Announcing MLflow Model Serving on Databricks
by Aaron Davidson, Tomas Nykodym, Clemens Mewald and Cyrielle Simeone
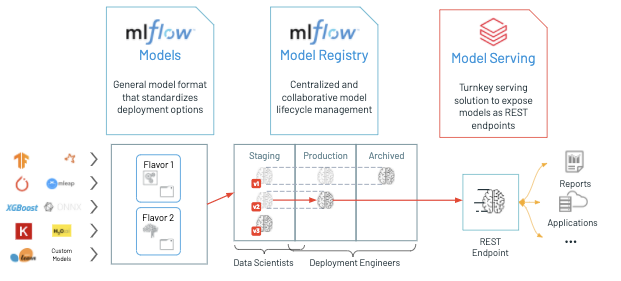
Databricks MLflow Model Serving provides a turnkey solution to host machine learning (ML) models as REST endpoints that are updated automatically, enabling data science teams to own the end-to-end lifecycle of a real-time machine learning model from training to production.
When it comes to deploying ML models, data scientists have to make a choice based on their use case. If they need a high volume of predictions and latency is not an issue, they typically perform inference in batch, feeding the model with large amounts of data and writing the predictions into a table. If they need predictions at low latency, e.g. in response to a user action in an app, the best practice is to deploy ML models as REST endpoints. This allows apps to send requests to an endpoint that’s always up and receive the prediction immediately.
On Databricks, we have already simplified the workflow of deploying ML models in a batch or streaming fashion to big data, using MLflow's spark_udf. For situations that require deploying models in a real-time fashion, we are introducing Databricks MLflow Model Serving: a new turnkey service that simplifies both the workflow of initially deploying a model and also of keeping it updated. Databricks MLflow Model Serving ties directly into the MLflow Model Registry to automatically deploy new versions of a model and route requests to them, making it easy for ML developers to directly manage which models they are serving.
Watch Spark + AI Summit Keynotes here
Serving models
Today, serving models can be complex because it requires running a separate serving system, such as Kubernetes, which ML developers might not have access to. Moreover, developers must be careful to update the versions of the model used there as they design new models, and route requests to the right model.
Databricks MLflow Model Serving solves this issue by integrating with the Model Registry. The model registry can store models from all machine learning libraries (TensorFlow, scikit-learn, etc), and lets you store multiple versions of a model, review them, and promote them to different lifecycle stages such as Staging and Production. Model Serving makes use of these stages; you can make the latest production model available at "/model/
Once Model Serving is enabled, a Databricks cluster launches, which hosts all active model versions associated with the registered model as REST endpoints. Each model runs in a conda environment that reflects the environment it was trained with.
Once the endpoint is running, you can test queries from the Databricks UI, or submit them yourself using the REST API. We also integrate with the recently released model schema and examples (available in MLflow 1.9 to allow annotating models with their schema and example inputs) to make it even easier and safer to test out your served model.
https://www.youtube.com/watch?v=IVS2PyoQN0M
The same request can be sent through the REST API using standard Databricks authentication, for example using curl:
Note that the URL contains "Production", meaning that this is a stable URL that points to the latest Production version. You can also directly reference a model version by number, if you want to lock your application to a specific version (for example "/model/model_with_example/1").
Evolving your model
Many use cases start with an initial model as a proof-of-concept, but in the course of model development, data scientists often iterate and produce newer and better versions of models. Model Serving makes this process as easy as possible.
Suppose you have Version 1 of your model in production, and are ready to try out and release the next version. You first register the second model in the Model Registry and promote it to "Staging", indicating that you want to test it out a bit more before replacing your Production version.
Since the model has model serving enabled, new model versions are automatically launched onto the existing cluster as they're added. You can see below that you have both versions and can query either of them.
