Handling Late Arriving Dimensions Using a Reconciliation Pattern
Solving a common engineering ‘annoyance’ with the help of Apache Spark
|
This is a guest community post authored by Chaitanya Chandurkar, Senior Software Engineer in the Analytics and Reporting team at McGraw Hill Education. Special thanks to MHE Analytics team members Nick Afshartous, Principal Engineer; Kapil Shrivastava, Engineering Manager; and Steve Stalzer, VP of Engineering / Analytics and Data Science, for their contributions. |
Processing facts and dimensions is the core of data engineering. Fact and dimension tables appear in what is commonly known as a Star Schema. Its purpose is to keep tables denormalized enough to write simpler and faster SQL queries. In a data warehouse, a dimension is more like an entity that represents an individual, a non-overlapping data element where the facts are behavioral data produced as a result of an action on or by a dimension. A fact table is surrounded by one or more dimension tables as it holds a reference to dimension natural or surrogate keys.
Late-arriving transactions (facts) aren't as annoying as late-arriving dimensions. In order to ensure the accuracy of the data, usually dimensions are processed first as they need to be looked up while processing the facts for enrichment or validation. In this blog post, we are going to look at a few use cases of late-arriving dimensions and potential solutions to handle it in Apache Spark pipelines.
Architecture and Constraints
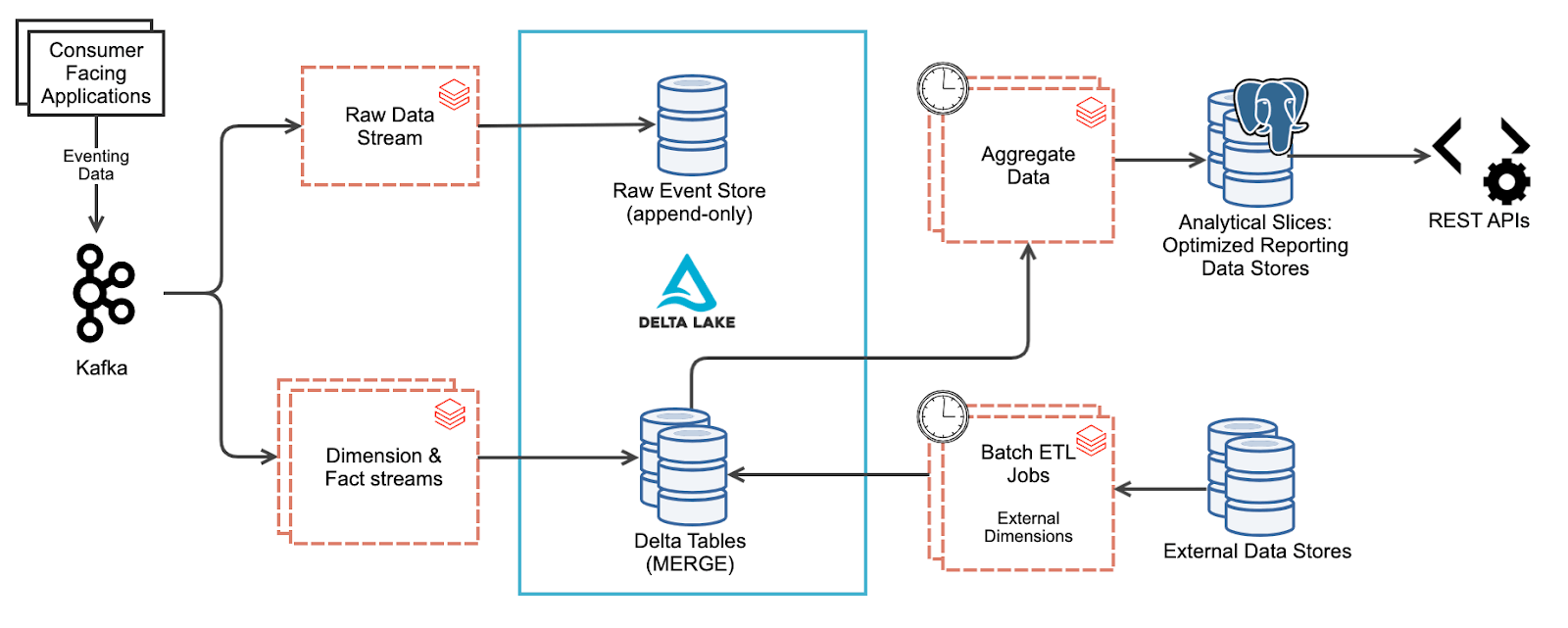
To give a little bit of context: The Analytics & Reporting team at McGraw Hill provides data processing and reporting services that operate downstream from the application. This service has a hybrid ETL structure. Some facts and dimensions generated by our customer-facing applications are consumed in near real-time, transformed, and stored in delta tables. Few dimensions that are not streamed yet, are ingested in batch ETLs from different parts of the system. Some facts that are streamed have a reference to keys of the dimension table. In some cases, it's possible that the fact being processed does not have a corresponding dimension entry yet because it’s waiting on ETL’s next run or has some problems upstream.
