AML Solutions at Scale Using Databricks Lakehouse Platform
by Sri Ghattamaneni, Ricardo Portilla and Anindita Mahapatra
Anti-Money Laundering (AML) compliance has been undoubtedly one of the top agenda items for regulators providing oversight of financial institutions across the globe. As AML evolved and became more sophisticated over the decades, so have the regulatory requirements designed to counter modern money laundering and terrorist financing schemes. The Bank Secrecy Act of 1970 provided guidance and framework for financial institutions to put in proper controls to monitor financial transactions and report suspicious fiscal activity to relevant authorities. This law provided set the framework for how financial institutes combat money laundering and financial terrorism.
Why anti-money laundering is so complex
Current AML operations bear little resemblance to those of the last decade. The shift to digital banking, with financial institutions (FI's) processing billions of transactions daily, has resulted in the ever increasing scope of money laundering, even with stricter transaction monitoring systems and robust Know Your Customer (KYC) solutions. In this blog, we share our experiences working with our FI customers to build enterprise-scale AML solutions on the lakehouse platform that both provides strong oversight and delivers innovative, scalable solutions to adapt to the reality of modern online money laundering threats.
Building an AML solution with lakehouse
The operational burden of processing billions of transactions a day comes from the need to store the data from multiple sources and power intensive, next-gen AML solutions. These solutions provide powerful risk analytics and reporting while supporting the use of advanced machine learning models to reduce false positives and improve downstream investigation efficiency. FIs have already taken steps to solve the infrastructure and scaling problems by moving from on-premises to cloud for better security, agility and the economies of scale required to store massive amounts of data.
But then there is the issue of how to make sense of the massive amounts of structured and unstructured data collected and stored on cheap object storage. While cloud vendors provide an inexpensive way to store the data, making sense of the data for downstream AML risk management and compliance activities starts with storage of the data in high-quality and performant formats for downstream consumption. The Databricks Lakehouse Platform does exactly this. By combining the low storage cost benefits of data lakes with the robust transaction capabilities of data warehouses, FIs can truly build the modern AML platform.
On top of the data storage challenges outlined above, AML analysts face some key domain-specific challenges:
- Improve time-to-value parsing unstructured data such as images, textual data and network links
