Efficient Point in Polygon Joins via PySpark and BNG Geospatial Indexing
by Milos Colic, Robert Whiffin, Pritesh Patel, Charis Doidge, Steve Kingston and Linda Sheard
This blog is outdated. Please refer to this Spatial SQL blog for up-to-date approaches to storing and processing geospatial data within your Databricks Lakehouse.
This blog presents a collaboration between Ordnance Survey (OS), Databricks and Microsoft that explores spatial partitioning using the British National Grid (BNG).
OS is responsible for the design and development of a new National Geographic Database (NGD) data delivery for Great Britain (GB) under the Public Sector Geospatial Agreement.
OS has been working closely with Databricks and Microsoft on the architectural strategy and data engineering capabilities that underpin the NGD as part of a Core Data Services Platform. This platform enables OS to migrate geospatial data processing that has traditionally been carried out on on-prem machines in single-threaded processes and applications, such as FME to cloud compute, that are available and scalable on-demand — thus, achieving the processing and analysis of geospatial data at scale. OS is using Azure Databricks to add Apache Spark™ capability to the cloud platform, and this brings the opportunity to re-think how to optimize both data and approach to perform geospatial joins at scale using parallelized processing.
Indexing spatial data appropriately is one aspect of such optimization work, and it doesn’t just stop at selecting an index. The focus of this blog is on how we designed a process that makes maximal use of the index to allow the optimizers provided by Azure Databricks to tune the way that data is loaded from disk during scaled geospatial joins.
There are various grid indexes such as BNG, Geohash, Uber's H3, and Google's S2 that divide the spatial world into bins with identifiers. While some of these have been developed specifically in the context of modern geoanalytics, and therefore tend to be well supported with associated libraries and practical examples of use in that context, the British National Grid indexing system was defined in 1936 and is deeply embedded in the Great Britain geospatial data ecosystem, but not yet exploited and made accessible for geoanalytics at scale. Our secondary motivation here, therefore, was to show that it can be used directly for optimizing spatial joins, avoiding the need to convert Great Britain's geospatial datasets to other indexing systems first. Our team implemented a mosaic technique that decomposed polygons into simplified geometries bounded by their presence in a given BNG index. By effectively limiting index space comparisons and spatial predicate evaluations, the approach yielded notable query performance gains.
The point-in-polygon: how hard can it be?
How hard is it to determine whether a point is inside a polygon (PIP)? The question of how to determine whether a point is contained within a polygon has already been answered years ago. This fact can introduce bias, making us jump to conclusions like, “it is easy; it has already been solved.” However, with the advancement of technology and the introduction of parallel systems, we have found ourselves asking this same question but in a new context. That context is using a PIP as a join relation over big (geospatial) data. The new problem is ensuring that we have high levels of parallelism in our approach. Unfortunately, the old answers no longer apply in this new context.
We can think of the join relationship as a pairing problem. We can observe it as having two datasets that contain rows that match with a set of rows from the other dataset while satisfying the join condition. The complexity of join relation is O(n*m) or what is commonly known as the Cartesian Product (complexity). This is the worst-case complexity for a join relation and, in simple terms, means that we need to compare each record from one dataset with each record of the other dataset to resolve all matches. Many systems implement techniques and heuristics to push this complexity to a lower level. However, this is the baseline, and we will start our considerations from this baseline.
In the context of OS’s geospatial data processing, one of the most common PIP joins routinely undertaken is between all address point geometries (approx. 37 million) and all large-scale building polygon geometries (approx. 46 million) in GB.
The (not so) hidden cost?
While discussing join relation complexity, we have made an oversight. The traditional complexity assumes a fixed cost for each pair resolution, that is, the cost of arriving at a conclusion of match or no match for each pair of records during the join operation, which we will call O(join). The true cost of the join is O(n*m)*O(join). In the traditional equivalence relationship class, where we are just looking whether a join key on the left matches a join key on the right, we assume O(join) is O(1) or to put it simply, the cost of comparison is one arithmetic operation, and it is constant. This is not always the case; for example, joining on a string comparison is more expensive than an equivalence between two integers.
But what of PIP, how costly is it relatively? The most widely used algorithm to answer PIP is the ray-tracing method. The complexity of this algorithm is O(v), where v is the number of vertices of the polygon in question. The algorithm is applicable to both convex and non-convex shapes, and it maintains the same complexity in both cases.
