Lakehouse Architecture Realized: Enabling Data Teams With Faster, Cheaper and More Reliable Open Architectures
by Ryan Boyd
Databricks was founded under the vision of using data to solve the world’s toughest problems. We started by building upon our open source roots in Apache Spark™ and creating a thriving collection of projects, including Delta Lake, MLflow, Koalas and more. We’ve now built a company with over 1,500 employees helping thousands of data teams with data analytics, data engineering, data science and AI.
This year has been especially challenging for the world, with the COVID-19 epidemic affecting everyone around the globe. We’ve seen the potential of data realized to help with vaccine research and clinical trials, healthcare delivery, hospital patient allocation, disease-spread prediction and more. We hope the challenges brought by 2021 are less intense but still trust that data teams will be at the forefront of solving them.
Lakehouse Architecture
At the beginning of the year, we published a blog post analyzing a trend we’ve been seeing: the move towards the Lakehouse architecture. This architecture, based on open formats, combines the flexibility of data lakes built on low-cost cloud object stores with the ACID transactions, schema enforcement and performance typically associated with data warehouses. While Delta Lake, one of the key open source technologies enabling the Lakehouse architecture, was launched in 2019, advancements in Delta Lake, Apache Spark and the Databricks Unified Analytics Platform have continued to increase the capabilities and performance of the data Lakehouse architecture. You can read more about the underlying technical challenges in our VLDB research paper Delta Lake: High-Performance ACID Storage over Cloud Object Stores and our CIDR paperLakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics.
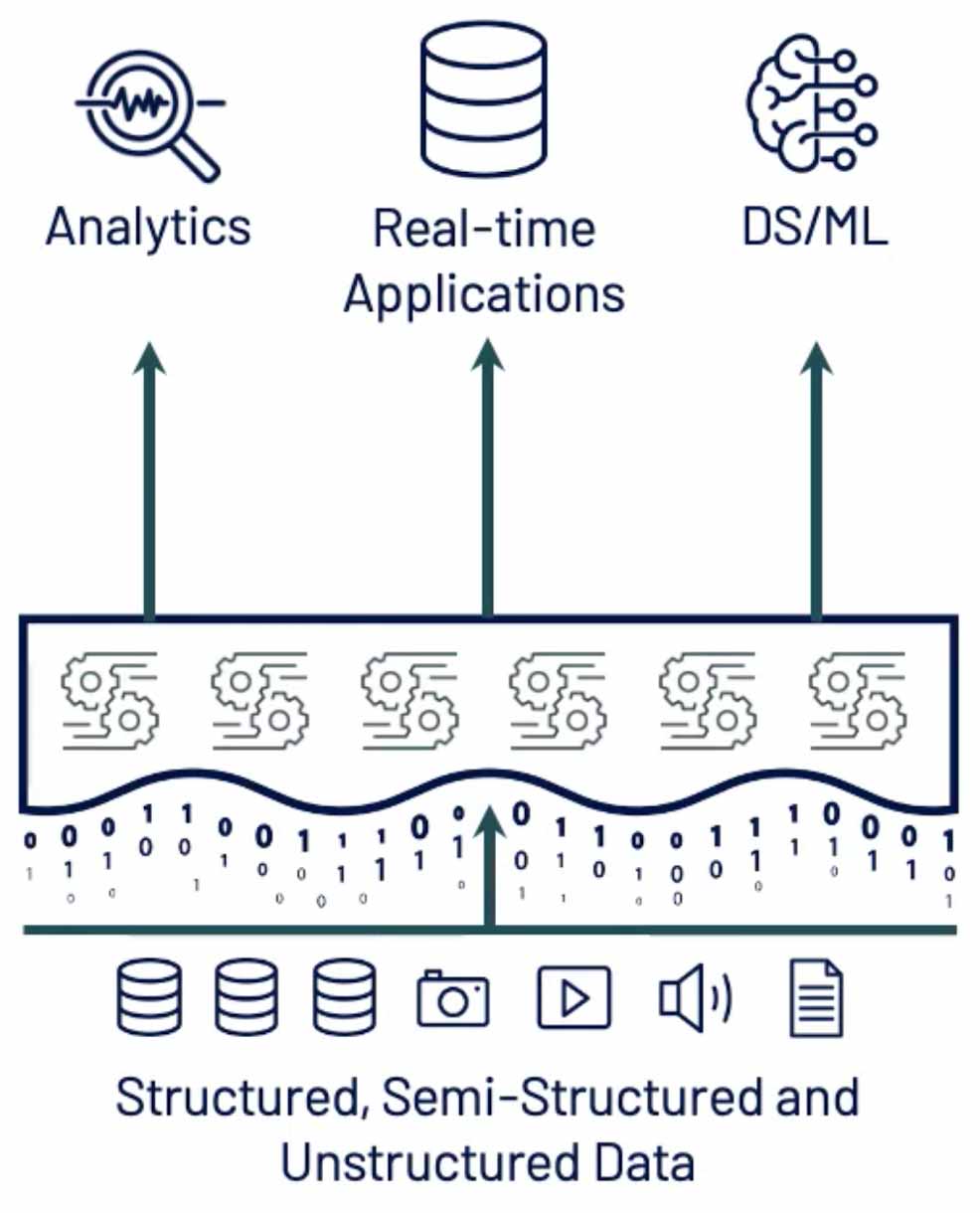
At the beginning of 2020, there was still a significant gap in the tech stack though: high-performance SQL execution to enable decision-making, analytics, business intelligence (BI), and dashboarding workloads on top of the Lakehouse. This gap existed in two forms: underlying query processing engine performance and a UI to simplify analytics for the average data analyst. Throughout the year, we focused on filling these gaps.
