Applying Natural Language Processing to Healthcare Text at Scale
Uncover patient insights buried in medical text with solutions from John Snow Labs and Databricks
This is a co-authored post written in collaboration with Moritz Steller, AI Evangelist, at John Snow Labs. Watch our on-demand workshop, Extract Real-World Data with NLP, to learn more about our NLP solutions for Healthcare.
In 2015, HIMSS estimated that the healthcare industry in the U.S. produced 1.2 billion clinical documents. That’s a tremendous amount of unstructured text data. Since that time, the digitization of healthcare has only increased the amount of clinical text data generated annually. Digital forms, online portals, pdf reports, emails, text messages and chatbots all provide the backbone for modern healthcare communications. The amount of text generated across these channels is too vast to measure and too comprehensive for a human to consume. And because these datasets are unstructured, they are not readily analyzable and often remain siloed.
This poses a risk for all healthcare organizations. Locked within these lab reports, provider notes and chat logs is valuable information. When combined with a patient’s electronic health record (EHR), these data points provide a more complete view of a patient’s health. At a population level, these datasets can inform drug discovery, treatment pathways, and real-world safety assessments.
Uncovering novel health insights with natural language processing
There’s good news. Advancements in natural language processing (NLP) - a branch of artificial intelligence that enables computers to understand written, spoken or image text - make it possible to extract insights from text. Using NLP methods, unstructured clinical text can be extracted, codified and stored in a structured format for downstream analysis and fed directly into machine learning (ML) models. These techniques are driving significant innovations in research and care.
In one use case, Kaiser Permanente, one of the largest nonprofit health plans and healthcare providers in the US, used NLP to process millions of emergency room triage notes to predict the demand for hospital beds, nurses and clinicians, and ultimately improve patient flow. Another study used NLP to analyze non-standard text messages from mobile support groups for HIV-positive adolescents. The analysis found a strong correlation between engagement with the group, improved medication adherence and feelings of social support.
What’s getting in the way of healthcare NLP?
With all this incredible innovation, it begs the question—why aren’t more healthcare organizations making use of their clinical text data? In our experience, working with some of the largest payers, providers and pharmaceutical companies, we see three key challenges:
NLP systems are typically not designed for Healthcare. Clinical text is its own language. The data is inconsistent due to the wide variety of source systems (e.g. EHR, clinical notes, PDF reports) and, on top of that, the language varies greatly across clinical specialties. Traditional NLP technology is not built to understand the unique vocabularies, grammars and intents of medical text. For example, in the text string below, the NLP model needs to understand that azithromycin is a drug, 500 mg is dosage, and that SOB is a clinical abbreviation for “shortness of breath” related to the patient condition pneumonia. It’s also important to infer that the patient is not short of breath, and that they haven’t taken the medication yet since it’s just being prescribed.

Inflexible legacy healthcare data architectures. Text data contain troves of information but only provide one lens into patient health. The real value comes from combining text data with other health data to create a comprehensive view of the patient. Unfortunately, legacy data architectures built on data warehouses lack support for unstructured data—such as scanned reports, biomedical images, genomic sequences and medical device streams — making it impossible to harmonize patient data. Additionally, these architectures are costly and complex to scale. A simple ad hoc analysis on a large corpus of health data can take hours or days to run. That is too long to wait when adjusting for patient needs in real-time.
Lack of advanced analytics capabilities. Most healthcare organizations have built their analytics on data warehouses and BI platforms. These are great for descriptive analytics, like calculating the number of hospital beds used last week, but lack the AI/ML capabilities to predict hospital bed use in the future. Organizations that have invested in AI typically treat these systems as siloed, bolt-on solutions. This approach requires data to be replicated across different systems resulting in inconsistent analytics and slow time-to-insight.
Unlocking the power of healthcare NLP with Databricks and John Snow Labs
Databricks and John Snow Labs - the creator of the open-source Spark NLP library, Spark NLP for Healthcare and Spark OCR - are excited to announce our new suite of solutions focused on helping healthcare and life sciences organizations transform their large volumes of text data into novel patient insights. Our joint solutions combine best-of-breed Healthcare NLP tools with a scalable platform for all your data, analytics, and AI.

Serving as the foundation is the Databricks Lakehouse platform, a modern data architecture that combines the best elements of a data warehouse with the low cost, flexibility and scale of a cloud data lake. This simplified, scalable architecture enables healthcare systems to bring together all their data—structured, semi-structured and unstructured—into a single, high-performance platform for traditional analytics and data science.
