How to Extract Market Drivers at Scale Using Alternative Data
by Ricardo Portilla and Abraham Pabbathi
Watch the on-demand webinar Alternative Data Analytics with Python for a demonstration of the solution discussed in this blog and/or download the following notebooks to try it yourself.
- Stock Analysis - Plant-based Meat Historical Data
- GDELT News Source In Lakehouse
- Text Analytics on GDELT
- Alternative Data Time Series Foot Traffic Forecasting
Introduction
Why Alternative data Is critical
Main Section - Solution + Descriptive Notebook
Architecture
Ingest alternative data sources
Data analysis using Python:
Important term exploration with TF-IDF
Named entity recognition
Why alternative data is critical
Alternative data is helping banking institutions, insurance companies and asset managers alike make better decisions by revealing valuable information about consumer behavior (e.g. utility payment history, transaction information) and extends across a variety of use cases including trade analyses, credit risk, and ESG risk. Traditional data sources, such as FICO scores or quarterly 10Q reports, have been mined and analyzed to the point that they no longer provide a competitive advantage. To gain a real competitive advantage, financial services institutions (FSIs) need to leverage alternative data to obtain a better understanding of their customers, markets, and businesses. Some of the most common alternative datasets used in the industry include news articles, web/mobile app exhaust data, social media data, credit/debit card data, and satellite imagery data.
According to a survey completed by Dow Jones newswire, 66% of respondents believe alternative data is critical to the success of their FSI. However, only 7% believe they are leveraging alternative data to the greatest extent possible. Transunion reports confirm that 90% of loan applicants would be no-hit (failure to provide credit score) without alternative data, which highlights the immense value of these data sources. Two main reasons FSIs fail to extract value are a) challenges in integrating alternative data sources (e.g. transactions) and traditional data sources (e.g. earnings reports) and b) iterating on experiments with unstructured data. On top of this, historical datasets are large, frequently updated, and require thorough cleansing to unlock value.
Fortunately, Databricks Unified Data Analytics Platform and Delta Lake, an open-source storage layer that brings ACID transactions to big data workloads, helps organizations overcome these challenges with a scalable platform for data analytics and AI in the cloud. More specifically, Databricks’ Delta Lake autoloader gives capabilities for ‘set and forget’ ETL into a format ready for analytics, improving productivity for data science teams. Additionally, Databricks’ Apache SparkTM runtime on Delta Lake provides performance benefits for parsing and analyzing unstructured and semi-structured sources, such as news and images, thanks to optimized data lake parsers and simple library (e.g. NLP packages) management.
In this blog post, we explore an architecture based on Databricks and Delta Lake which combines analyses on unstructured text and structured time series foot traffic data, mocked in the SafeGraph data format. The specific business challenge is to extract insights from these alternative data sources and uncover a network of partners, competitors, and a proxy for sales at QSRs (quick-serve restaurants) for one plant-based meat company Beyond Meat. We delivered this content in a joint webinar with SafeGraph, which specializes in providing curated datasets for points of interest, geometries, and patterns which is available here.
Discovering key drivers for stock prices using alternative data
The biggest shifts in stock prices occur when new information is released regarding the past performance or future viability of the underlying companies. In this example, we examine alternative data, namely news articles and foot traffic data, to see if positive news, such as celebrity endorsements and free press garnered by innovative products such as plant-based meats, can attract foot traffic to fast-food restaurants, increase sales and ultimately move their stock prices.