- Reduce DevOps burden for supporting critical ML capabilities such as entity resolution, computer vision and graph analytics on entity metadata
- Break down silos by introducing analytics engineering and dashboarding layer on AML transactions and enriched tables
Luckily, Databricks helps solve these by leveraging Delta Lake to store and combine both unstructured and structured data to build entity relationships; moreover, Databricks' Delta engine provides efficient access using the new Photon compute to speed up BI queries on tables. On top of these capabilities, ML is a first-class citizen in lakehouse, which means analysts and data scientists do not waste time subsampling or moving data to share dashboards and stay one-step ahead of bad actors.
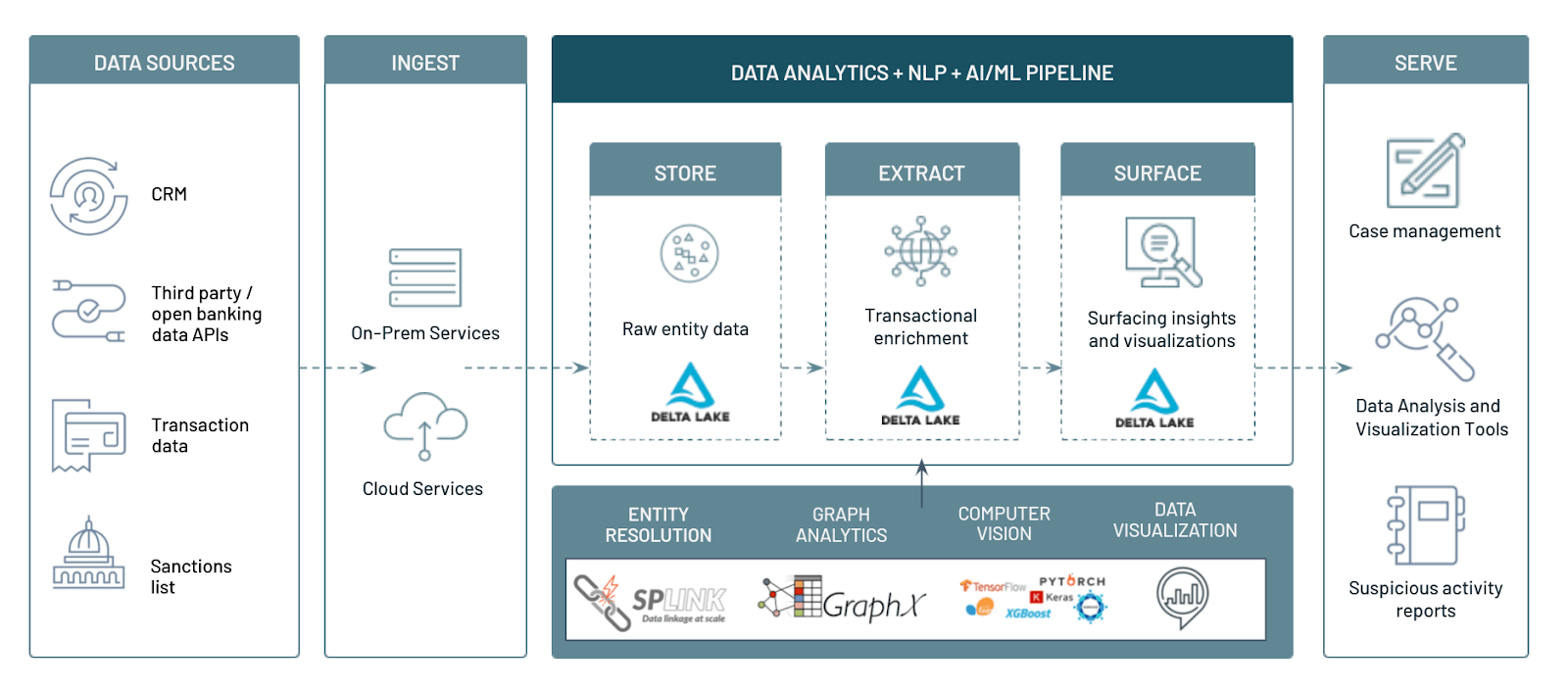
Detecting AML patterns with graph capabilities
One of the main data sources that AML analysts use as part of a case is transaction data. Even though this data is tabular and easily accessible with SQL, it becomes cumbersome to track chains of transactions that are three or more layers deep with SQL queries. For this reason, it is important to have a flexible suite of languages and APIs to express simple concepts such as a connected network of suspicious individuals transacting illegally together. Luckily, this is simple to accomplish using GraphFrames, a graph API pre-installed in the Databricks Runtime for Machine Learning.
In this section, we will show how graph analytics can be used to detect AML schemes such as synthetic identity and layering / structuring. We are going to utilize a dataset consisting of transactions, as well as entities derived from transactions, to detect the presence of these patterns with Apache Spark™, GraphFrames and Delta Lake. The persisted patterns are saved in Delta Lake so that Databricks SQL can be applied on the gold-level aggregated versions of these findings, offering the power of graph analytics to end-users.
Scenario 1 -- Synthetic identities
As mentioned above, the existence of synthetic identities can be a cause for alarm. Using graph analysis, all of the entities from our transactions can be analyzed in bulk to detect a risk level. In our analysis, this is done in three phases:
- Based on the transaction data, extract the entities
- Create links between entities based on address, phone number or email
- Use GraphFrames connected components to determine whether multiple entities (identified by an ID and other attributes above) are connected via one or more links.
Based on how many connections (i.e. common attributes) exist between entities, we can assign a lower or higher risk score and create an alert based on high-scoring groups. Below is a basic representation of this idea.
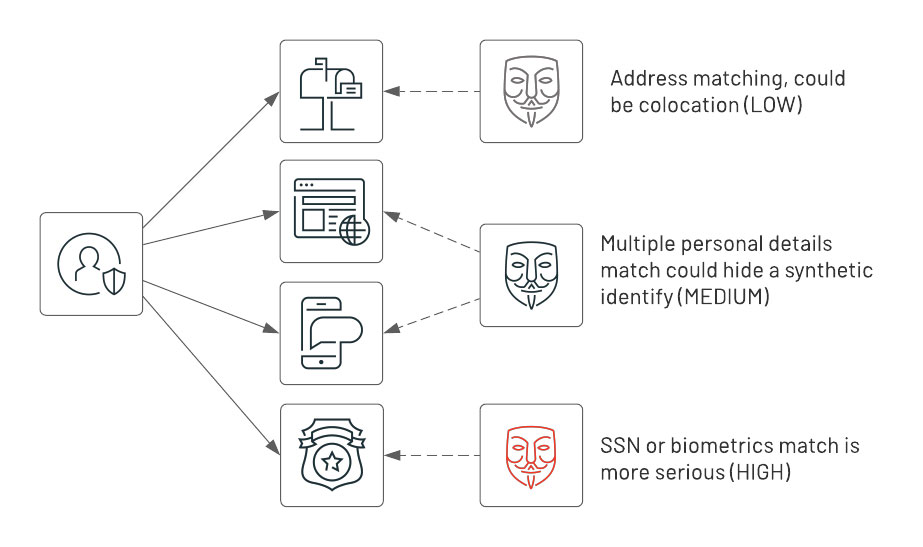
First, we create an identity graph using an address, email and phone number to link individuals if they match any of these attributes.
