrate to Databricks Runtime for ML. We do not plan to make any more releases of Databricks Runtime with Conda (Beta).
As discussed above, we are actively working on making additional Conda commands available in ML Runtime, most notably %conda activate and %conda env create. For a complete list of available or unavailable Conda commands, please refer to our Documentation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.