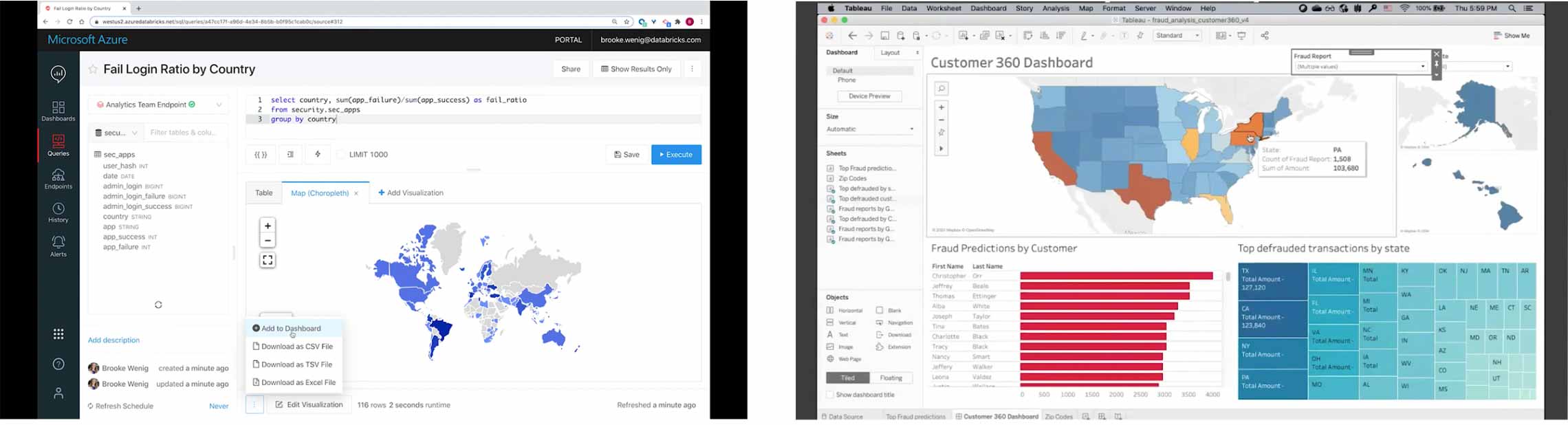
The result of this work was showcased in the November Data + AI Summit Europe keynotes -- the new SQL Analytics product enabling low latency, competitive price/performance and high concurrency access to your data lake. Under-the-hood, SQL Analytics takes advantage of Delta Engine, which combines the Spark 3.0 vectorized query engine with Databricks enhancements to the query optimization and caching layers. It also includes a web UI that makes it easy for BI teams to query, visualize and dashboard massive amounts of data. Of course, it also supports all your favorite data tools, like Power BI and Tableau so that your existing tools and processes can immediately start using the data lake as the data source.
We believe that this focus on improving performance and enabling data warehousing workloads on data lakes led Gartner to name us a Visionary in the 2020 Gartner Magic Quadrant for Cloud Database Management Systems (DBMS).
To learn more about the Lakehouse architecture capabilities, the enabling technologies and the history that led us to this point, watch our new Data Brew vidcast series.
