Building a Cybersecurity Lakehouse for CrowdStrike Falcon Events
by Aemro Amare, Arun Pamulapati, Yong Sheng Huang and Jason Pohl
Get started now in your own Databricks deployment and run these notebooks.
Endpoint data is required by security teams for threat detection, threat hunting, incident investigations and to meet compliance requirements. The data volumes can be terabytes per day or petabytes per year. Most organizations struggle to collect, store and analyze endpoint logs because of the costs and complexities associated with such large data volumes. But it doesn't have to be this way.
In this two part blog series we will cover how you can operationalize petabytes of endpoint data with Databricks to improve your security posture with advanced analytics, in a cost effective way. Part 1 (this blog) will cover the architecture of data collection and the integration with a SIEM (Splunk). At the end of this blog with notebooks provided you will be ready to use the data for analysis. Part 2 will discuss specific use cases, how to create ML models and automated enrichments and analytics. At the end of part 2, you will be able to implement the notebooks to detect and investigate threats using end point data.
We will use Crowdstrike’s Falcon logs as our example. To access Falcon logs, one can use the Falcon Data Replicator (FDR) to push raw event data from CrowdStrike’s platform to cloud storage such as Amazon S3. This data can be ingested, transformed, analyzed and stored using the Databricks Lakehouse Platform alongside the rest of their security telemetry. Customers can ingest CrowdStrike Falcon data, apply Python-based real-time detections, search through historical data with Databricks SQL, and query from SIEM tools like Splunk with Databricks Add-on for Splunk.
Challenge of operationalizing Crowdstrike data
Although the Crowdstrike Falcon data offers comprehensive event logging details, it is a daunting task to ingest, process and operationalize complex and large volumes of cybersecurity data on a near real-time basis in a cost-effective manner. These are a few of the well-known challenges:
- Real-time data ingestion at scale: It is difficult to keep track of processed and unprocessed raw data files, which are written by FDR on cloud storage in near real time.
- Complex transformations: The data format is semi-structured. Every line of each log file contains hundreds of underministically different types of payloads, and the structure of event data can change over time.
- Data governance: This kind of data can be sensitive, and access must be gated to only users who need it.
- Simplified security analytics end-to-end: Scalable tools are needed to do the data engineering, MLand analysis on these fast-moving and high-volume datasets.
- Collaboration: Effective collaboration can leverage domain expertise from the data engineers, cybersecurity analysts and ML engineers. Thus, having a collaborative platform improves the efficiency of cybersecurity analysis and response workloads.
As a result, security engineers across enterprises find themselves in a difficult situation struggling to manage cost and operational efficiency. They either have to accept being locked into very expensive proprietary systems or spend tremendous efforts to build their own endpoint security tools while fighting for scalability and performance.
Databricks cybersecurity lakehouse
Databricks offers security teams and data scientists a new hope to perform their jobs efficiently and effectively, as well as a set of tools to combat the growing challenges of big data and sophisticated threats.
Lakehouse, an open architecture that combines the best elements of data lakes and data warehouses, simplifies building a multi-hop data engineering pipeline that progressively adds structure to the data. The benefit of a multi-hop architecture is that data engineers can build a pipeline that begins with raw data as a “single source of truth” from which everything flows. Crowstrike’s semi-structured raw data can be stored for years, and subsequent transformations and aggregations can be done in an end-to-end streaming fashion to refine the data and introduce context-specific structure to analyze and detect security risks in different scenarios.
- Data ingestion: Autoloader (AWS | Azure | GCP) helps to immediately read data as soon as a new file is written by Crowdstrike FDR into raw data storage. It leverages cloud notification services to incrementally process new files as they arrive on the cloud. Autoloader also automatically configures and listens to the notification service for new files and can scale up to millions of files per second.
- Unified stream and batch processing: Delta Lake is an open approach to bringing data management and governance to data lakes that leverages Apache Spark’s™ distributed computation power for huge volumes of data and metadata. Databricks’s Delta Engine is a highly-optimized engine that can process millions of records per second.
- Data governance: With Databricks Table Access Control (AWS | Azure | GCP), admins can grant different levels of access to delta tables based on a user’s’ business function.
- Security analysis tools: Databricks SQL helps to create an interactive dashboard with automatic alerting when unusual patterns are detected. Likewise, it can easily integrate with highly-adopted BI tools such as Tableau, Microsoft Power BI and Looker.