To begin the task of getting insights from news articles, we will set up the architecture shown in the diagram below. We are using three data sources for our analysis:
- articles from an open-source online database called GDELT project
- restaurant foot traffic (mocked up using the SafeGraph schema)
- market data from Yahoo finance for initial exploratory analysis
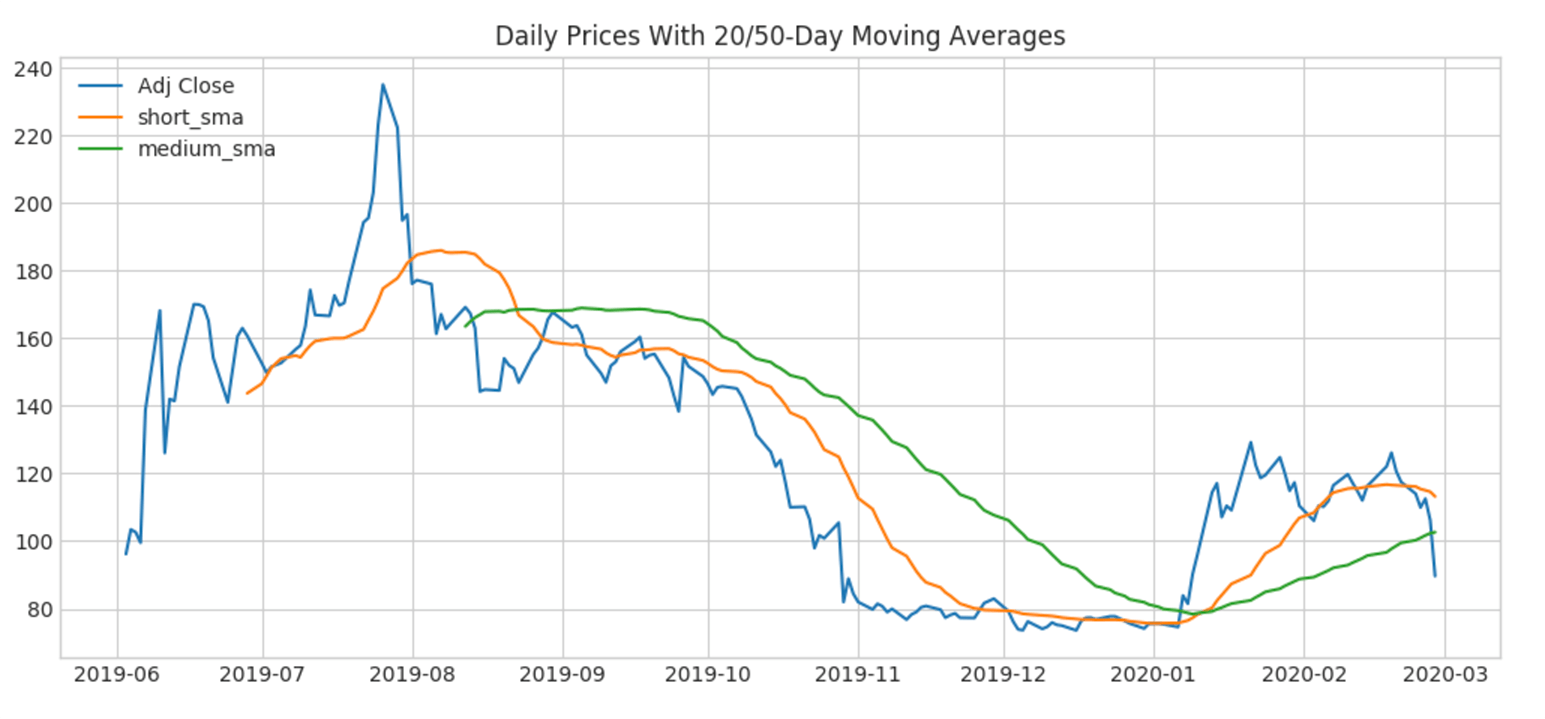
In the attached notebooks, our analysis begins with a chart to examine a simple moving average (SMA). As shown below, since Beyond Meat is a young company, we cannot extract the simplest of technical indicators, and this is our primary driver for understanding this company from other perspectives, namely news and foot traffic data.
Alternative data sources often exist in raw format in external cloud storage, so a good first step is to ingest this into Delta Lake, an open format based on parquet and optimal for scalable and reliable analytics on a cloud data lake. We establish three layers of data storage using Delta Lake, each with an increasing level of data refinement from raw ingested data on the left (bronze) to parsed and enriched data in the middle layer (silver) to aggregated and annotated data ready for business intelligence (BI) and machine learning on the right.

