Faster SQL: Adaptive Query Execution in Databricks
by MaryAnn Xue and Allison Wang
Earlier this year, Databricks wrote a blog on the whole new Adaptive Query Execution framework in Spark 3.0 and Databricks Runtime 7.0. The blog has sparked a great amount of interest and discussions from tech enthusiasts. Today, we are happy to announce that Adaptive Query Execution (AQE) has been enabled by default in our latest release of Databricks Runtime, DBR 7.3.
AQE is an execution-time SQL optimization framework that aims to counter the inefficiency and the lack of flexibility in query execution plans caused by insufficient, inaccurate, or obsolete optimizer statistics. As we continue our effort to expand AQE functionalities, below are the specific use cases you can find AQE most effective in its current status.
Check out the Why the Data Lakehouse is Your Next Data Warehouse ebook to discover the inner workings of the Databricks Lakehouse Platform.
Optimizing Shuffles
While Spark shuffles are a crucial part of the query performance, finding the right shuffle partition number has always been a big struggle for Spark users. That is because the amount of data varies from query to query, or even from stage to stage within the same query, and using the same shuffle partition number can lead to either small tasks that make inefficient use of the Spark scheduler, or otherwise big tasks that may end up with excessive garbage collection (GC) overhead and disk spilling.
Now, AQE adjusts the shuffle partition number automatically at each stage of the query, based on the size of the map-side shuffle output. So as data size grows or shrinks over different stages, the task size will remain roughly the same, neither too big nor too small.
However, it is important to note that AQE does not set the map-side partition number automatically. This means in order for this AQE feature to work perfectly, it is recommended that the user set a relatively high number of initial shuffle partition number through the SQL config spark.sql.shuffle.partitions. Or, as an alternative, they can enable Databricks edge feature “Auto-Optimized Shuffle” by setting config spark.databricks.adaptive.autoOptimizeShuffle.enabled to true.
Choosing Join Strategies
One of the most important cost-based decisions made in the Spark optimizer is the selection of join strategies, which is based on the size estimation of the join relations. But since this estimation can go wrong in both directions, it can either result in a less efficient join strategy because of overestimation, or even worse, out-of-memory errors because of underestimation.
AQE offers a trouble-free solution here by switching to the faster broadcast hash join during execution time.
Handling Skew Joins
Data skew is a common problem in which data is unevenly distributed, causing bottlenecks and significant performance downgrade, especially with sort merge joins. Those individual long running tasks will become stragglers, slowing down the entire stage. And on top of that, spilling data out of memory onto disk usually happens in those skew partitions, worsening the effect of the slowdown.
The unpredictable nature of the data skew often makes it hard for the static optimizer to handle skew automatically, or even with the help of querying hints. By collecting runtime statistics, AQE can now detect skew joins at runtime and split skew partitions into smaller sub-partitions, thus eliminating the negative impact of skew on query performance.
Understand AQE Query Plans
One major difference for the AQE query plan is that it often evolves as execution progresses. Several AQE specific plan nodes are introduced to provide more details about the execution. Furthermore, AQE uses a new query plan string format that can show both the initial and the final query execution plans. This section will help users get familiar with the new AQE query plan, and show users how to identify the effects of AQE on the query.