Open Source Enabling the Lakehouse
Many important advances in the Delta Lake and Apache Spark open source projects have enabled us to realize the Lakehouse architecture, as mentioned earlier. An important milestone happened this year for the community building these open source projects: we celebrated the 10th anniversary of the open source release of Apache Spark and the launch of Spark 3.0, which provides 2x performance improvements and better support for Python and SQL- the most popular interfaces to Spark.
In particular, Project Zen has led to significant Python usability improvements, including better PySpark documentation, PySpark type hints, standardized warnings and exceptions, Pandas UDF enhancements—and more improvements are on the way.
Learn about the Spark 3.0 enhancements and more in the newly-published Learning Spark 2nd Edition from O’Reilly, which is available for free as an ebook.

Of course, the Lakehouse is about more than just having a reliable, authoritative data store for big data analytics and great data engineering infrastructure unifying real-time streaming and batch data. The Lakehouse is also about how you take advantage of the structured and unstructured data stored in the data lake. The ability to easily apply machine learning algorithms, perform data science and use artificial intelligence (AI) on top of the Lakehouse is an important characteristic of the architecture, so it also benefits from advances in projects such as MLflow and Koalas.
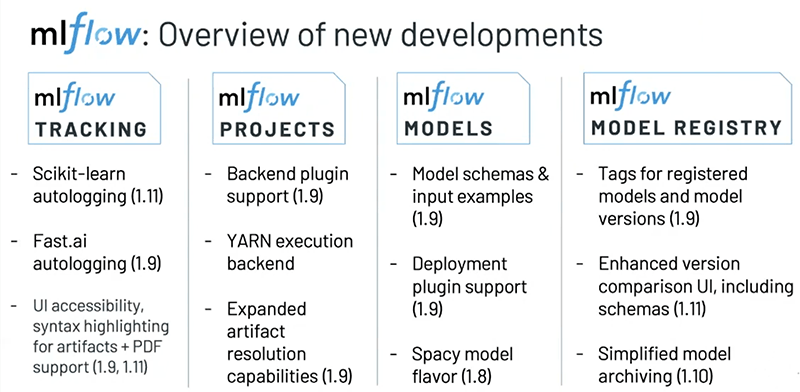
MLflow, which joined the Linux Foundation this year, released the model registry, making it easier to version models and transition them through their complete lifecycle. The team has also focused on simplicity of development with UI improvements, including syntax highlighting, as well as integration with popular libraries such as scikit-learn, Spacy models, and PyTorch. The PyTorch work was done in collaboration with the PyTorch team at Facebook and discussed in depth at the Data + AI Summit Europe.
They’ve also released support for MLflow plugins to seamlessly integrate third-party code and infrastructure with MLflow. The community has come together and written a variety of plugins, including an ElasticSearch backend for tracking, model deployment to RedisAI, project execution on YARN, artifact storage on SQL Server + Alibaba Cloud OSS and more.
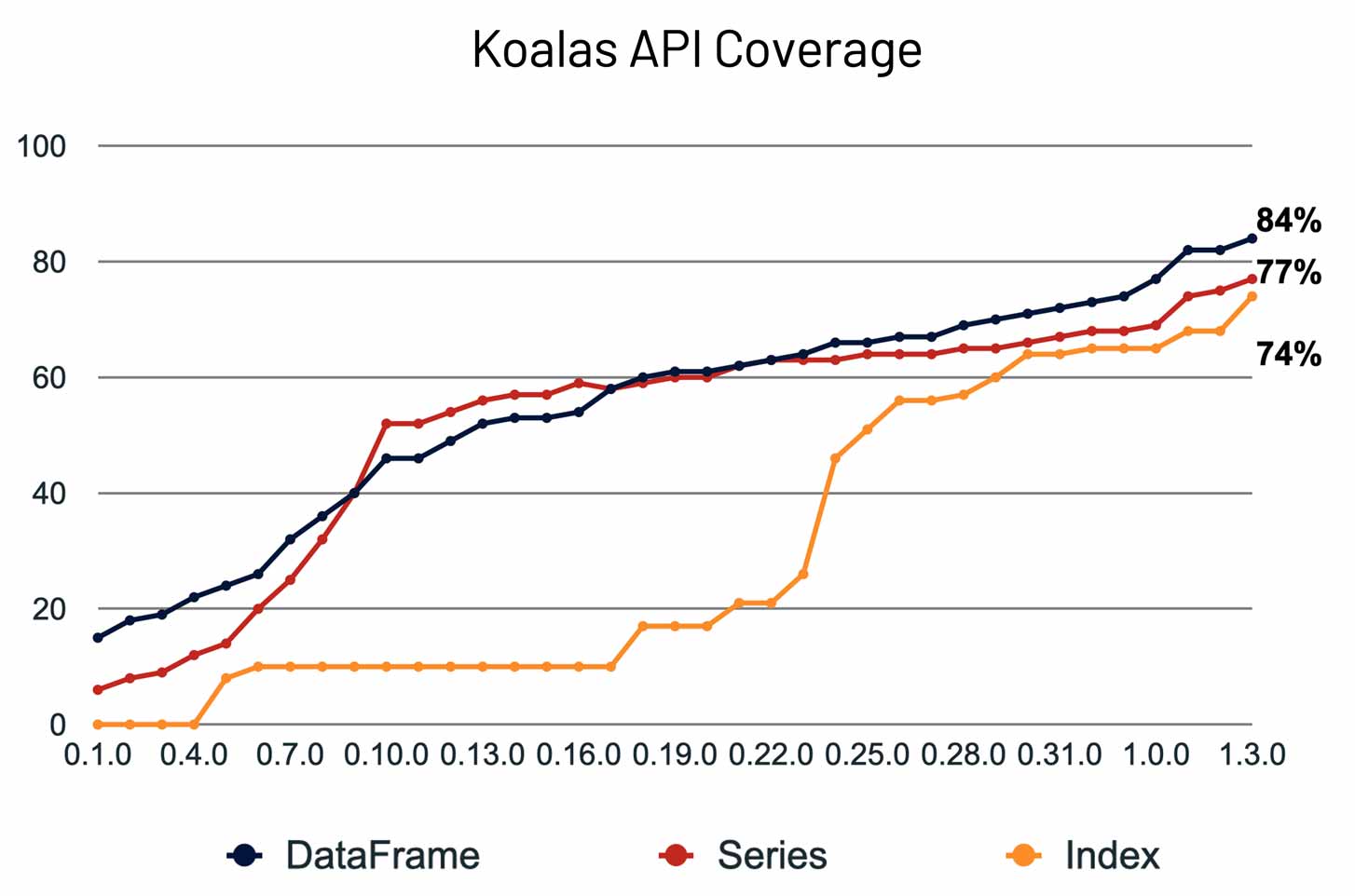