Incrementally ingesting alternative data sources
The first step towards analyzing alternative data is to set up ingestion pipelines from all the required data sources. In this example, we are going to show you how to ingest two data sources:
- Front Page News Articles: We are going to pull news articles related to plant-based meat. We are going to leverage an open database called GDELT which scans 50,000 news outlets daily and provides a snapshot of all the news headlines and links every hour.
- Geospatial Foot Traffic: We will import (mock) foot traffic data for popular restaurants such as Dunkin Donuts in the NY Metro area for the past 12 months using Safegraph's data format, which is an alternative data vendor specializing in curated points of interest and patterns datasets.
Autoload data files into Delta Lake
Many alternative data sources, such as news or web search data, arrive in real-time. In our example, GDELT articles are refreshed every 15 minutes. Other sources, such as transaction data, arrive on a daily basis, but it is cumbersome for data science teams to have to keep track of the latest dates in order to append new data to their data lake. To automate the process of ingesting data files from the above-mentioned data sources, we will leverage Databricks Delta Lake’s autoloader functionality to pick up these files continuously as they arrive. We take the data as-is from the raw files and store it into staging tables in Delta format. These tables form the “bronze” layer of the data platform. The code to auto ingest files is shown below. Note that the Spark stream writer has a ‘trigger once’ option: this is particularly useful to avoid always-on streaming queries and instead allows the writer to schedule it on a daily cadence, for ‘set and forget’ ingestion. Also, note that the checkpoint gives us built-in fault tolerance and ease-of-use at no cost; when we start this query at any time, it will only pick up new files from the source and we can safely restart in case of failure.
Data analysis using Python
Python is a popular and versatile language used by many data scientists around the world. For tasks involving text cleansing and modeling, there are hundreds of libraries and packages, making it our go-to language in the analysis that follows. We first read the bronze layer and load it into an enriched dataset containing the article text, timestamp, and language of the GDELT source. This enriched format will constitute the silver layer and details of this extraction are in the attached notebooks. Once the data is in the silver layer, we can clean and summarize the text in three steps:
- Summarize terms from corpus - discover important and unique terms among the corpus of articles using TF IDF
- Summarize article topics from corpus - Topic modeling for articles using distributed LDA may give us information about the following:
- Understand the current TAM by uncovering popular forms of plant-based meat (e.g. pork, chicken, beef)
- Which competitors or QSRs are showing up as major topics?
- Find interesting named entities in articles to understand the influences of entities on plant-based meat products and affected companies
Important term exploration with TF-IDF
Given we are examining many articles about plant-based meat, there are commonalities among these articles. Term Frequency-Inverse Document Frequency (TF-IDF for short) gives us the important terms normalized by their presence in the broader corpus of articles. This type of analysis is easy to distribute with Apache Spark and runs in seconds on thousands of articles. Below is a summary using the TF-IDF computed value, ranked in descending order.

What is notable here are some of the names and ticker information. Digging into the article text, we found that Lana Weidgenant created a petition for bringing a new plant-based meat product to Dunkin’s menu. Another interesting observation is the stock ticker TSX: QSR shows up here. This is the ticker for Canadian stock Restaurant Brands International, which pulled Beyond Meat products at Tim Hortons locations due to failed adoption by customers. This simple term summary allows us to get a quick picture of a few quick-serve restaurants (QSRs for short) and Beyond Meat’s impact.
Applying topic modeling at scale
Now, let’s apply a topic model to understand articles as distributions of topics and topics as distributions of terms. Since we are using unsupervised learning techniques to summarize article content, generative model LDA (Latent Dirichlet Allocation) is a natural choice for discovering latent topics among articles. Fortunately, this algorithm is distributable and built into Spark ML. The succinct code below shows a short and simple configuration needed to run this on our text. We’ve also included a bar chart showing a visual representation of topics extracted from the LDA model.