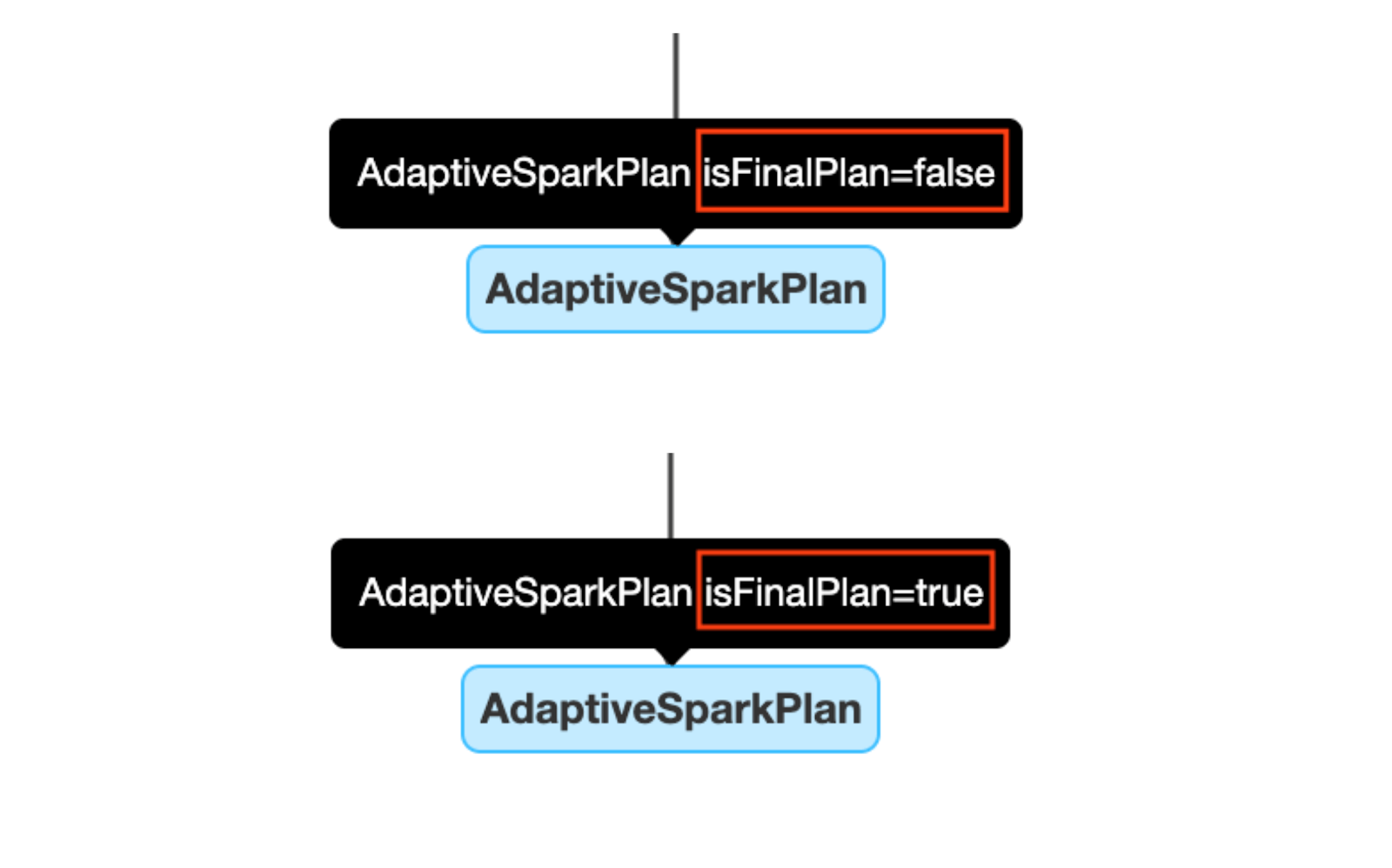
The AdaptiveSparkPlan Node
AQE-applied queries usually have one or more AdaptiveSparkPlan nodes as the root node of each query or subquery. Before or during the execution, the `isFinalPlan` flag will show as `false`. Once the query is completed, this flag will turn to `true` and the plan under the AdaptiveSparkPlan node will no longer change.
The CustomShuffleReader Node
The CustomShuffleReader node is the key to AQE optimizations. It can dynamically adjust the post shuffle partition number based on the statistics collected during the shuffle map stage. In the Spark UI, users can hover over the node to see the optimizations it applied to the shuffled partitions.
When the flag of CustomShuffleReader is `coalesced`, it means AQE has detected and coalesced small partitions after the shuffle based on the target partition size. Details of this node shows the number of shuffle partitions and partition sizes after the coalesce.

When the flag of CustomShuffleReader is `skewed`, it means AQE has detected data skew in one or more partitions before a sort-merge join operation. Details of this node shows the number of skewed partitions as well as the total number of new partitions splitted from the skewed partitions.