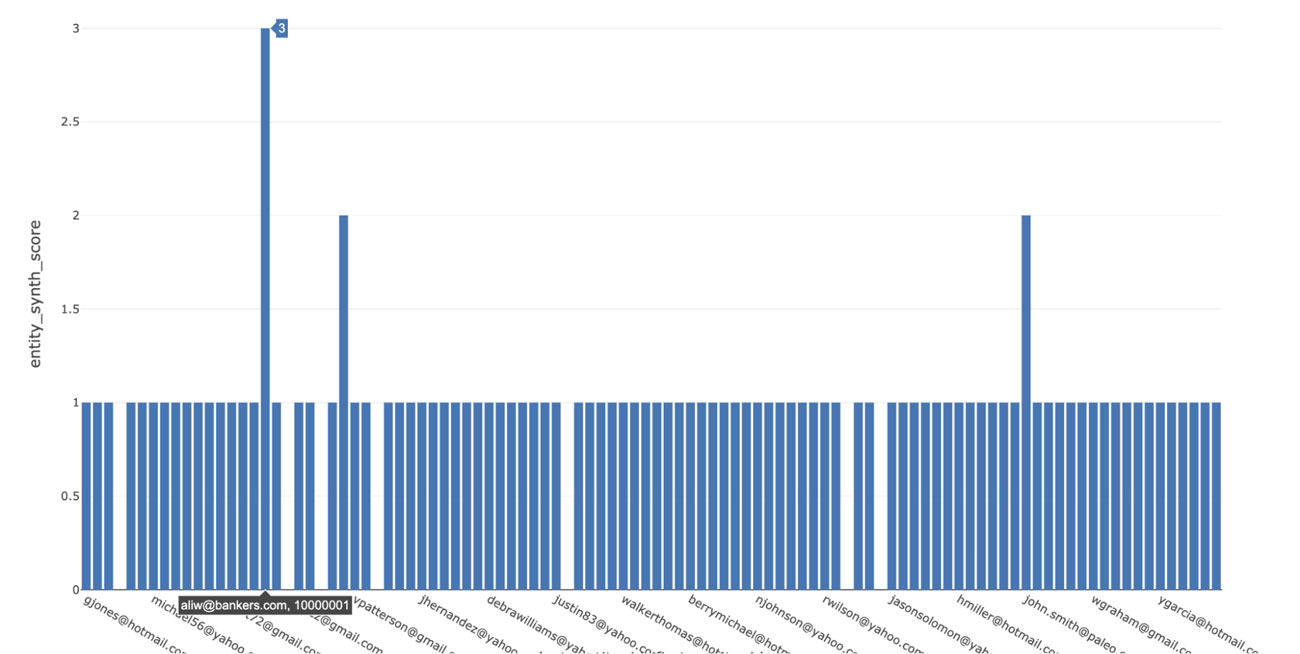
Next, we'll run queries to identify when two entities have overlapping personal identification and scores. Based on the results of these querying graph components, we would expect a cohort consisting of only one matching attribute (such as address), which isn't too much cause for concern. However, as more attributes match, we should expect to be alerted. As shown below, we can flag cases where all three attributes match, allowing SQL analysts to get daily results from graph analytics run across all entities.
Scenario 2 - Structuring
Another common pattern is called structuring, which occurs when multiple entities collude and send smaller 'under the radar' payments to a set of banks, which subsequently route larger aggregate amounts to a final institution (as depicted below on the far right). In this scenario, all parties have stayed under the $10,000 threshold amount, which would typically alert authorities. Not only is this easily accomplished with graph analytics, but the motif finding technique can be automated to extend to other permutations of networks and locate other suspicious transactions in the same way.
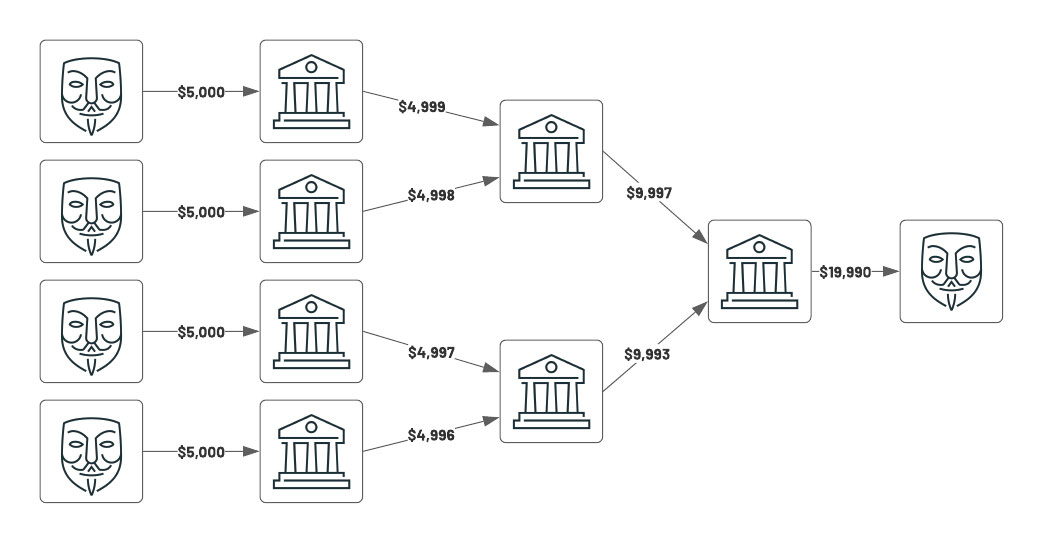
Now we'll write the basic motif-finding code to detect the scenario above using graph capabilities. Note that the output here is semi-structured JSON; all data types, including unstructured types, are easily accessible in the lakehouse -- we will save these particular results for SQL reporting.