Even if other dimensions were streamed, it would still be possible for corresponding facts to arrive in close proximity.. Think of an automated test generating synthetic data in a lower environment. Another example that can be often seen is organizational migration. Private schools sometimes migrate under a district. This entity migration triggers a wave of Slowly Changing Dimensions and the facts streamed afterward should use the updated dimensions. In such cases, when attempting to join facts and dimensions, it's possible that the join will fail due to late-arriving dimensions.
The margin of error here can be reduced by scheduling ETL jobs efficiently to ensure new dimensions are processed before processing the new facts. At McGraw Hill, this is not an option because significant delays do occasionally occur in our source systems.
Potential Solutions
There are a few solutions that can be incorporated depending on the use cases and constraints enforced by the infrastructure.
Process now and hydrate later
In this approach, even if dimension lookup fails, facts are dumped into fact tables with default values in the dimension columns and have a hydration process to periodically hydrate the missing dimension data in the facts table. You can filter out data with no or default dimension keys while querying that table to ensure that you aren't returning the bad data. The caveat of this approach is that it does not work where those dimension keys are the foreign keys in fact tables. Another limitation is that if facts are written to multiple destinations, the hydration process has to update missing dimension columns in all those destinations for the sake of data consistency.
Early detection of late-arriving dimensions
We can detect the early-arriving facts instead (facts for which the corresponding dimension has not arrived yet), put them on hold, and retry them after a period until either they get processed or exhaust retries. This ensures data quality and consistency in the target tables. At McGraw Hill, we have many such streaming pipelines that read facts from Kafka, lookup multiple dimension tables, and write to multiple destinations. To handle such late-arriving dimensions, we built an internal framework that easily plugs into the streaming pipelines. The framework is built around a common pattern that all streaming pipelines use:
