Pandas API on Upcoming Apache Spark™ 3.2
by Hyukjin Kwon and Xinrong Meng
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
We're thrilled to announce that the pandas API will be part of the upcoming Apache Spark™ 3.2 release. pandas is a powerful, flexible library and has grown rapidly to become one of the standard data science libraries. Now pandas users will be able to leverage the pandas API on their existing Spark clusters.
A few years ago, we launched Koalas, an open source project that implements the pandas DataFrame API on top of Spark, which became widely adopted among data scientists. Recently, Koalas was officially merged into PySpark by SPIP: Support pandas API layer on PySpark as part of Project Zen (see also Project Zen: Making Data Science Easier in PySpark from Data + AI Summit 2021).
pandas users will be able scale their workloads with one simple line change in the upcoming Spark 3.2 release:
This blog post summarizes pandas API support on Spark 3.2 and highlights the notable features, changes and roadmap.
Scalability beyond a single machine
One of the known limitations in pandas is that it does not scale with your data volume linearly due to single-machine processing. For example, pandas fails with out-of-memory if it attempts to read a dataset that is larger than the memory available in a single machine:
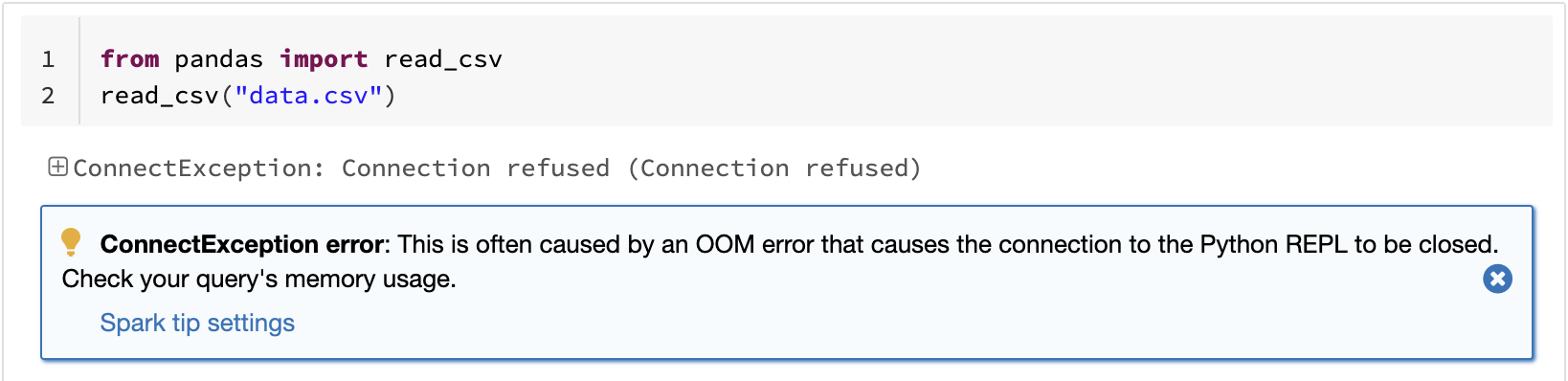
pandas API on Spark overcomes the limitation, enabling users to work with large datasets by leveraging Spark:

The pandas API on Spark also scales well to large clusters of nodes. The chart below shows its performance when analyzing a 15TB Parquet dataset with different-sized clusters. Each machine in the cluster has 8 vCPUs and 61 GiBs memory.