Using motif finding, we extracted interesting patterns where money is flowing through 4 different entities and kept under a $10,000 threshold. We join our graph metadata back to structured datasets to generate insights for an AML analyst to investigate further.

Scenario 3 -- Risk score propagation
The identified high-risk entities will have an influence (a network effect) on their circle. So, the risk score of all the entities that they interact with must be adjusted to reflect the zone of influence. Using an iterative approach, we can follow the flow of transactions to any given depth and adjust the risk scores of others affected in the network. As mentioned previously, running graph analytics avoids multiple repeated SQL joins and complex business logic, which can impact performance due to memory constraints. Graph analytics and Pregel API was built for that exact purpose. Initially developed by Google, Pregel allows users to recursively "propagate" messages from any vertex to its corresponding neighbours, updating vertex state (their risk score here) at each step. We can represent our dynamic risk approach using Pregel API as follows.
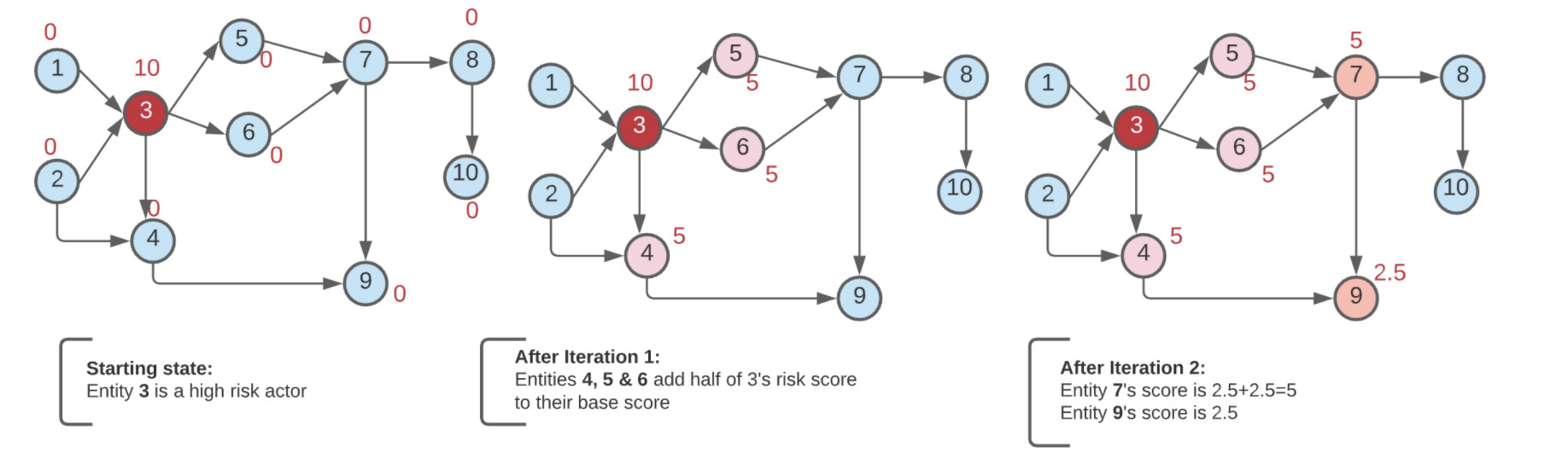
The diagram above shows the starting state of the network and two subsequent iterations. Say we started with one bad actor (Node# 3) with a risk score of 10. We want to penalize all the people who transact with that node (namely Nodes 4, 5 and 6) and receive funds by passing on, for instance, half the risk score of the bad actor, which then is added to their base score. In the next iteration, all nodes that are downstream from Nodes 4, 5, 6 will get their scores adjusted.
| Node # | Iteration #0 | Iteration #1 | Iteration #2 |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 |
| 3 | 10 | 10 | 10 |
| 4 | 0 | 5 | 5 |
| 5 | 0 | 5 | 5 |
| 6 | 0 | 5 | 5 |
| 7 | 0 | 0 | 5 |
| 8 | 0 | 0 | 0 |
| 9 | 0 | 0 | 2.5 |
| 10 | 0 | 0 | 0 |
Using the Pregel API from GraphFrame, we can do this computation and persist the modified scores for other applications downstream to consume.