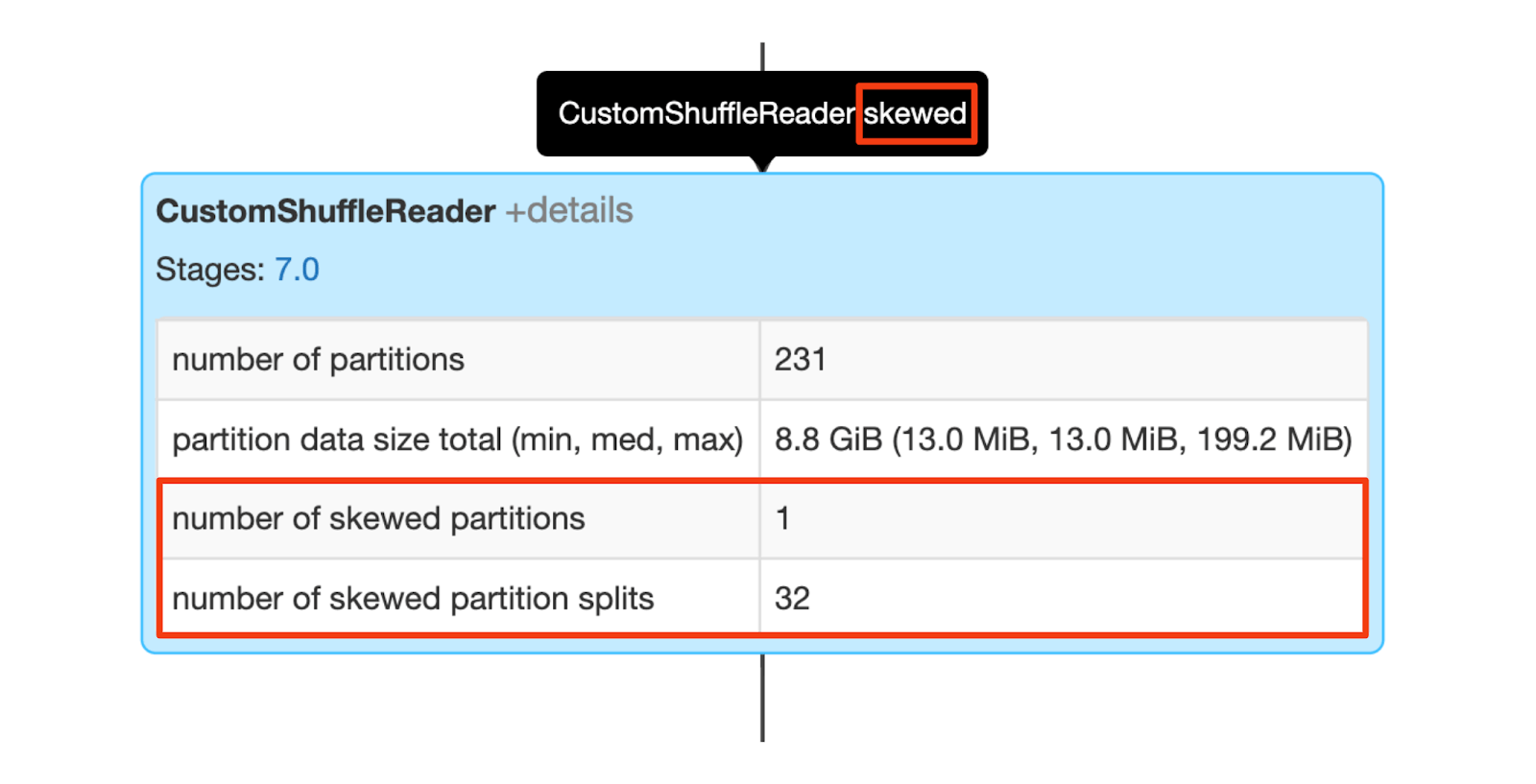
Both effects can also take place at the same time:

Detecting Join Strategy Change
A join strategy change can be identified by comparing changes in query plan join nodes before and after the AQE optimizations. In DBR 7.3, AQE query plan string will include both the initial plan (the plan before applying any AQE optimizations) and the current or the final plan. This provides better visibility into the optimizations AQE applied to the query. Here