- Read data from Kafka.
- Transform facts and use the join to dimension tables.
- If the dimension has not arrived yet, flag the fact record as `retryable`.
- Write these retryable records in a separate delta table called `streaming_pipeline_errors`.
- MERGE valid records into the target delta table.
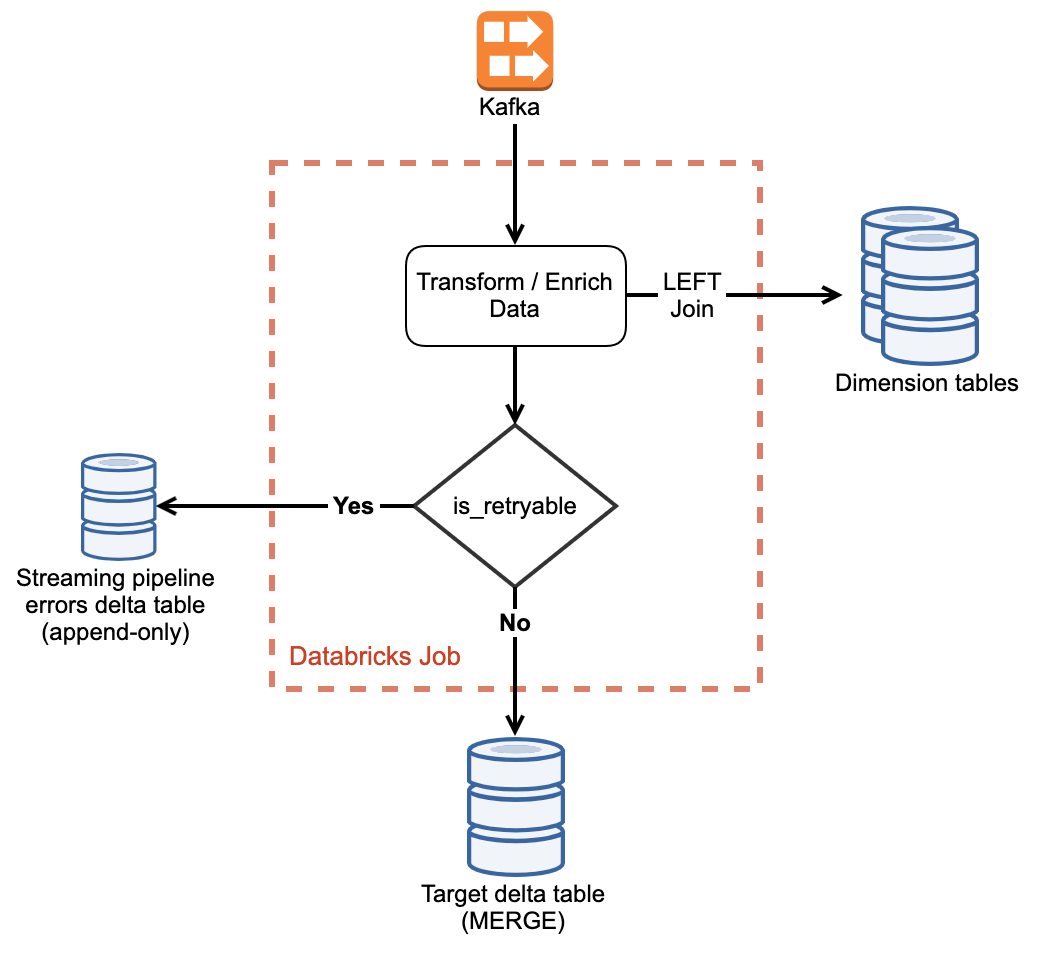
Records are flagged as "not_retryable" (is_retryable = false) if it is there's a schema validation failure (no use of retrying such events). Now, how do we reprocess fact data from the `streaming_pipeline_errors` table given a few limitations on the infrastructure:
- We could not put this data back on Kafka because such duplicate events are like noise to other consumers.
- We cannot not have another instance of the job running purely in "reconciliation" mode (re-process data only from error tables) as delta does not support doing concurrent MERGE operations on the same delta table.
- We could stop the regular job and run only the "reconciliation" version of this job but it could get complicated to orchestrate that with streaming jobs as they run in continuous mode.
A mechanism was needed to process retryable data along with the new data without having to send it back to Kafka. Spark allows you to UNION two or more data frames as long as they have the same schema. Retryable records can be unioned with the new data from Kafka and process it all together. That's how the reconciliation pattern was designed.
The Reconciliation Pattern
The reconciliation pattern uses a 2-step process to prepare the data to be reconciled.
- Write unjoined records to the streaming_pipeline_errors table.
- Put a process in place that consolidates multiple failed retries for the same event into a new single fact row with more metadata about the retries.