Address matching
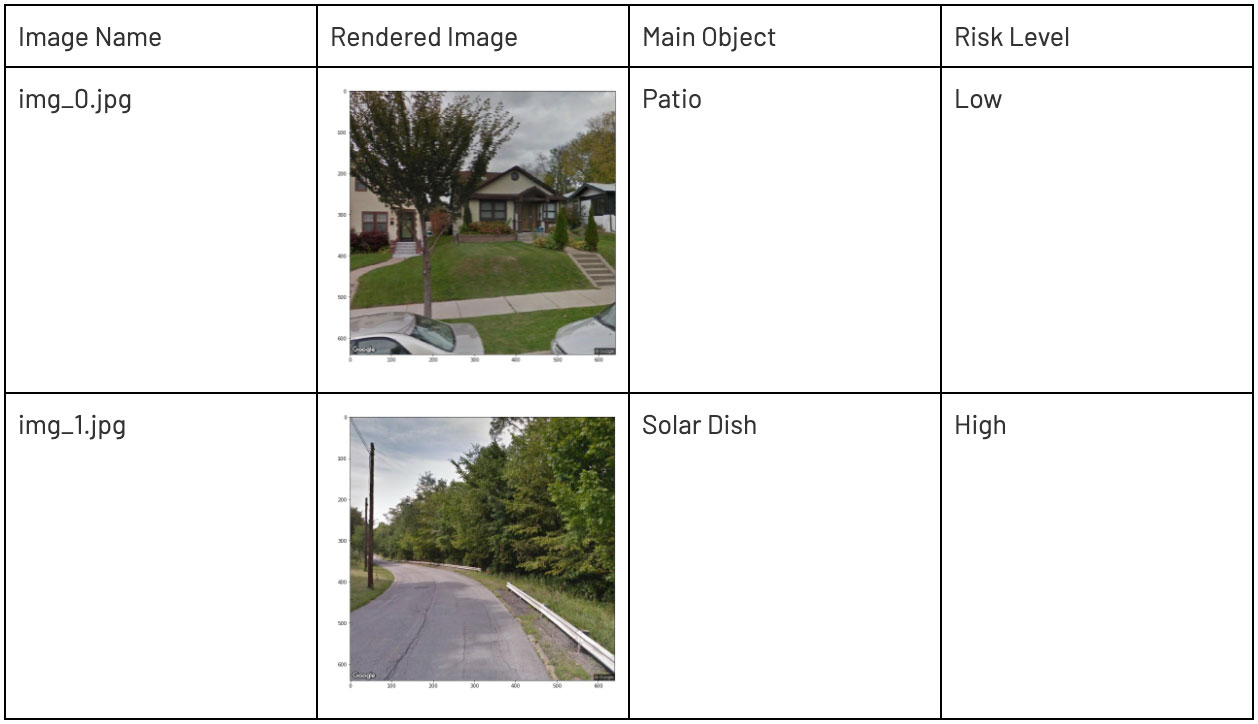
A pattern we want to briefly touch upon is address matching of text to actual street view images. Oftentimes, there is a need for an AML analyst to validate the legitimacy of addresses that are linked to entities on file. Is this address a commercial building, a residential area or a simple postbox? However, analysing pictures is often a tedious, time-consuming and manual process to obtain, clean and validate. A lakehouse data architecture allows us to automate most of this task using Python and ML runtimes with PyTorch and pre-trained open-source models. Below is an example of a valid address to the human eye. To automate validation, we will use a pre-trained VGG model for which there are hundreds of valid objects we can use to detect a residence.