First, before running any type of modeling exercise, it is essential to clean our data further. To do this, let’s use the robust NLP library nltk to filter short words, stop words, remove punctuation, and stem our tokens. This will greatly help in improving model results. Below is the function we will apply to each row of our data frame before wrapped inside a pandas UDF. Note that we’ve customized the nltk stop word list since we have extra information about our article base. In particular, ‘veganism’, ‘plant-based’, and meat are not necessarily interesting topics or terms - instead, we want information on QSRs serving these products or actual partners themselves.
Now that we’ve cleaned our text, we’ll leverage Spark for two steps: i) Run a count vectorizer with a vocabulary size of 1000 to featurize our data into vectors and ii) fit LDA to our vectorized data. Note that we’ve included a parameter on document concentration (otherwise known as alpha in the world of LDA), which indicates the document topic density - higher values correspond to the assumption that there are many topics per article as opposed to a smaller number. The default is 1/# of topics, so here we choose a lower value to assume a lower number of topics.
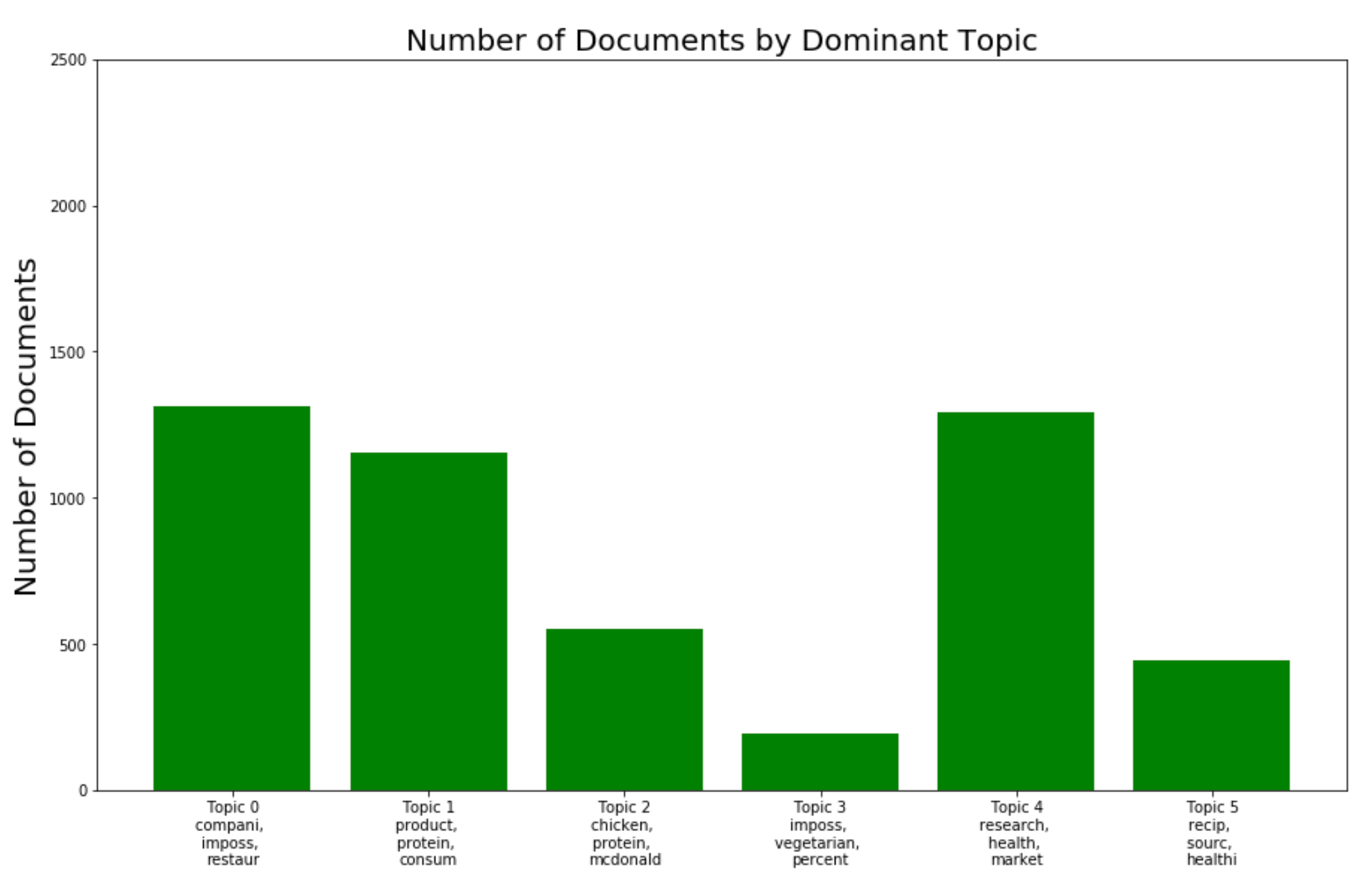
Representation of terms with probabilities within each topic
Our LDA model has produced a set of six topics that we summarize below using a bar chart to show distribution over topics and the top 3 terms per topic. Some notable observations involve Beyond Meat protein (chicken), partners (McDonald’s), and competitors such as Impossible Foods featured prominently.
Named entity recognition