- Collaboration on Databricks notebooks: Databricks collaborative notebooks enable security teams to collaborate in real time. Multiple users can run queries in multiple languages, share visualizations and make comments within the same workspace to keep investigations moving forward without interruption.
Lakehouse architecture for Crowdstrike Falcon data
We recommend the following lakehouse architecture for cybersecurity workloads, such as Crowdstrike’s Falcon data. Autoloader and Delta Lake simplify the process of reading raw data from cloud storage and writing to a delta table at low cost and minimal DevOps work.
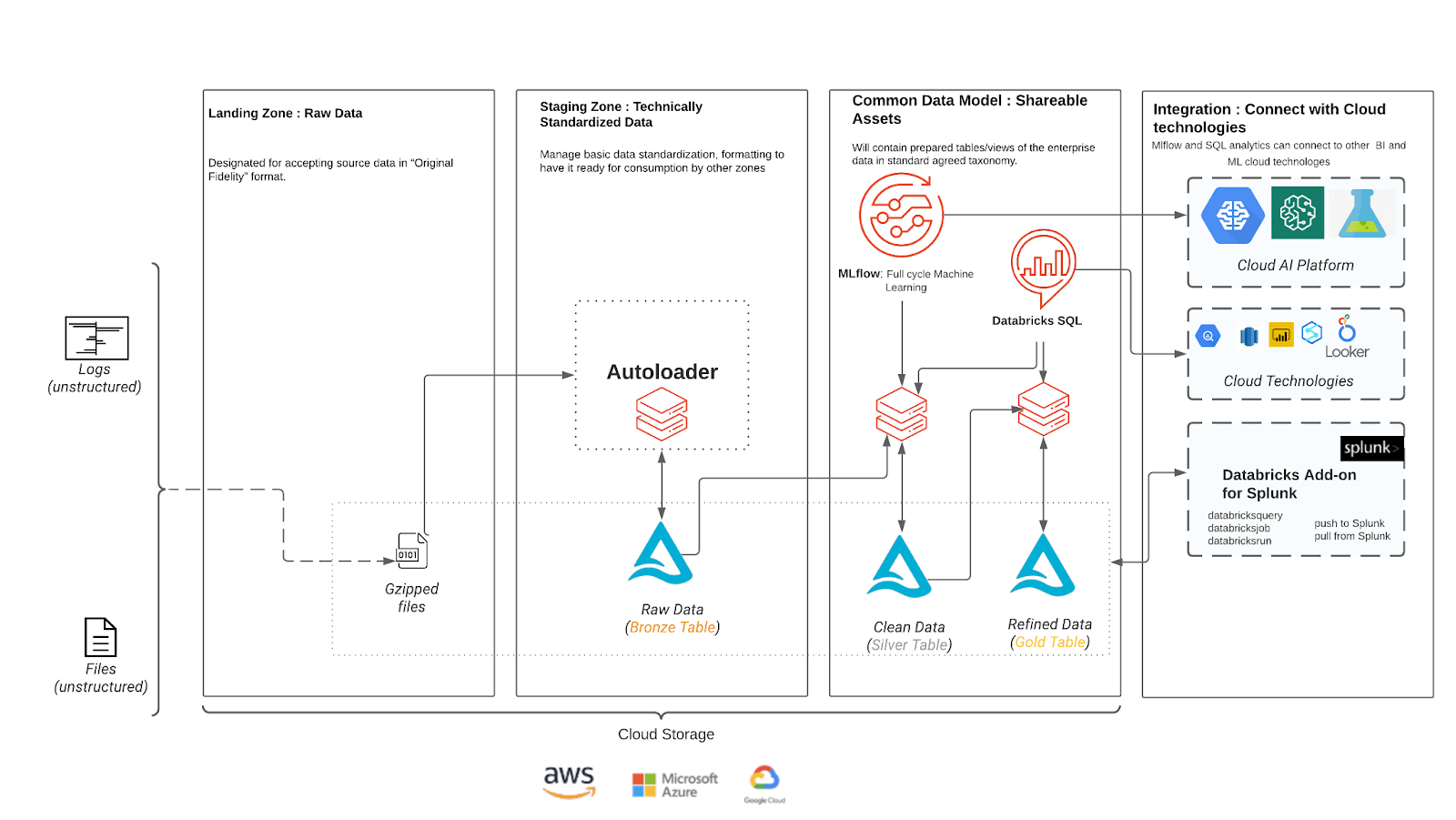
In this architecture, semi-structured Crowdstrike data is loaded to the customer’s cloud storage in the landing zone. Then Autoloader uses cloud notification services to automatically trigger the processing and ingestion of new files into the customer's bronze tables, which will act as the single source of truth for all downstream jobs. Autoloader will track processed and unprocessed files using checkpoints in order to prevent duplicate data processing.