At the core of the Databricks Lakehouse platform are Apache SparkTM and Delta Lake, an open-source storage layer that brings performance, reliability and governance to your data lake. Healthcare organizations can land all of their data, including raw provider notes and PDF lab reports, into a bronze ingestion layer of Delta Lake. This preserves the source of truth before applying any data transformations. By contrast, with a traditional data warehouse, transformations occur prior to loading the data, which means that all structured variables extracted from unstructured text are disconnected from the native text.
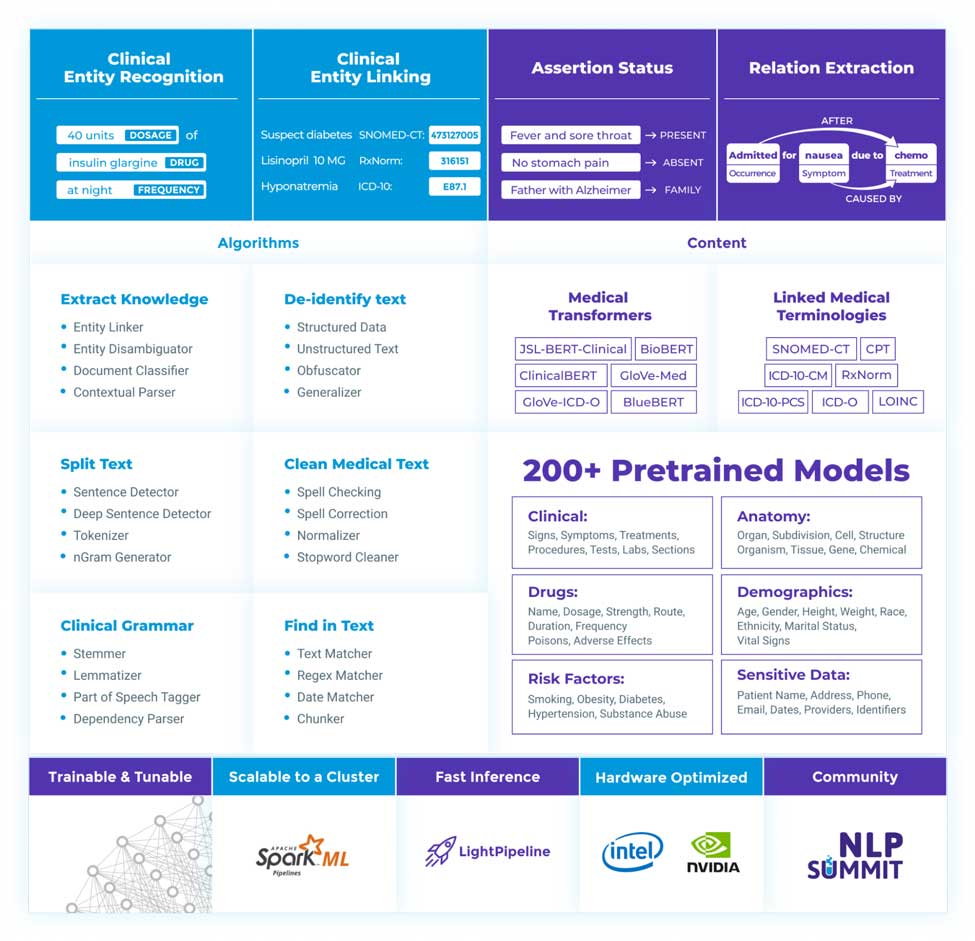
Building on this foundation is John Snow Labs’ Spark NLP for Healthcare, the most widely-used NLP library for healthcare and life science industries. The software seamlessly extracts, classifies and structures clinical and biomedical text data with state-of-the-art accuracy. This is done using production-grade, scalable and trainable implementations of recent healthcare-specific deep learning and transfer learning techniques, together with 200+ pre-trained and regularly updated models.
Notable capabilities of John Snow Labs’ software libraries include:
- Out-of-the-box named entity recognition of over 100 clinical and biomedical entities - from symptoms & drugs to anatomy, social determinants, labs, imaging and genes
- Resolving entities to the semantically nearest code of terminologies including SNOMED-CT, ICD-10-CM, ICD-10-PCS, RxNorm, LOICS, UMLS, MeSH, and HPO.
- Pre-trained relation extraction models to detect 30+ relation types: between medical events, treatments and drugs, genes and phenotypes, and others.
- Customizable detection, de-identification, and obfuscation of sensitive information from free text, PDF documents, scanned reports, and DICOM images.
- Healthcare-specific word, chunk and sentence embeddings that are not available elsewhere and are regularly updated with new terminologies and content.