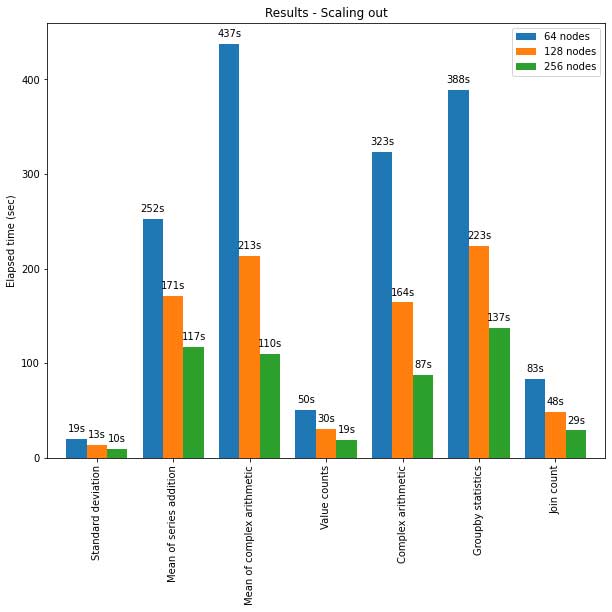
Distributed execution of pandas API on Spark scales almost linearly in this test. The elapsed time decreases by half when the number of machines within a cluster doubles. The speedup compared to a single machine is also significant. For example, on the Standard deviation benchmark, a cluster of 256 machines can process ~250 times more data than a single machine in roughly the same time (each machine has 8 vCPUs and 61 GiBs memory):
| Single machine | Cluster of 256 machines | |
| Parquet Dataset | 60GB | 60GB x 250 (15TB) |
| Elapsed time (sec) of Standard deviation | 12s | 10s |
Optimized single-machine performance
The pandas API on Spark often outperforms pandas even on a single machine thanks to the optimizations in the Spark engine. The chart below demonstrates pandas API on Spark compared to pandas on a machine (with 96 vCPUs and 384 GiBs memory) against a 130GB CSV dataset:
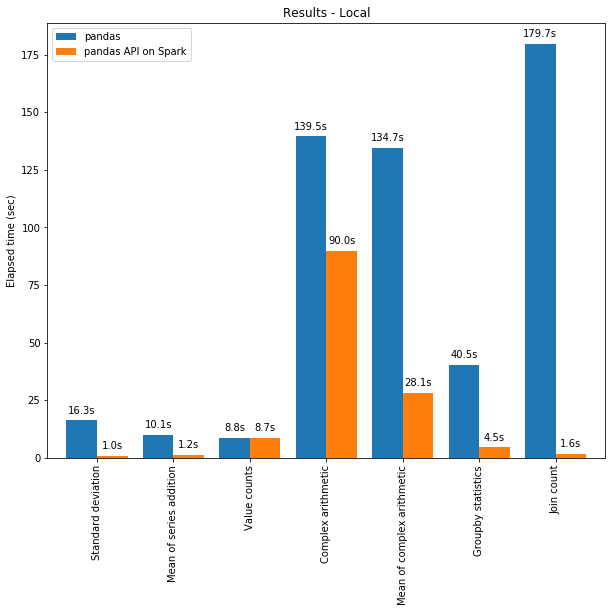
Both multi-threading and Spark SQL Catalyst Optimizer contribute to the optimized performance. For example, Join count operation is ~4 times faster with the whole-stage code generation: 5.9s without code generation, 1.6s with code generation.
Spark has an especially significant advantage in chaining operations. The Catalyst query optimizer can recognize filters to skip data wisely and can apply disk-based joins, while pandas tend to load all data into memory per step.