As we move from the bronze-to-silver stage, schema will be added to provide structure to the data. Since we are reading from a single source of truth, we are able to process all of the different event types and enforce the correct schema as they are written to their respective tables. The ability to enforce schemas at the Silver layer provides a solid foundation for building ML and analytical workloads.
The gold stage, which aggregates data for faster query and performance in dashboards and BI tools, is optional, depending on the use case and data volumes. Alerts can be set to trigger when unexpected trends are observed.
Another optional feature is the Databricks Add-on for Splunk, which allows security teams to take advantage of Databricks’ cost-effective model and the power of AI without having to leave the comforts of Splunk. Customers can run ad-hoc queries against Databricks from within a Splunk dashboard or search bar with the add-on. Users can also launch notebooks or jobs in Databricks through a Splunk dashboard or in response to a Splunk search. The Databricks integration is bi-directional, letting customers summarize noisy data or run detections in Databricks that show up in Splunk Enterprise Security. Customers can even run Splunk searches from within a Databricks notebook to prevent the need to duplicate data.
The Splunk and Databricks integration allows customers to reduce costs, expand the data sources they analyze and provide the results of a more robust analytics engine, all without changing the tools used by their staff day-to-day.
Code walkthrough
Since Autoloader abstracts the most complex part of file-based data ingestion, raw-to-bronze ingestion pipeline can be created within a few lines of code. Below is a Scala code example for a Delta ingestion pipeline. Crowdstrike Falcon event records have one common field name: “event_simpleName.”
In the raw-to-bronze layer, only the event name is extracted from the raw data. By adding a load timestamp and date columns, users store the raw data into the bronze table. The bronze table is partitioned by event name and load date, which helps to make bronze-to-silver jobs more performant, especially when there is interest for a limited number of event date ranges.
Next, a bronze-to-silver streaming job reads events from a bronze table, enforces a schema and writes to hundreds of event tables based on the event name. Below is a Scala code example:
Each event schema can be stored in a schema registry or in a Delta table in case a schema needs to be shared across multiple data-driven services. Note that the above code uses a sample json string read from the bronze table, and the schema is inferred from the json using schema_of_json(). Later, the json string is converted to a struct using from_json(). Then, the struct flattened, prompting the addition of a timestamp column. These steps provide a dataframe with all the required columns to be appended to an event table. Finally, we write this structured data to an event table with append mode.
It is also possible to fan out events to multiple tables with one stream with foreachBatch by defining a function that will handle microbatches. Using foreachBatch(), it is possible to reuse existing batch data sources for filtering and writing to multiple tables. However, foreachBatch() provides only at-least-once write guarantees. So, a manual implementation is needed to enforce exactly-once semantics.
At this stage, the structured data can be queried with any of the languages supported in Databricks notebooks and jobs: Python, R, Scala and SQL. The silver layer data is convenient to use for ML and Cyberattack analysis.
The next streaming pipeline would be silver-to-gold. In this stage, it is possible to aggregate data for dashboarding and alerting. In the second part of this blog series we will provide some more insights into how we build dashboards using Databricks SQL.
What’s next
Stay tuned for more blog posts that build even more value on this use case by applying ML and using Databricks SQL.
You can use these notebooks in your own Databricks deployment. Each section of the notebooks has comments. We invite you to email us at cybersecurity@databricks.com. We look forward to your questions and suggestions for making this notebook easier to understand and deploy.
Now, we invite you to log in to your own Databricks account and run these notebooks. We look forward to your feedback and suggestions.
Please refer to the docs for detailed instructions on importing the notebook to run.
Acknowledgments
We would like to thank Bricksters who supported this blog, and special thanks to Monzy Merza, Andrew Hutchinson, Anand Ladda for their insightful discussion and contributions.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.