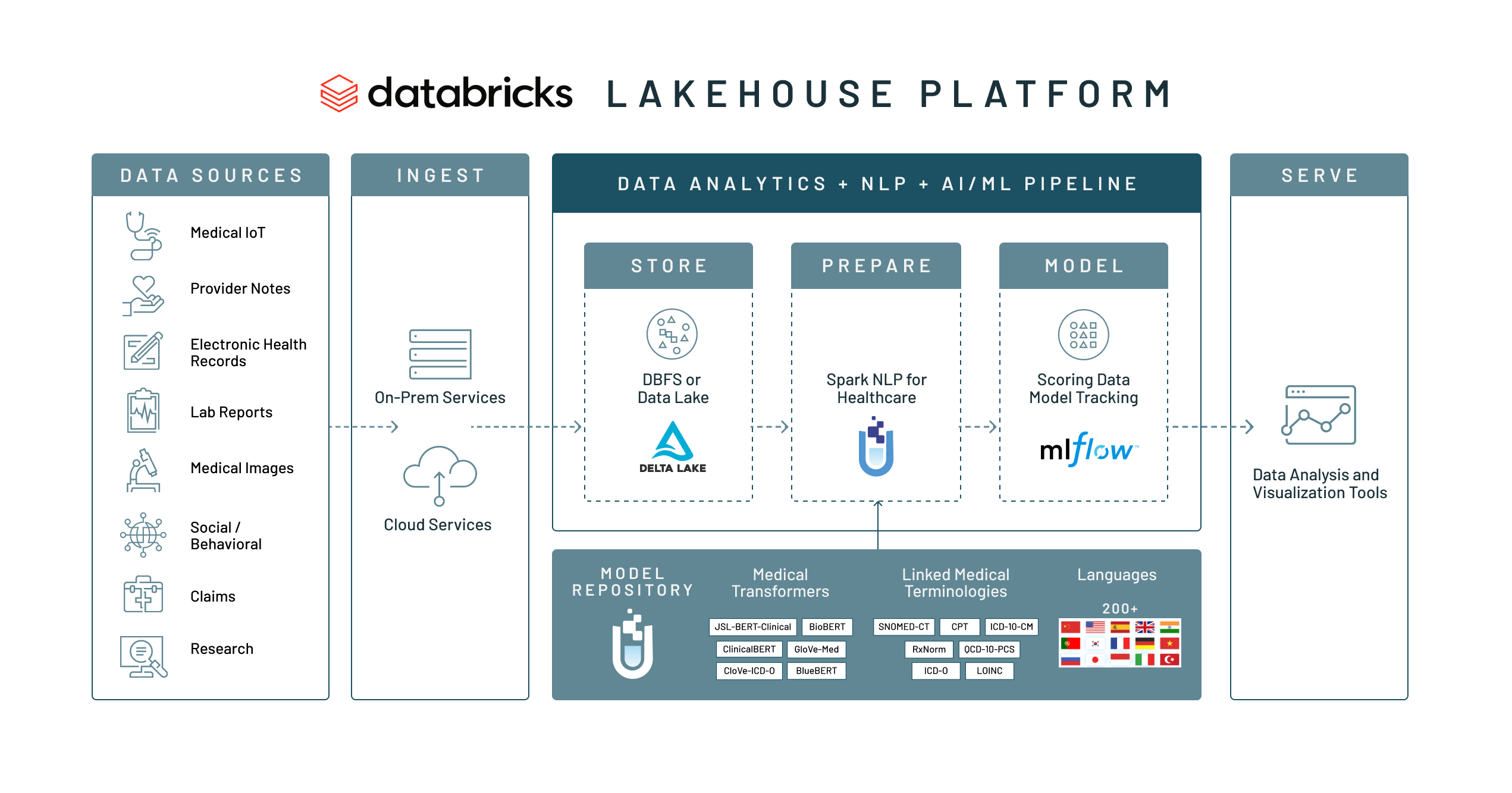
Our joint solutions bring together the power of Spark NLP for Healthcare with the collaborative analytics and AI capabilities of Databricks. Informatics teams can ingest raw data directly into Databricks, process that data at scale with Spark NLP for Healthcare, and make it available for downstream SQL Analytics and ML, all in one platform. Both training and inference processes run directly within Databricks; beyond the benefits of speed and scale, this also means that data is never sent to a third party, a critical privacy and compliance requirement when processing sensitive medical data. Best of all, Databricks is built on Apache SparkTM, making it the best place to run Spark applications like Spark NLP for Healthcare.
Getting started with healthcare natural language processing at scale
- Check out our latest NLP Solution Accelerators for extracting oncology insights from clinical data and adverse drug event detection.
- Download our Healthcare NLP solution sheet for more information
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.