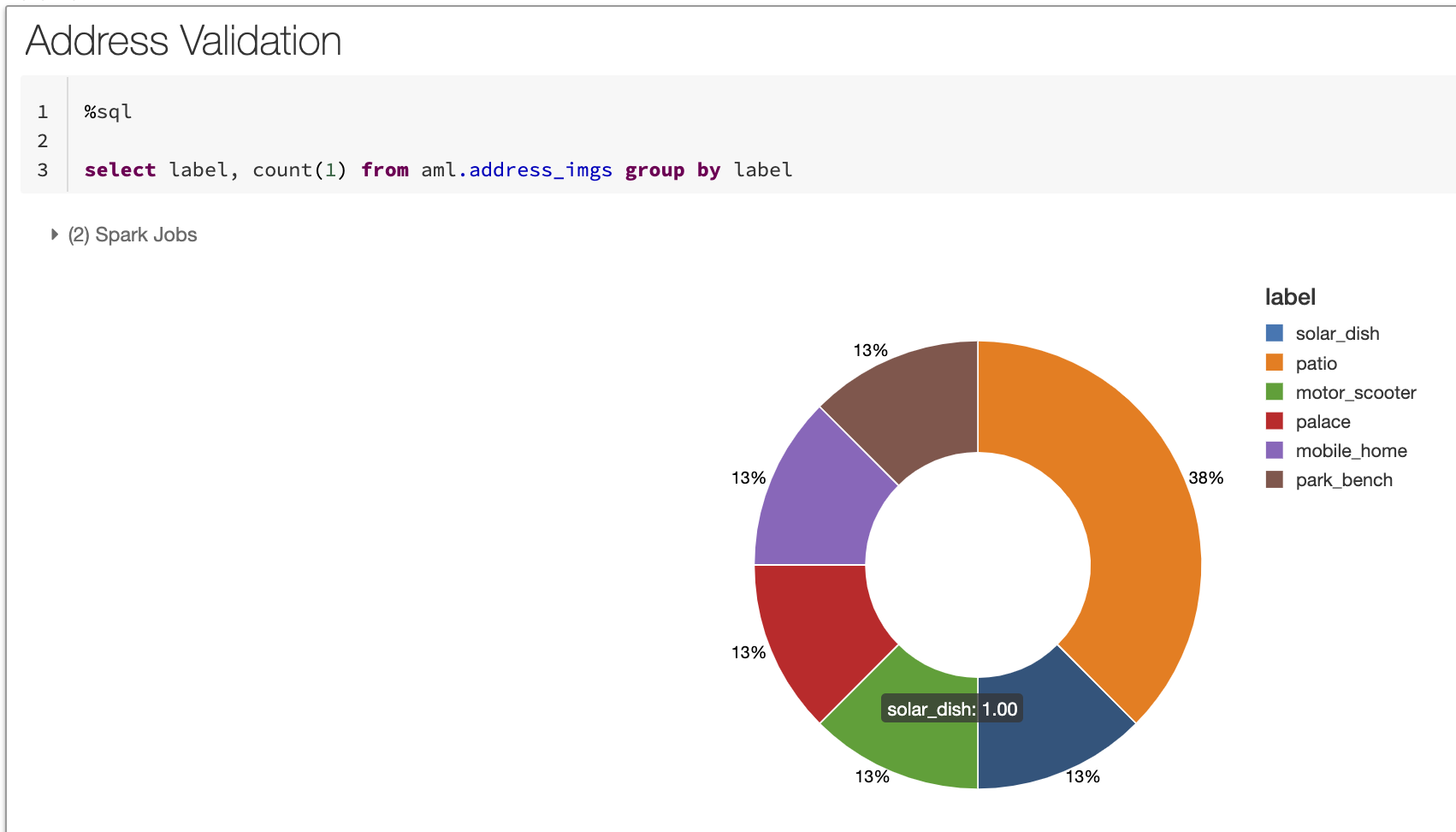
Using the code below, which can be automated to run daily, we'll now have a label attached to all our images -- we've loaded all the image references and labels up into a SQL table for simpler querying also. Notice in the code below how simple it is to query a set of images for the objects inside them -- the ability to query such unstructured data with Delta Lake is an enormous time-saver for analysts, and speeds up the validation process to minutes instead of days or weeks.
As we start to summarize, we notice some interesting categories appear. As seen below from the breakdown, there are a few obvious labels such as patio, mobile home and motor scooter we would expect to see as items detected in a residential address. On the other hand, the CV model has labeled a solar dish from surrounding objects in one image. (note: since we are restricted to an open source model not trained on a custom set of images, the solar dish label is not accurate.) Upon further analysis of the image, we drill down and immediately see that i) there is not a real solar dish here and more importantly ii) this address is not a real residence (pictured in our side-by-side comparison above). The Delta Lake format allows us to store a reference to our unstructured data along with a label for simple querying in our classification breakdown below.
Entity resolution
The last category of AML challenges that we'll focus on is entity resolution. Many open-source libraries tackle this problem, so for some basic entity fuzzy matching, we chose to highlight Splink, which achieves the linkage at scale and offers configurations to specify matching columns and blocking rules.
In the context of the entities derived from our transactions, it is a simple exercise to insert our Delta Lake transactions into the context of Splink.
Splink works by assigning a match probability that can be used to identify transactions in which entity attributes are highly similar, raising a potential alert with respect to a reported address, entity name or transaction amount. Given the fact that entity resolution can be highly manual for matching account information, having open-source libraries that automate this task and save the information in Delta Lake can make investigators much more productive for case resolution. While there are several options available for entity matching, we recommend using Locality-Sensitive Hashing (LSH) to identify the right algorithm for the job. You can learn more about LSH and its benefits in this blog post.
As reported above, we quickly found some inconsistencies for the NY Mellon bank address, with "Canada Square, Canary Wharf, London, United Kingdom" similar to "Canada Square, Canary Wharf, London, UK". We can store our de-duplicated records back to a delta table that can be used for AML investigation.