Our topic model gave us great information about more QSRs involved in selling plant-based meat. Now, we want to understand which entities are collocated in the same article to give us more information on any special partnerships or promotions. If we extract information on how Beyond Meat is penetrating the market, we can potentially use other alternative data sources to uncover transaction information or restaurant visits, for example.
Let’s use the Python NLP library SpaCy’s built-in named entity recognition to help solve this problem. Also, instead of running the entity recognition on the article text, let’s run it on the article title text itself to see if we can find new information on partnerships or promotions. We use a Spark Pandas UDF to parallelize the entity recognition annotation (as below).
Now, we produce a summary of the entity information we received from SpaCy’s logic:
- Dunkin’ was one of the top 10 entities
- SQL exploration of all entities related to Dunkin' (Snoop Dogg was a standout)
- Visualization of the article highlighting a promotion by Dunkin’ and Snoop Dogg for a Beyond Meat sandwich, targeted for January 2020.
Now that we have a specific example of Beyond Meat’s sales strategy, let’s formulate a hypothesis about the effectiveness of the promotion using another popular alternative data type - geolocation data, in this case, provided by Safegraph’s POI offering.

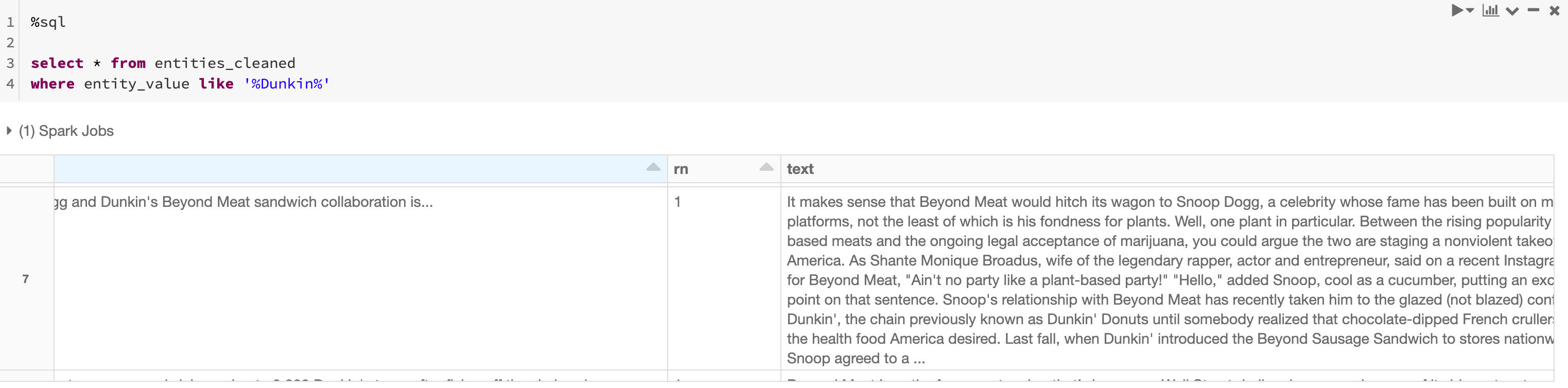
Below is the visualized representation of entities that SpaCy produces, which is easily viewable in a Databricks notebook. To produce this, we took the text from the article above we observed through SQL exploration.