Using a scheduled batch process for Step-2 could automatically control the frequency of retries through its schedule.
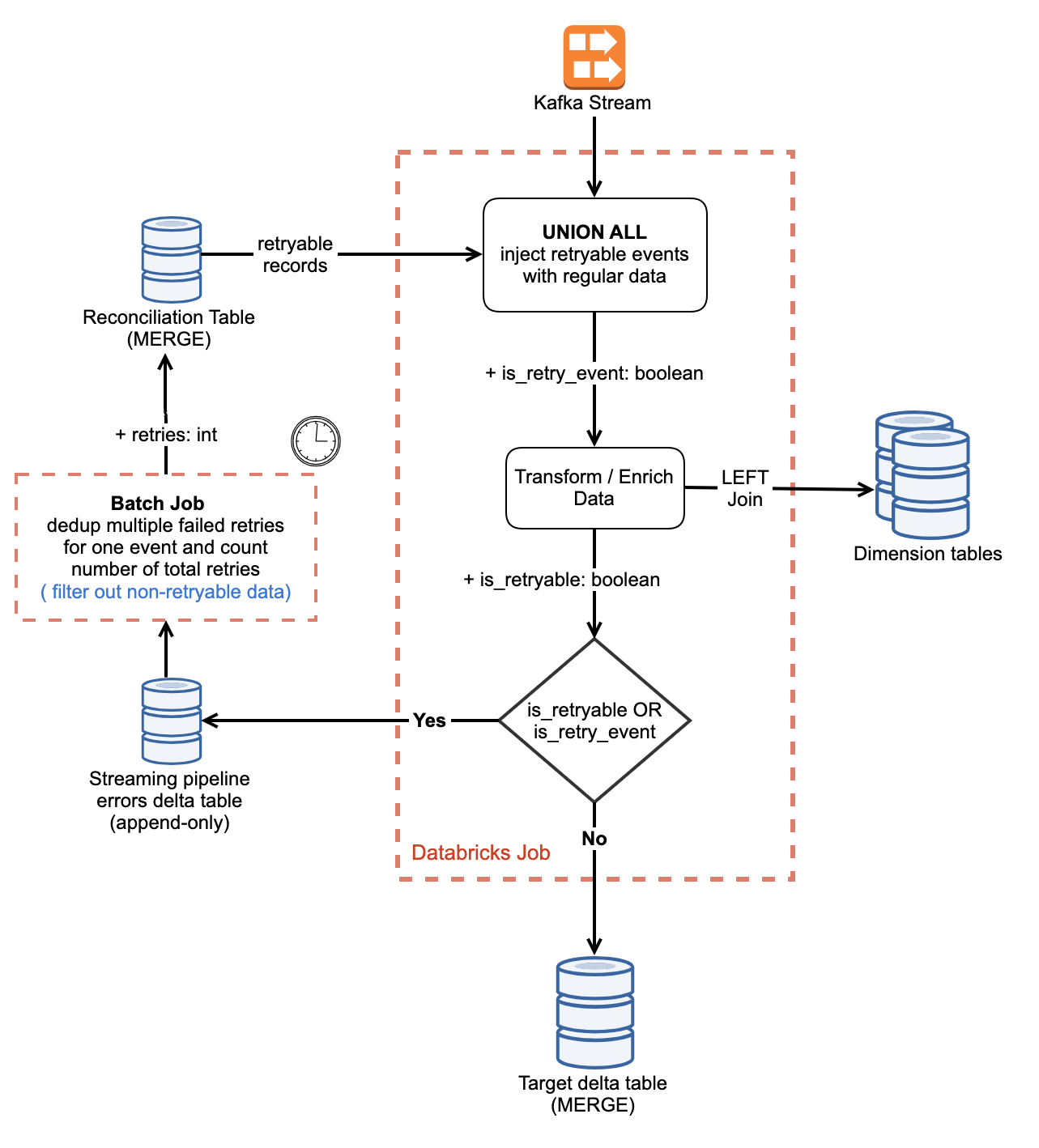
This is how the flow looks like:
- Read new events from Kafka.
- Read retryable events from the reconciliation table.
- UNION Kafka and retryable events.
- Transform/Join this unioned data with users dimension table.
- If there's any early arriving fact (dimension has not arrived yet), mark it as retryable.
- Write retryable records to the `streaming_pipeline_errors` table.
- MERGE all the good records into the target delta table.
- A scheduled batch job dedupes new error records and MERGE into a reconciliation table with updated retry count and status.
- Data written to the reconciliation table is picked up by the streaming pipeline in the next trigger.
In a streaming pipeline, data read from reconciliation is flagged as `retry_event`. All the failed retries are written back to the `streaming_pipeline_errors` table with status = 'NOT_RESOLVED'. When the reconciliation job MERGEs this data into the reconciliation table, it updates the number of retry counts for such failed retries. After certain retries, If data joins with the dimension table, we write it to the target table and also write an updated status to the `streaming_pipeline_errors` table with `status = RESOLVED` indicating that this event is processed successfully so that it is not injected back into the stream in next trigger.
Since the reconciliation table has the `retry_count`, each pipeline can control how many retries are allowed by filtering out reconciliation records that exceed the configured number of retries. If a certain event exhausts the max retry count, the reconciliation job updates its status as DEAD and is not retried anymore.
Example
Refer to this databricks notebook for a sample code. This is the miniature example of our logins pipeline that computes usage stats of our consumer-facing applications. Here login events are processed in near real-time. It joins login events with the user’s dimension table which is updated by another ETL that is scheduled as a batch job.