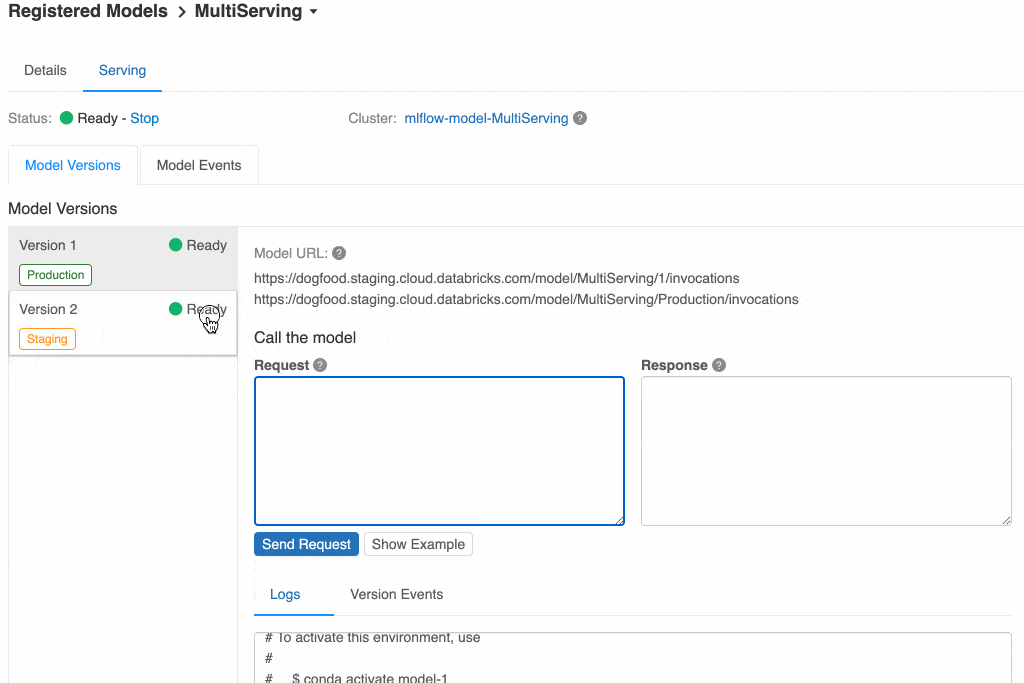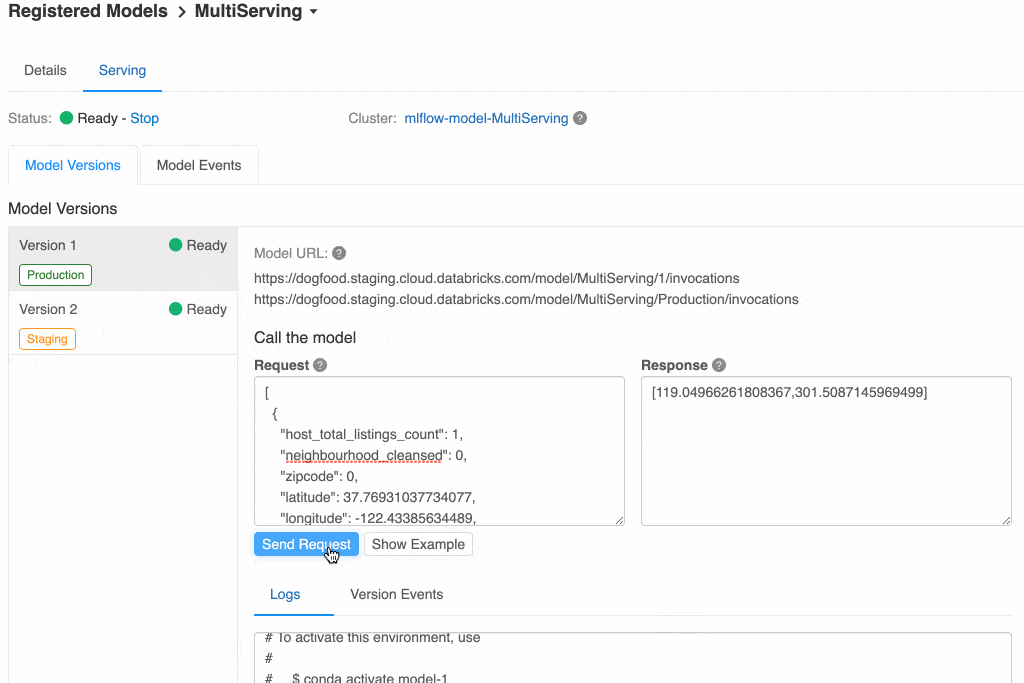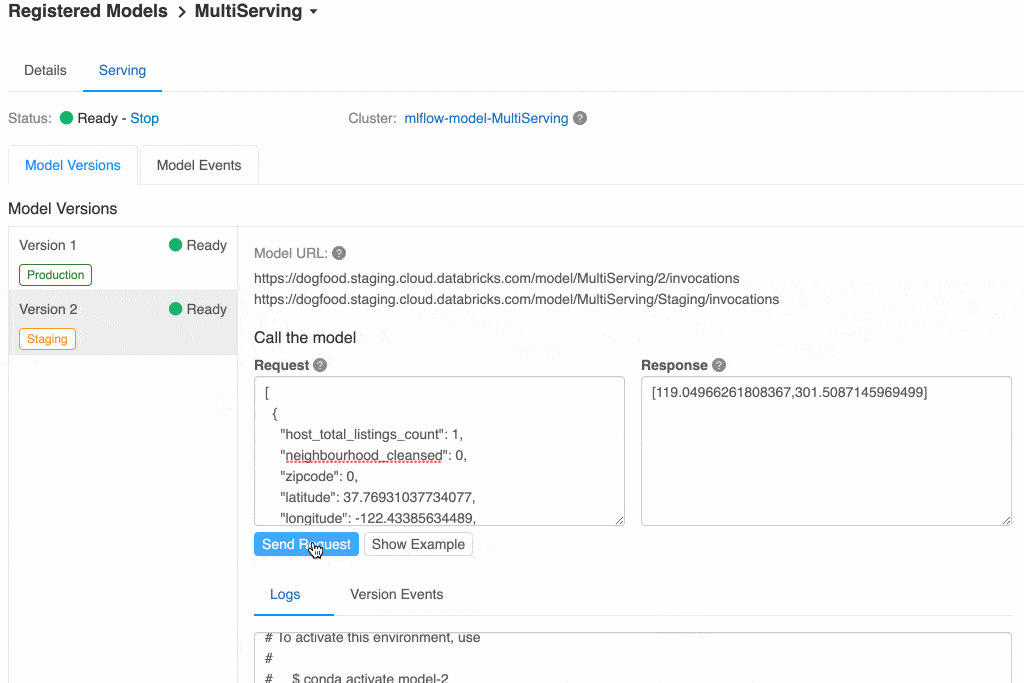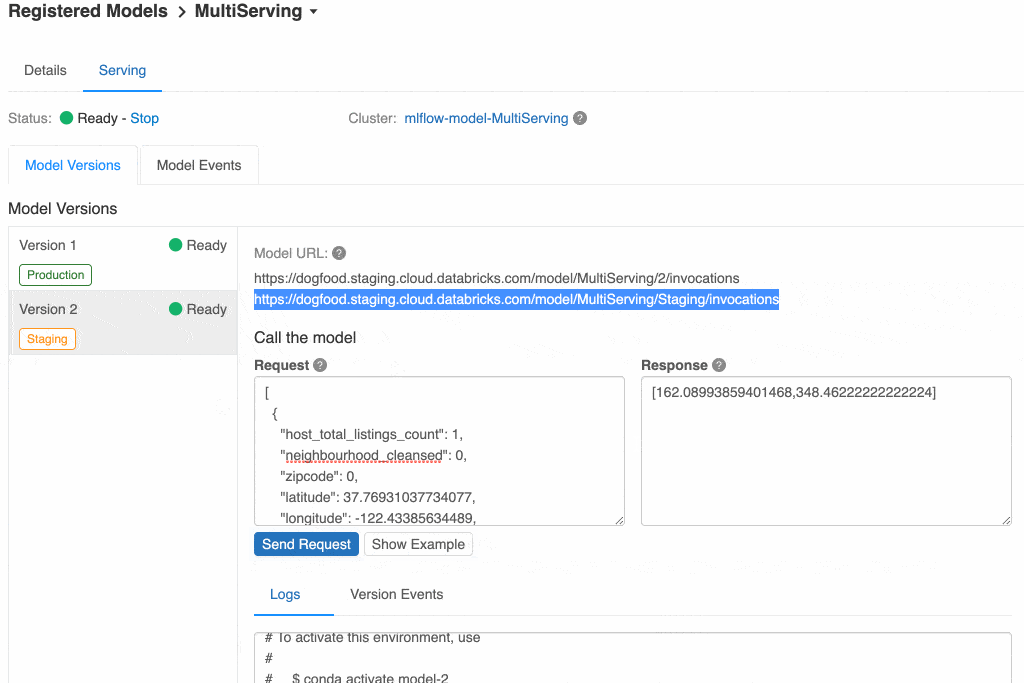
Note the URL for each model: you can query either by the version number (1 or 2) or by the stage (Production or Staging). This way you can have your live site point to the current Production version and have a test site pointed to the Staging version, and it will automatically pick up the latest model versions as they're promoted through the Registry.
When you're ready to promote a model version to Production, you simply transition its stage in the Registry, moving it from Staging to Production. This change will be reflected within the served model and REST endpoints within a few seconds -- the URL for Production will now point to Version 2.
Because everything is running in the same cluster, the marginal resource and time cost of spinning up a new version is very small. You don't have to worry about a multi-minute iteration cycle, or losing track of old versions.
Monitoring your model
Since model servers are long-lived, it's important to be able to easily monitor and maintain the availability of your models. Model Serving makes this easy by exposing two kinds of information: logs and events.
Logs for each model version are available via UI and API, allowing you to easily emit and see issues that are related to malformed data or other runtime errors. Events supplement the model's own logs by detailing when a model process crashed and was restarted, or when a whole virtual machine was lost and replaced. As simple as it sounds, having easy access to these logs and events makes the process of developing, iterating, and maintaining model servers much less time-consuming.
To recap, Model Serving on Databricks provides cost-effective, one-click deployment of models for real-time inference, integrated with the MLflow model registry for ease of management. Use it to simplify your real-time prediction use cases! Model Serving is currently in Private Preview, and will be available as a Public Preview by the end of July. While this service is in preview, we recommend its use for low throughput and non-critical applications.
Happy serving!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.