AML lakehouse dashboard
Databricks SQL on the lakehouse is closing the gap with respect to traditional data warehouses in terms of simplified data management, performance with new query engine Photon and user concurrency. This is important since many organizations do not have the budget for overpriced proprietary AML software to support the myriad use cases, such as combatting the financing of terrorism (CFT), that help fight financial crime. In the market, there are dedicated solutions that can perform the graph analytics above, dedicated solutions to address BI in a warehouse, and dedicated solutions for ML. The AML lakehouse design unifies all three. AML data platform teams can leverage Delta Lake at the lower cost of cloud storage while easily integrating open source technologies to produce curated reports based on graph technology, computer vision and SQL analytics engineering. Below we will show a materialization of the reporting for AML.
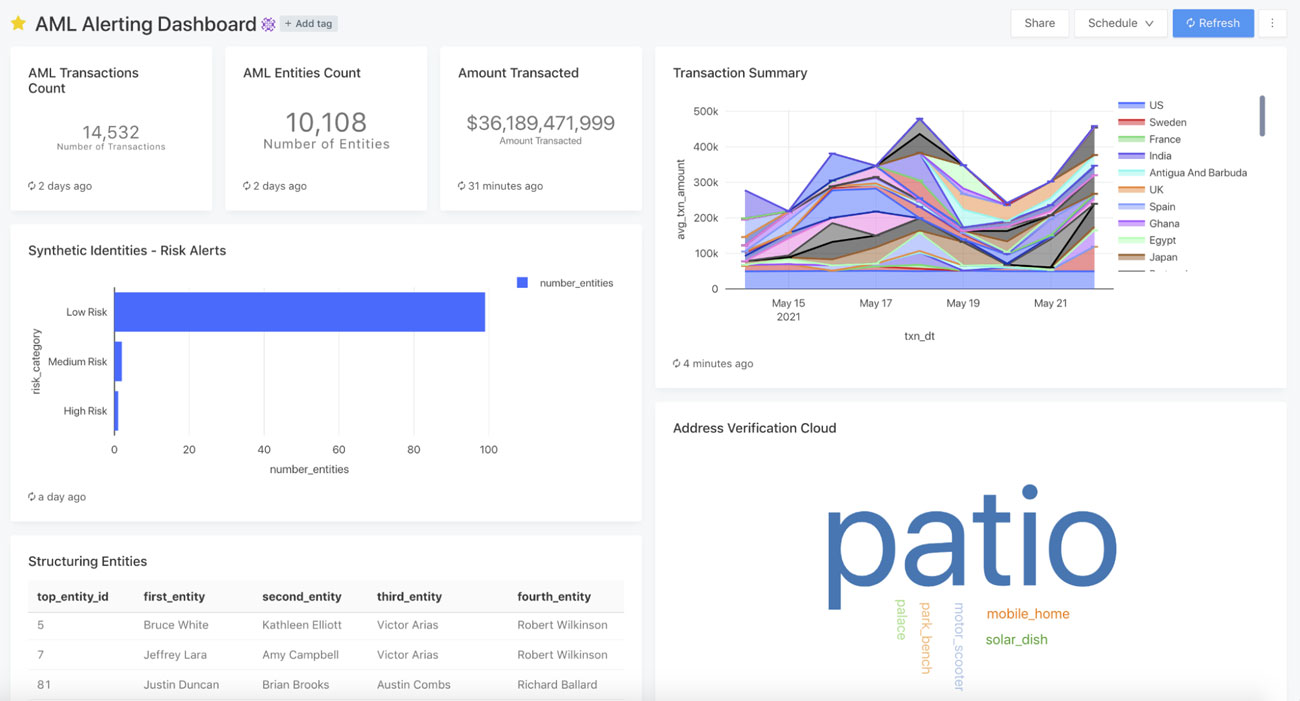
The attached notebooks produced a transactions object, entities object, as well as summaries such as structuring prospects, synthetic identity tiers and address classifications using pre-trained models. In the Databricks SQL visualization below, we used our Photon SQL engine to execute summaries on these and built-in visualization to produce a reporting dashboard within minutes. There are full ACLs on both tables, as well as the dashboard itself, to allow users to share with executives and data teams -- a scheduler to run this report periodically is also built-in. The dashboard is a culmination of AI, BI and analytics engineering built into the AML solution.