Adding the comparison cost to our cost model brings our total complexity to cubic form. If we replace O(join) with O(v), where v is the average number of vertices, we have the total complexity of O(n*m)*O(v). And this is both expensive and time-consuming!
Work smarter, not harder!
We can do better than O(n*m)*O(v). We can use Spark to help us beat the Cartesian Product complexity. Spark leverages hash joins under the hood. Depending on the join predicate, Spark can execute one of the following join strategies:
- broadcast hash join with complexity of O(max(n,m))*O(join)
- shuffle hash join (similar to Grace Hash Join) with complexity of O(n+m)*O(join)
- shuffle sort-merge join with complexity of O(n*log(n)+m*log(m))*O(join)
- broadcast nested loop join (Cartesian join) with complexity O(n*m)*O(join)
Amazing! We can just use Spark, and we will avoid the most costly outcome, can’t we? No! Unfortunately, Spark will default to Cartesian join for PIP joins. Why? Where PIP differs from traditional equi-based joins is that it is based on a general relation. These joins are commonly known as a Theta Join class. These are usually much harder to execute and require the end-user to help the system. While we are starting from a disadvantageous position, we can still achieve the desired performance.
Spatial indices (PIP as a pseudo-equivalence)
Is there a way to make PIP an equivalence relationship? Strictly speaking no, however, in practice, we can make PIP approach the efficiency of an equivalence relation if we employ spatial indexing techniques.
Spatial indices help us index coordinate space in an efficient way by logically grouping geometries that are close to one another in said space. We achieve this by uniquely associating a point in the coordinate system to an index ID. These systems allow us to represent reference space at different levels of detail, or simply, a different resolution. In addition, geospatial index systems are hierarchical systems; this means that there is a well-defined parent-child relationship between indices on different levels of representation.
How does this help us? If we assign to each geometry an index to which it belongs, we can use index ID to index ID equivalence as an equivalence relation proxy. We will perform PIP (or any other geometry-based relation) only on geometries that belong to the same indices.
It is important to note that while POINT geometries belong to one and only one index, all other geometry types, including LINESTRINGs and POLYGONs, may span over a set of indices. This implies that the cost of resolving a PIP relation via index space is O(k)*O(v), where k is the number of indices used to represent the geometry and v is the number of vertices of such geometry. This indicates that we are increasing the price of each comparison by exploding records of complex geometries into multiple index records carrying the same geometry.
Why is this a wise choice? While we are increasing the price of comparing a single pair of geometries, we are avoiding a full Cartesian Product, our archnemesis in large-scale geospatial joins. As we will show in more detail later, index ID to index ID join will allow us to skip large amounts of unnecessary comparisons.
Lastly, data sources that contain complex geometries do not evolve as fast as do point-wise data sources. Complex geometries usually represent regions, areas of interest, buildings, etc., and these concepts have a fairly stable timeline, objects that change over time change rarely, and objects that change are relatively few. This means that while we do spend extra time to preprocess complex geometries, for the majority of them, this preprocessing is a one-off event. This approach is still applicable even for frequently updated data; the amount of data we can skip when joining via index ID to index ID relationship outweighs the increased number of rows used to represent a single geometry.
The BNG Index System
The BNG is a local coordinate reference (CRS) system (EPSG:27700) established in 1936 and designed for national mapping that covers Great Britain. Unlike global CRS', BNG has been fitted and shaped to the landmass of Great Britain, projecting coordinates onto a flat, regular square grid with an origin (0, 0) to the southwest of the Isles of Scilly.
Within the grid bounds, geographic grid references (or indices) are used to identify grid squares at different resolutions expressed in meters which can be translated from and to BNG easting (x) and northing (y) coordinates. Given the location of the grid origin, easting and northing values are always positive. BNG serves as the primary reference system for all OS location data captured under their national mapping public task and, therefore, has been widely adopted by public and private users of OS data operating within Great Britain.
Each grid square can be represented as a polygon geometry where the length of each side is equal to the resolution of the grid reference. This makes BNG a much easier starting point for geospatial data partitioning strategies. We are starting with a square as a building block, and it will make a lot of the starting considerations simple while not losing on the generalization of the approach.
By convention, BNG grid references are expressed as strings, using the letters and coordinates of the southwest corner of a given grid square quoted to a particular resolution. The first two characters of any reference are letters (prefixes) (e.g., TQ) identifying one of the 91 grid squares measuring 100.000m (100km) across. Only 55 of the 91 100km grid squares cover some landmass within Great Britain. The remainder of these squares falls into British waters.