Validating signals using Safegraph’s POI data
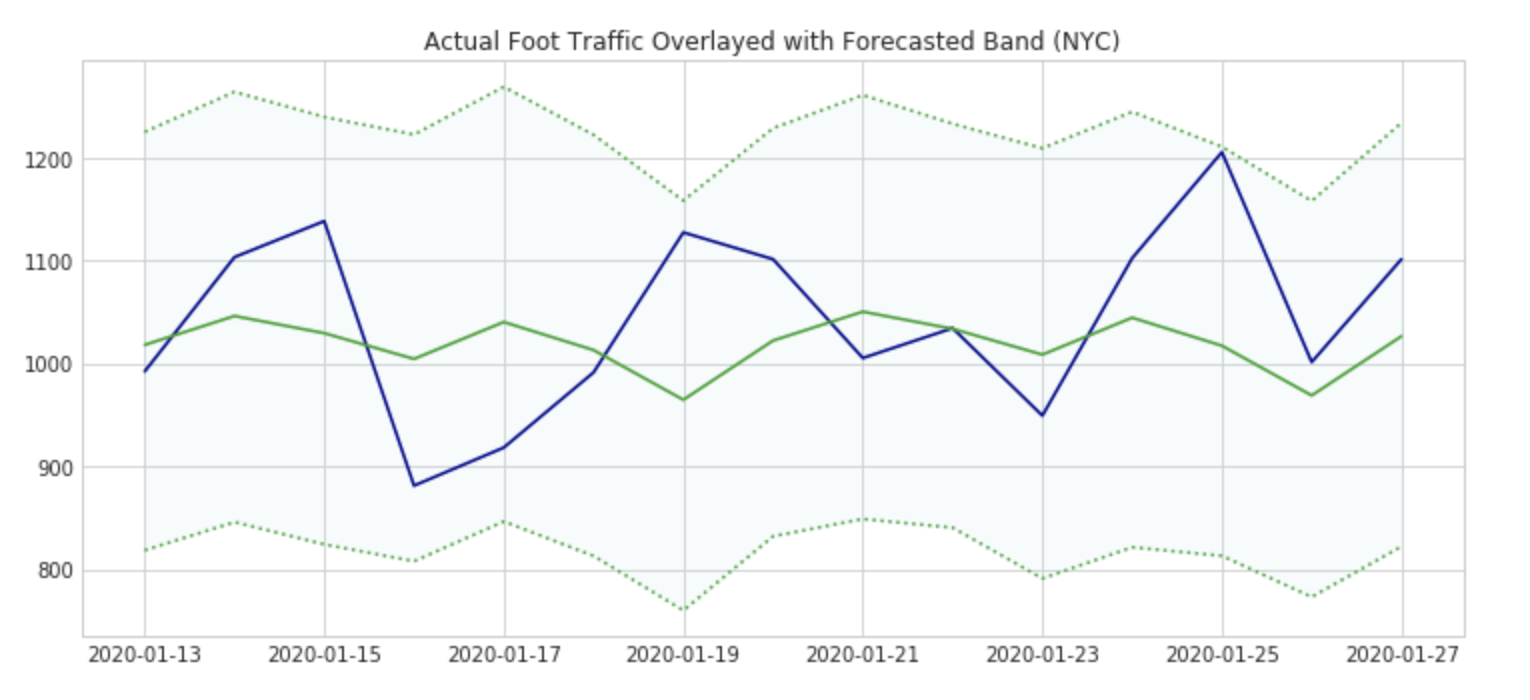
Up to this point, we have done many different kinds of news analyses. However, this has only leveraged our GDELT dataset. While results from NLP summaries above have led us to the need to understand Beyond Meat promotions via partnerships, we want to analyze some proxy for sales to see how effectively Beyond Meat is penetrating the fast-food market. We will do this using a mocked dataset based on SafeGraph’s geo-location data schema.SafeGraph's data is coalesced from over 50M mobile devices and offers highly structured formats based on POI (point-of-interest) data for many different brands. The POI data is especially interesting for our use case since we are focused on QSRs (quick-serve restaurants) which tend to have high conversion rates and serve as a proxy for sales. In particular, given a promotion of a Beyond Meat-based product (in this case Snoop Dogg’s breakfast sandwich), we want to understand whether foot traffic was ‘significant’ for this short time period given historical time series data on foot traffic at NYC Dunkin’ locations. We’ll use an additive time series forecasting model, Prophet, to forecast the foot traffic for a week in January based on the prior year’s history. As a crude metric, a significant uptick in foot traffic will equate to actual Safegraph traffic amounts being higher than the 80% prediction interval forecasted traffic for the majority of the length of the promotional period (1 week).