is an example of the new query plan string that shows a broadcast-hash join being changed to a sort-merge join:
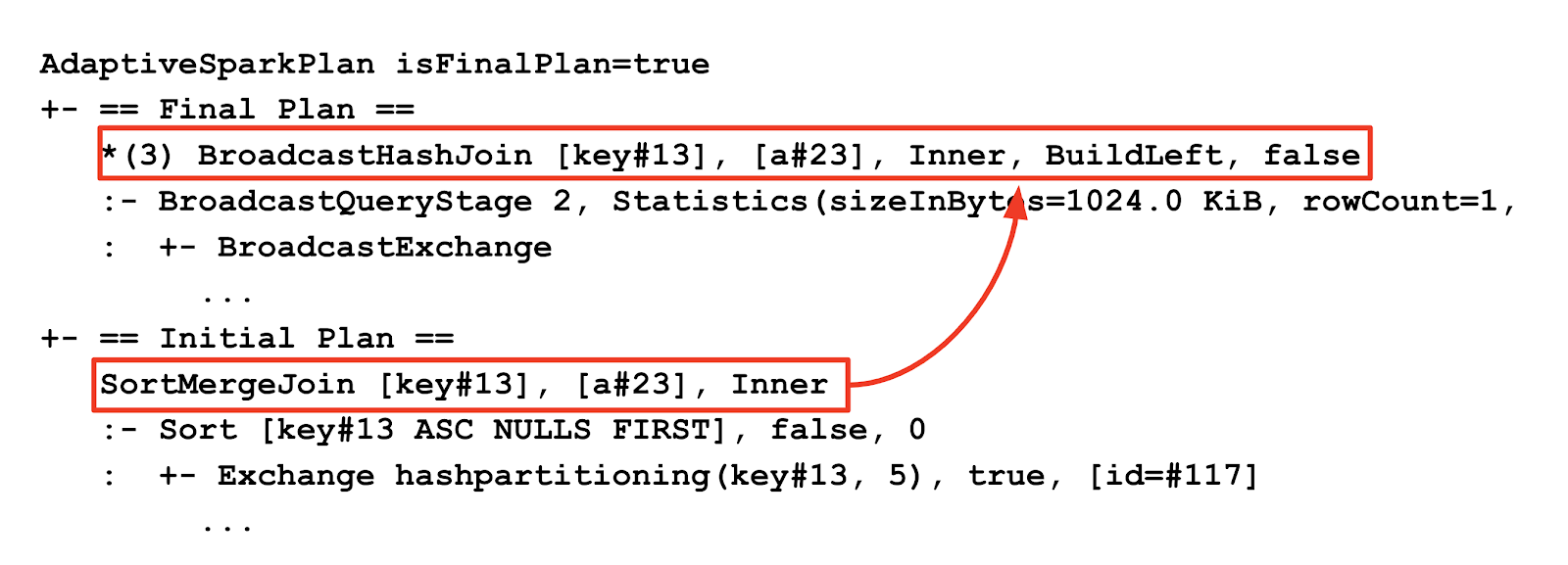
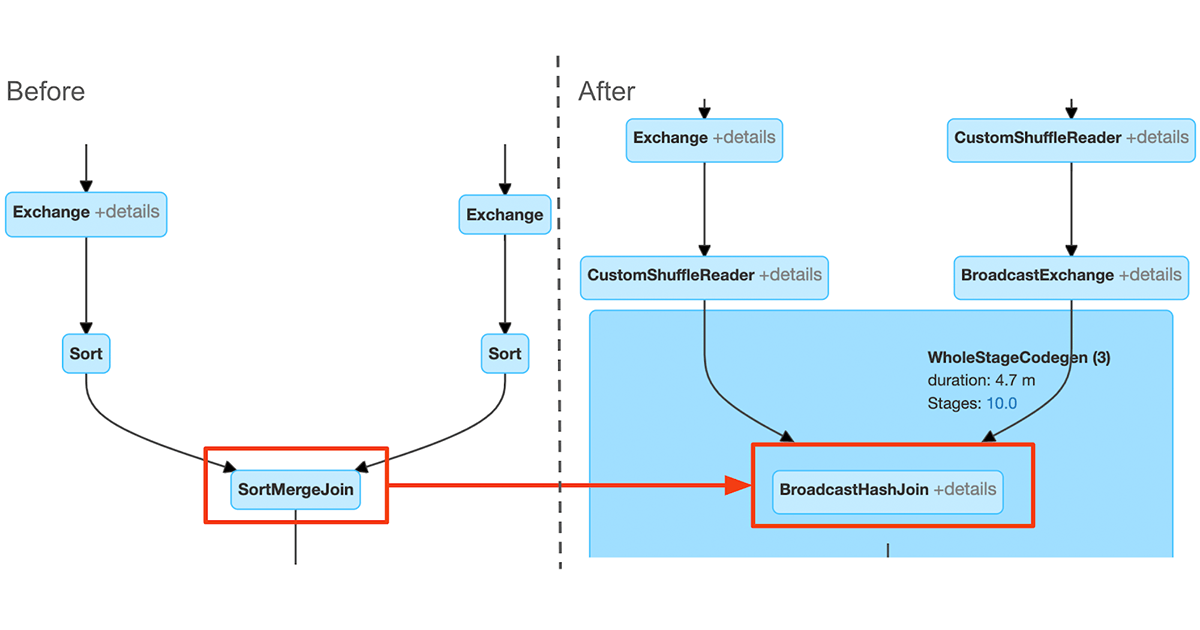
The Spark UI will only display the current plan. In order to see the effects using the Spark UI, users can compare the plan diagrams before the query execution and after execution completes:
Detecting Skew Join
The effect of skew join optimization can be identified via the join node name.