Koalas is an open source project that continues to simplify the experience for Python developers and data scientists to achieve high-scale analysis. Koalas provides a drop-in replacement for pandas, enabling efficient scaling out to hundreds of worker nodes for everyday data science and machine learning. After over one year of development, Koalas 1.0 was released this summer, quickly followed by several other big releases, culminating in Koalas 1.5 in December. Recent releases have achieved close to 85% coverage of the pandas APIs and significantly faster performance by building upon Spark 3.0 APIs.
Data + AI Community
Over the last ten years, data analysts, data scientists and others have joined the Spark community and are working in teams to solve complex data challenges. Born out of this community are key open source technologies such as Delta Lake, MLflow, Redash and Koalas – all of which are growing rapidly. This, in addition to the evolution of Databricks, led to the expansion of the content and community around Spark + AI Summit to be the Data + AI Summit, with almost 10,000 data practitioners joining the inaugural European event this past November.
This has truly been a year spent online for the community, with 44 Data + AI Online Meetups, spanning data science, data engineering, data analytics and more. Some of the more popular series include: Getting Started with Delta Lake tech talks, Diving into Delta Lake internals tech talks, the Introduction to Data Analysis for Aspiring Data Scientists workshops, and the Managing the Machine Learning Lifecycle with MLflow workshops.
The global academic community has overcome some major challenges this year in the switch to online learning (aka “Zoom School”). We’ve been honored to be able to support this transition in a small way through our new University Alliance with over 100 universities joining to share best practices, access self-paced courses and workshops and enable students to practice their skills in the cloud on the Databricks Unified Analytics Platform.
On to 2021
We expect this year to be very exciting as data practitioners and for Databricks as a company. As more and more companies adopt the open data Lakehouse architecture pattern, we look forward to working with them to simplify the journey towards solving the world’s toughest problems. Keep an eye out on this blog and on our YouTube channel to hear more stories about the accomplishments of your fellow data teams and to learn about the technology advancements that simplify and improve your work in data science, data engineering, data analytics and machine learning.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.