The open banking transformation
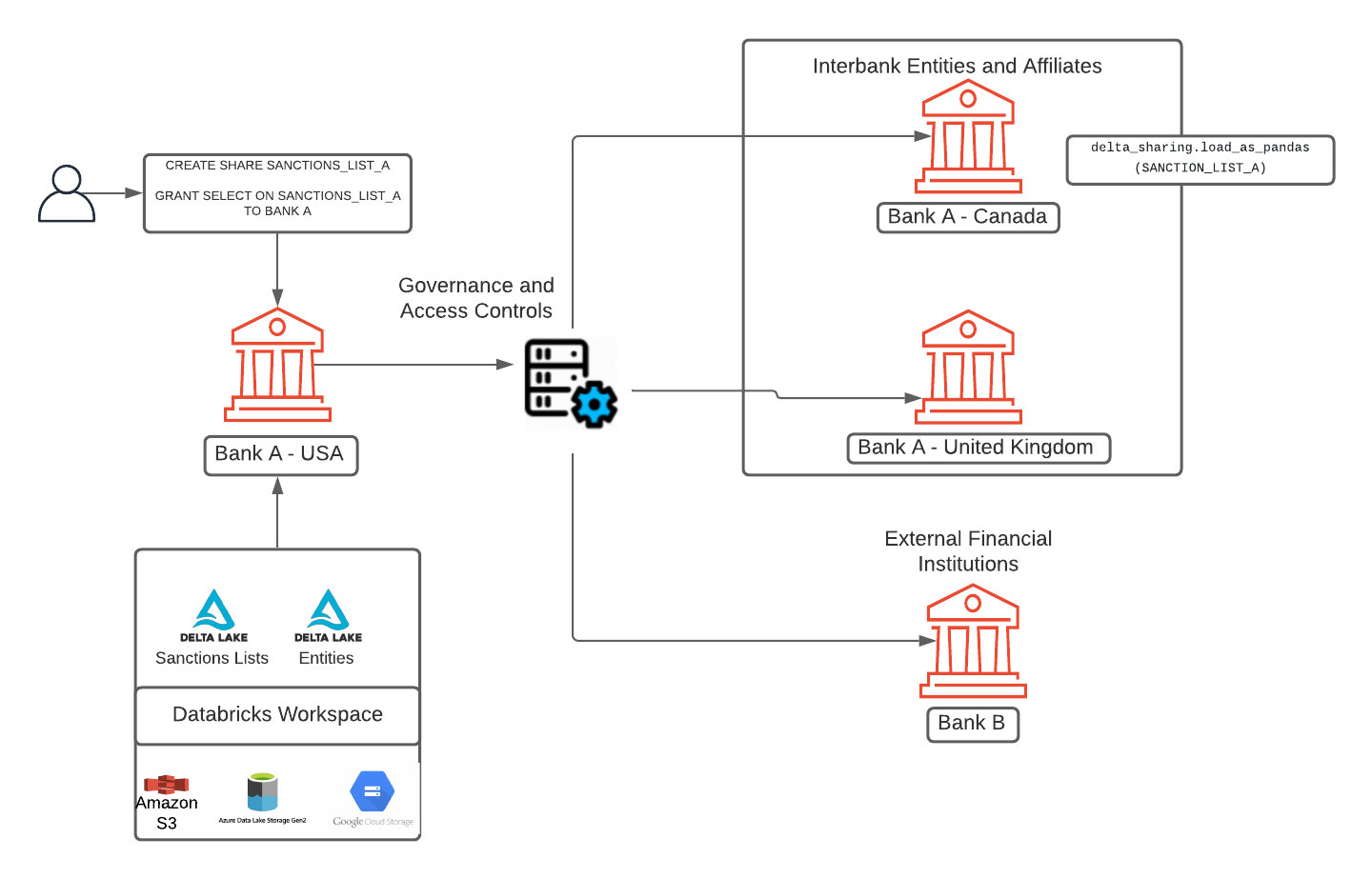
The rise of open banking enables FIs to provide a better customer experience via data sharing between consumers, FIs and third-party service providers through APIs. An example of this is Payment Services Directive (PSD2), which transformed financial services in the EU region as part of Open Banking Europe regulation. As a result, FIs have access to more data from multiple banks and service providers, including customer account and transaction data. This trend has expanded within the world of fraud and financial crimes with the latest guidance from FinCEN under section 314(b) of USA Patriot Act; covered FIs can now share information with other FIs and within domestic and foreign branches regarding individuals, entities, organizations and so on that are suspected to be involved in potential money laundering.
While information sharing provision helps with transparency and protects the United States financial systems against money laundering and terrorism financing, the information exchange must be done using protocols with proper data and security protections. To solve the problem of securing information sharing, Databricks recently announced Delta Sharing, an open and secure protocol for data sharing. Using familiar open source API's, such as Pandas and Spark, data producers and consumers can now share data using secure and open protocols and maintain a full audit of all the data transactions to maintain compliance with FinCEN regulations.
Conclusion
The lakehouse architecture is the most scalable and versatile platform to enable analysts in their AML analytics. Lakehouse supports use cases ranging from fuzzy match to image analytics to BI with built-in dashboards, and all of these capabilities will allow organizations to reduce total cost of ownership compared to proprietary AML solutions. The Financial Services team at Databricks is working on a variety of business problems in the Financial Services space and enabling data engineering and data science professionals to start the Databricks journey through Solution Accelerators like AML.
Try the notebooks on Databricks to accelerate your AML development strategy today and contact us to learn more about how we assist customers with similar use cases.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.