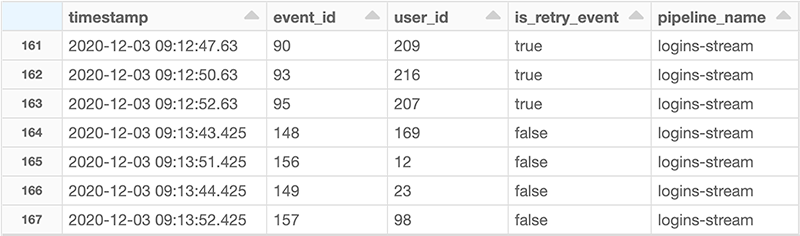
Logins data from Kafka unioned with retryable data from reconciliation table:
Users data from delta table:
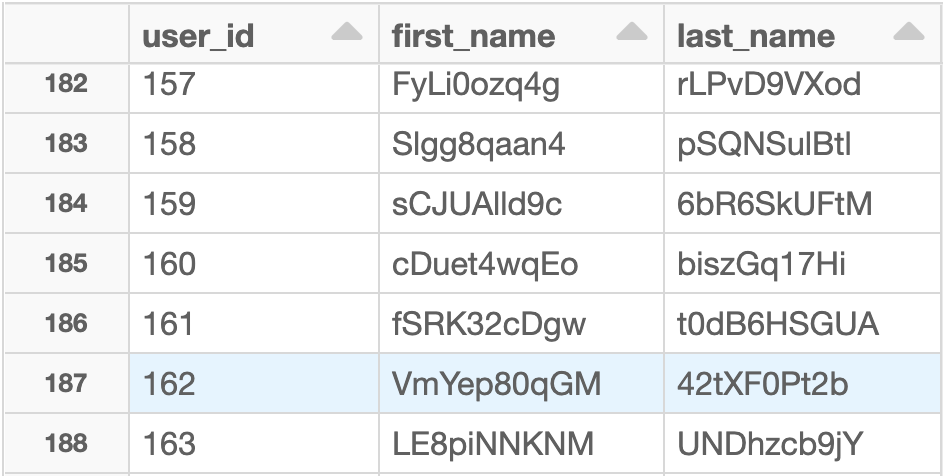
Let’s isolate a particular event #29. Looking at `streaming_pipeline_errors` logs, it can be seen that this event was retried two times before it was successfully joined with corresponding dimensions.

When these error logs are consolidated to a single row in reconciliation table:

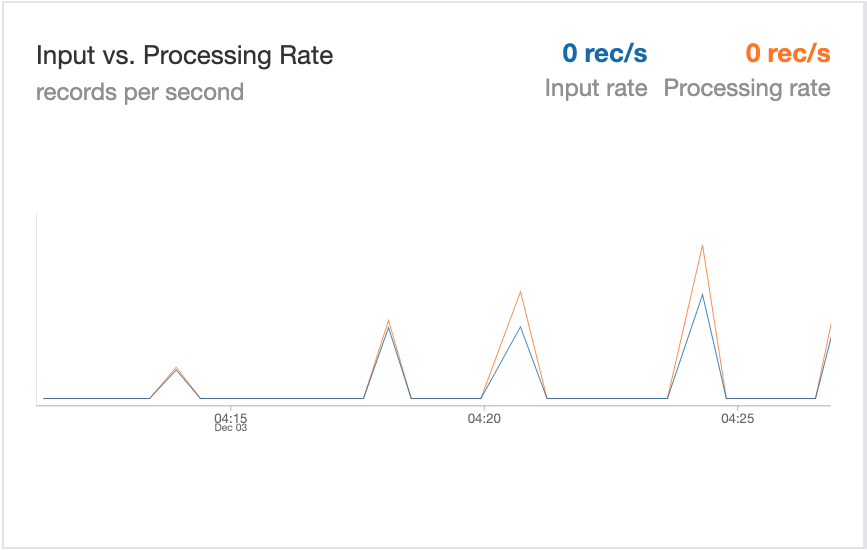
A spike in records processed here indicates that more and more retryable records were getting accumulated faster than they were getting resolved. It indicates a potential issue in a batch job that loads dimensions. Once retries are exhausted or all events are processed, this spike will reduce. The best way to optimize this is to partition the reconciliation table on the `status` column so that you are only reading unresolved records.
Conclusion
This reconciliation pattern becomes easy enough to plug into the existing pipelines once a tiny boilerplate framework is added on top of it. It works with both streaming and batch ETLs. In streaming, it relies on the checkpoint state to read new data from the reconciliation table. Whereas in batch mode, it has to rely on the latest timestamp to keep track of new data. The best way of doing this would be to use streams with Trigger--once.
This automated reconciliation saves a lot of manual effort. You can also add alerting and monitoring on top of it. The volume of retryable data can become a performance overhead as it grows over time. It's better to periodically clean those tables to get rid of older unwanted error logs and keep their size minimal.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.