In the Spark UI:
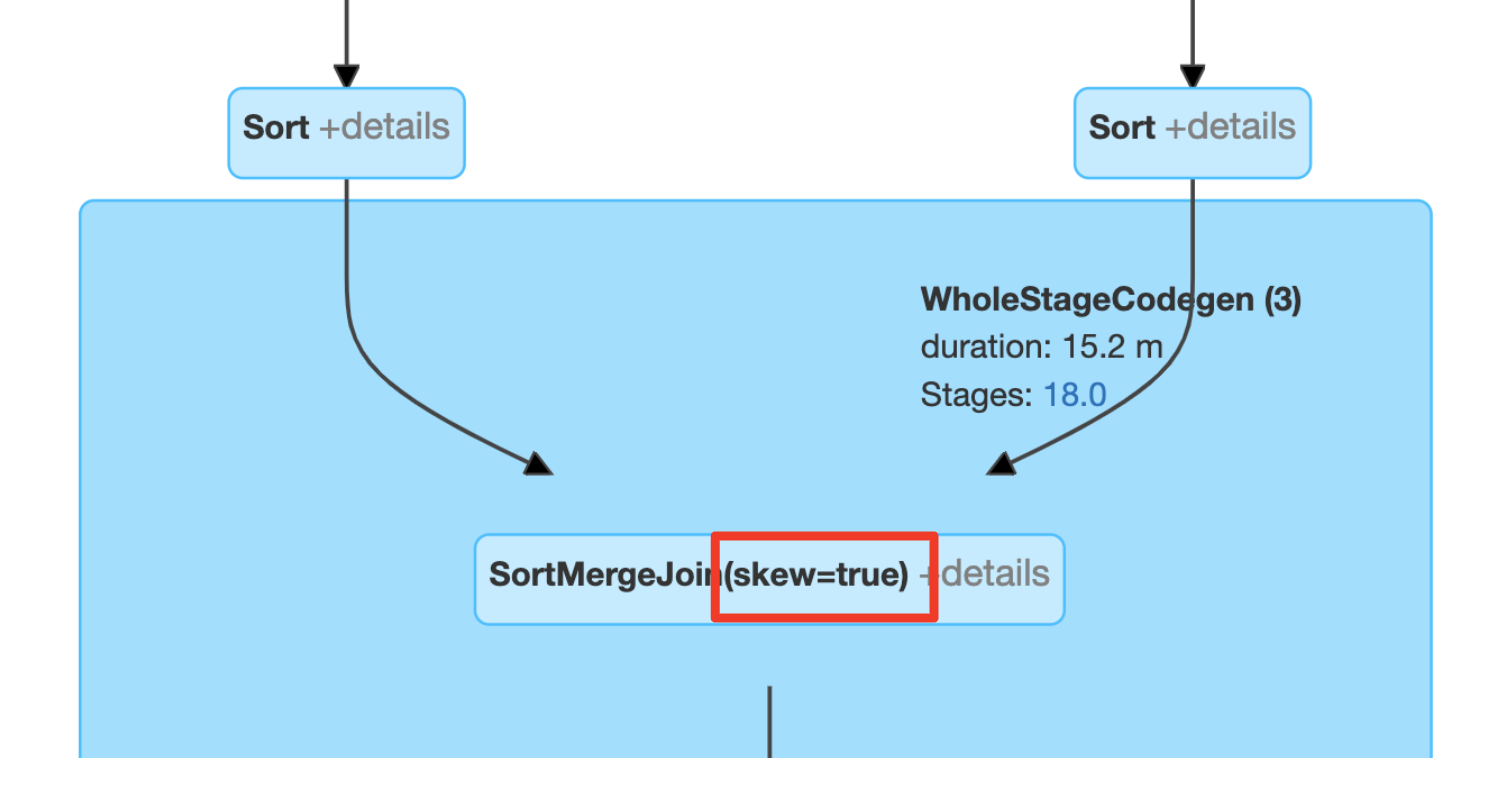
In the query plan string:

Adaptive query execution incorporates runtime statistics to make query execution more efficient. Unlike other optimization techniques, it can automatically pick an optimal post shuffle partition size and number, switch join strategies, and handle skew joins. Learn more about AQE in the Spark + AI Summit 2020 talk: Adaptive Query Execution: Speeding Up Spark SQL at Runtime and the AQE user guide. Get started today and try out the new AQE features in Databricks Runtime 7.3.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.