Note: The foot traffic data used within the notebooks and shown in this blog is simulated based on the SafeGraph schema. In order to validate with true data, visit SafeGraph to get these samples.
While SafeGraph’s foot traffic is cleansed well, we still need to explode each record to create a time series for Prophet. The code in the attached notebook creates a row per date of the number of visits, i.e. the num_visits array has been converted to multiple records, one record per date as below.
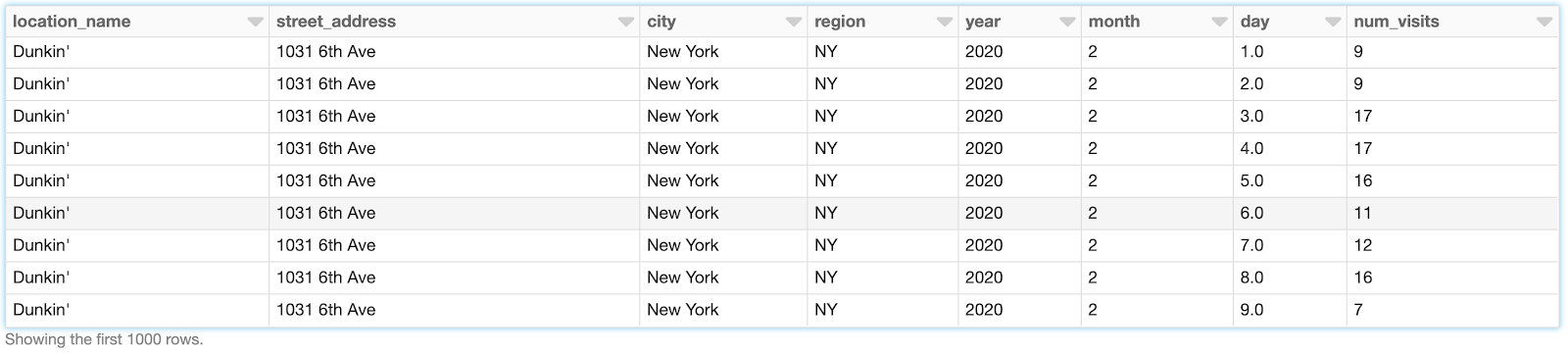
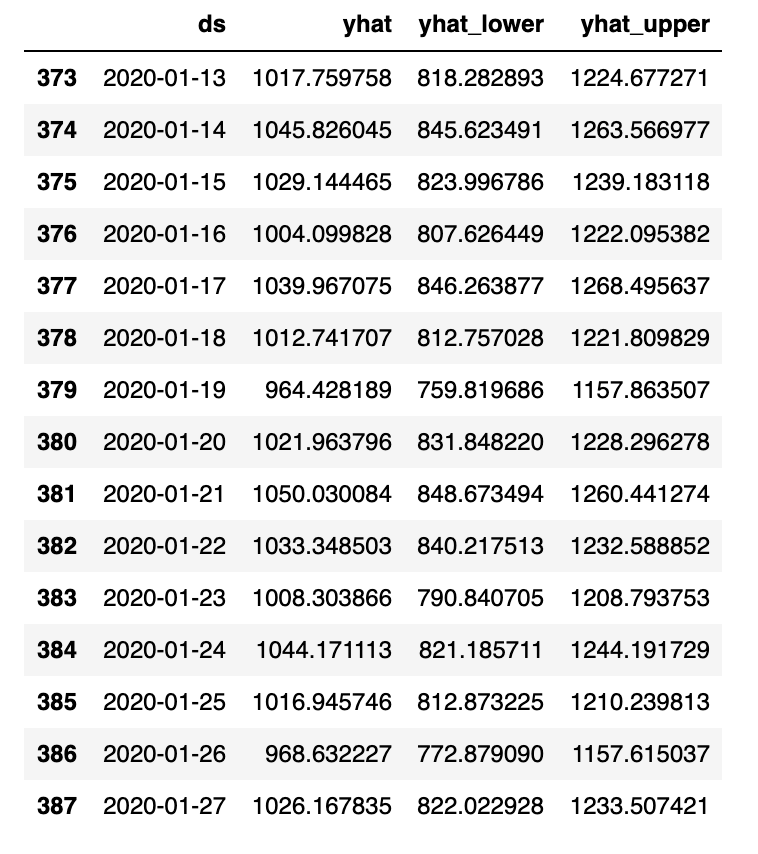
Using the data above, we can aggregate by the date to produce a time series we can use for our forecasting model, which we’ve named all_nyc_dunkin. Once this is done, we’ll produce a pandas data frame, shown below.
Overlaying the forecast above with actual foot traffic data, we see that the additional traffic doesn’t pass our test for ‘significant’ (all dates stayed within the prediction interval). Our POI data has allowed us to achieve this interesting result quickly with a simple library import and aggregation in SQL. To conclude this analysis, this is not to say that the average receipt didn't have a higher bill amount as compared to the average transaction price - however, we would need transaction data (another alternative dataset) to confirm this.
Overall, our goal was to enhance our methodology for discovering market drivers. The analyses presented here greatly improve on the limited technical market data we first inspected. While we would likely conclude there is not a strong buy or sell signal for Beyond Meat based on the article summaries or foot traffic, all of the analyses above can be automated and extended to other use cases to provide hourly dashboards to aid financial decisions.
Leveraging alternative data
In summary, this blog post has provided a variety of ideas on how you can leverage alternative data to inform and improve your financial decision-making process. The pipeline code we have provided in this blog post is only for the purpose of getting you started in this journey of exploring non-traditional data. In real-life scenarios, you may deal with more messy data which will require more cleaning steps before the data is ready for analysis. But irrespective of how many steps you need to execute or how big the datasets are, Databricks provides an easy-to-use, collaborative, and scalable platform to uncover insights from unstructured and siloed data in a matter of minutes and hours instead of weeks. Databricks is currently helping some of the largest financial institutions which are leveraging alternative data for investment decisions and we can do the same for your organization as well.
Getting Started
Download the Notebooks:
- Stock Analysis - Plant-based Meat Historical Data
- GDELT News Source In Lakehouse
- Text Analytics on GDELT
- Alternative Data Time Series Foot Traffic Forecasting
More Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.