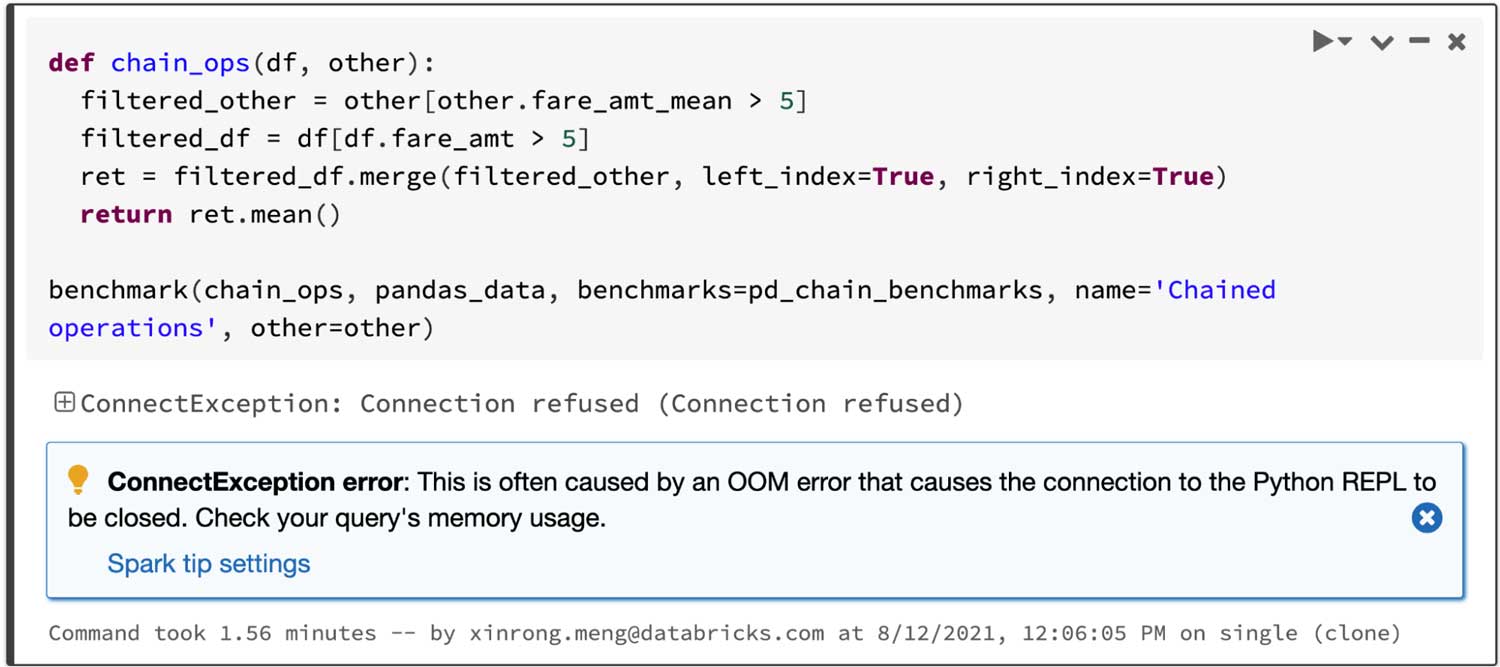
Considering a query that joins two filtered frames and then computes the mean of the joined frame, pandas API on Spark succeeds within 4.5s, whereas pandas fails because of the OOM(Out of memory) error as below:
Interactive data visualization
pandas uses matplotlib by default, which provides static plot charts. For example, the codes below generates a static chart:
In contrast, the pandas API on Spark uses a plotly backend by default, which provides interactive charts. For example, it allows users to interactively zoom in and out. Based on the type of plot, the pandas API on Spark automatically determines the best way to execute the computation internally when generating interactive charts:
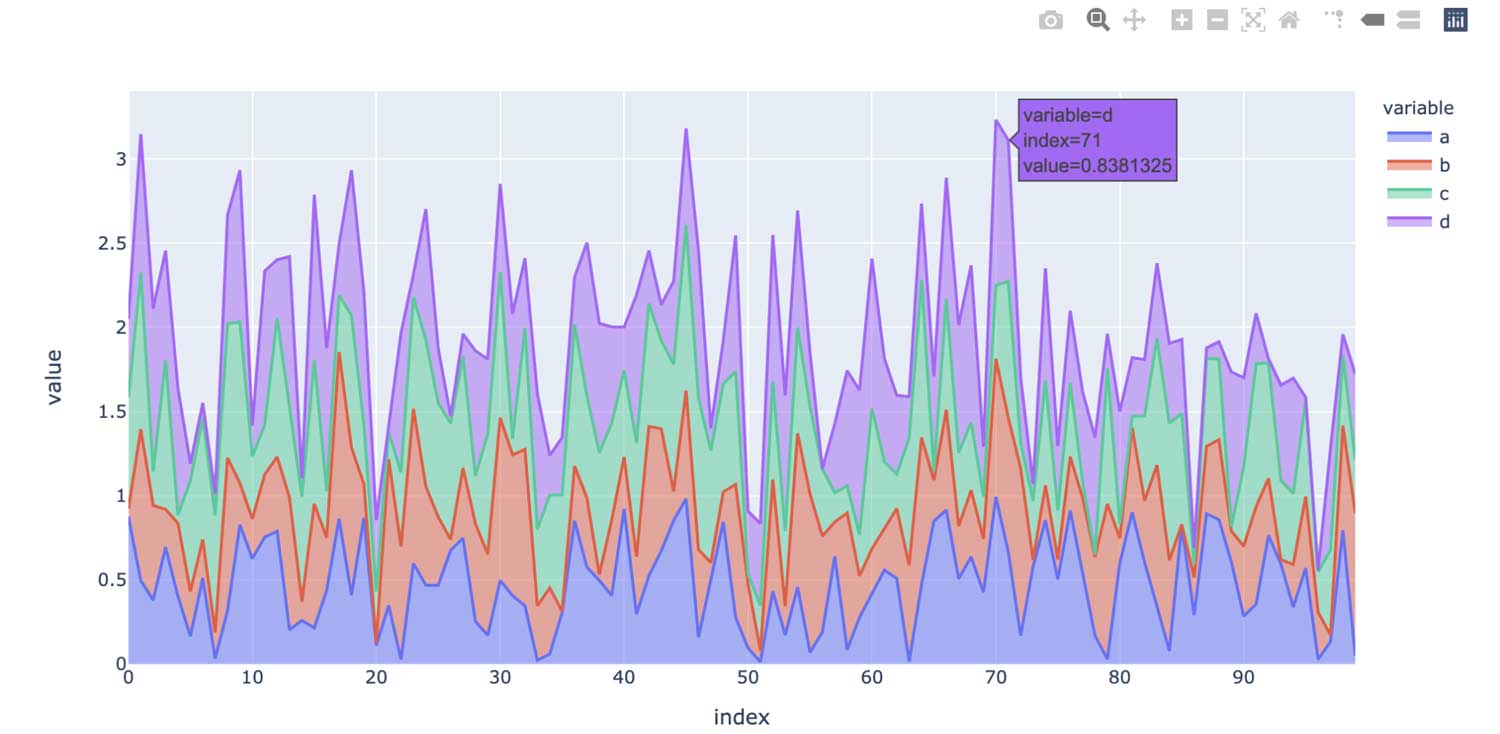
Leveraging unified analytics functionality in Spark
pandas is designed for Python data science with batch processing, whereas Spark is designed for unified analytics, including SQL, streaming processing and machine learning. To fill the gap between them, the pandas API on Spark provides many different ways for advanced users to leverage the Spark engine, for example:
- Users can directly query data via SQL with Spark's optimized SQL engine, as shown below:
- It also supports string interpolation syntax to interact with Python objects naturally:
- pandas API on Spark also supports streaming processing:
- Users can easily call the scalable machine learning libraries in Spark:
See also the blog post about the interoperability between PySpark and pandas API on Spark.
What's next?
For the next Spark releases, the roadmap focuses on:
• More type hints
The code in the pandas API on Spark is currently partially typed, which still enables static analysis and auto-completion. In the future, all of the code will be fully-typed.
• Performance improvements
There are several places in pandas API on Spark where we can improve performance further by more closely interacting with the engine and SQL optimizer.
• Stabilization
There are several places to fix especially related to missing values such as NaN and NA have the corner cases of behavior differences.
In addition, the pandas API on Spark will follow and match its behavior to the latest version of pandas in these cases.
• More API coverage
The pandas API on Spark reached 83% coverage of the pandas API, and this number continues to increase. Now the target is up to 90%.
Please file an issue if there are bugs or missing features that you need, and of course, we always welcome contributions from the community.
Getting started
If you want to try out pandas API on Spark in Databricks Runtime 10.0 Beta (upcoming Apache Spark 3.2), sign up for Databricks Community Edition or Databricks Trial for free and get started in minutes.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.