References identifying more granular grid resolutions below 100km will have additional x and y integer values appended after the two letters locating a child grid square are within the parent grid square hierarchy. Child squares are numbered from 0 to 9 from the lower-left (southwest) corner, in an easterly (x) and northerly (y) direction.
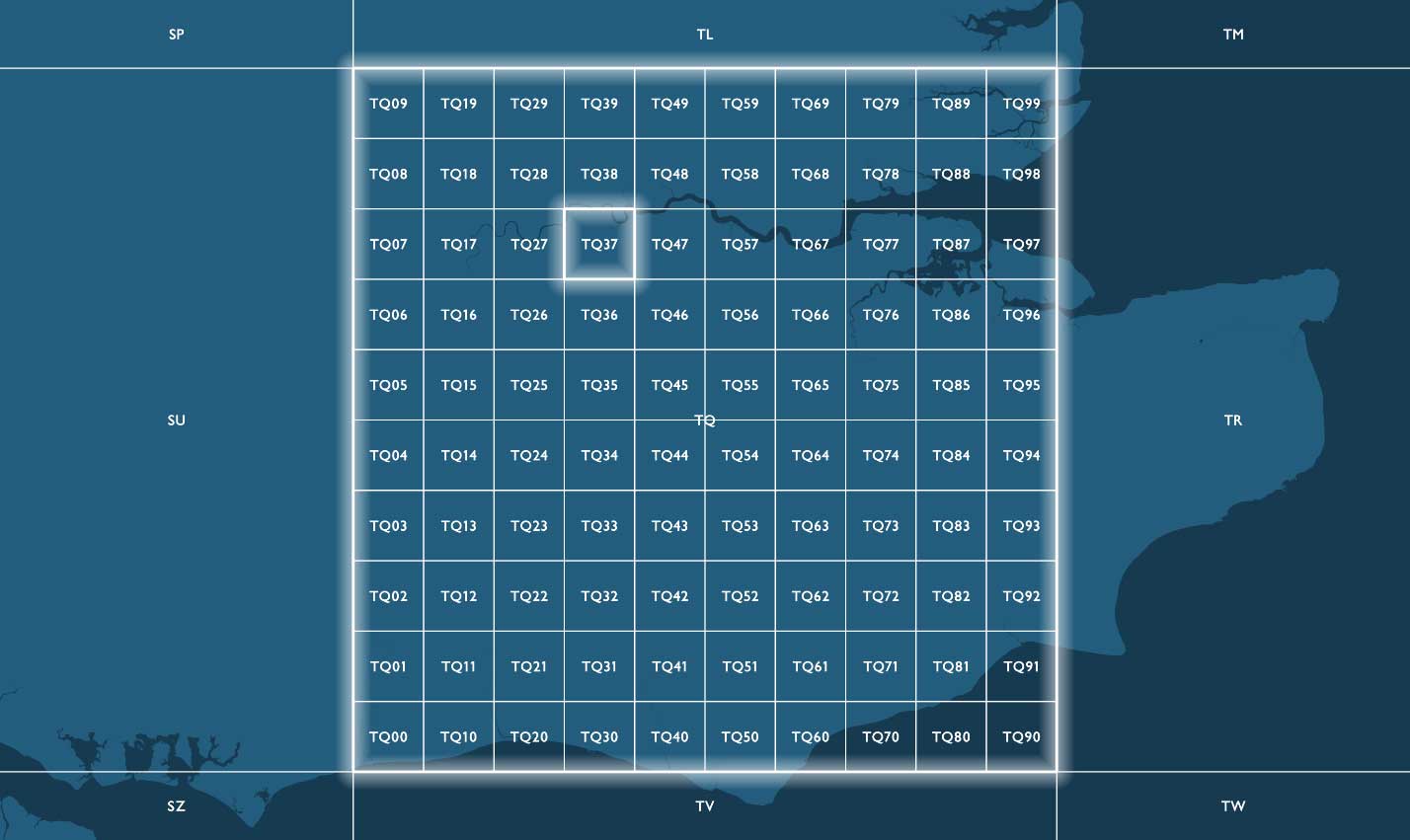
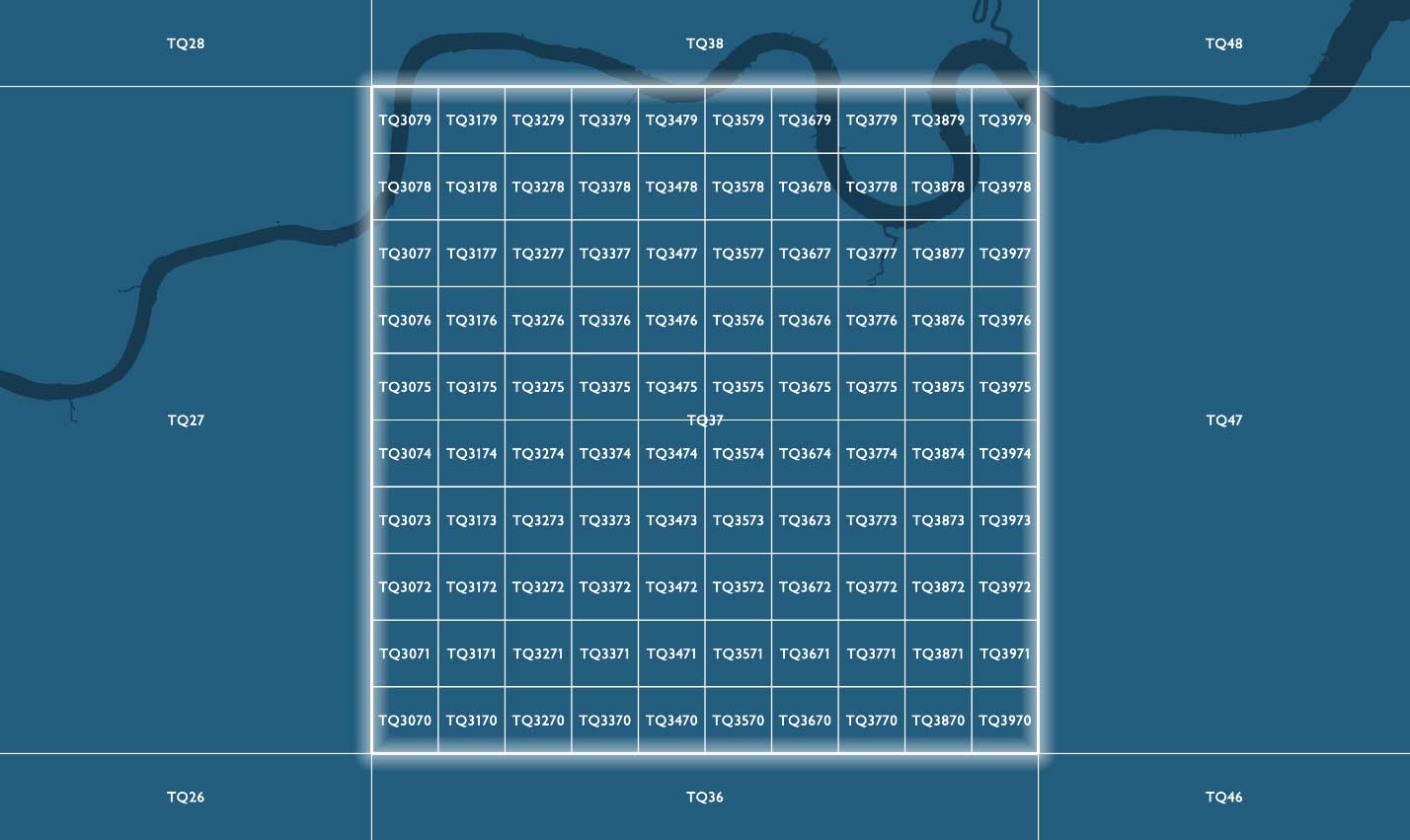
Why BNG?
Whilst there are alternative global index systems that we could have adopted for this work, we chose to use BNG because:
- The BNG system is native to OS’s geospatial data collection, with almost all OS data referenced against the BNG CRS (EPSG:27700). This includes OS aerial imagery tiles and other raster datasets, such as Digital Terrain Models (DTMs) and Digital Surface Models (DSMs).
- The use of BNG enables the efficient retrieval and colocation of vector and raster data for analysis, including the clipping or masking of raster data for deriving training patches for deep learning applications, as an example.
- Using BNG avoids the costly transformation to the World Geodetic System 1984 (WGS-84) (EPSG:4326) or European Terrestrial Reference System 1989 (ETRS89) (EPSG:4258) CRSs via the OSTN15 transformation grid. Different CRSs realize their model of the Earth using different parameters, and a global system (e.g., WGS84) will show an offset when compared to a local system (e.g., BNG). The true cost of this conversion is reflected in the fact that OS published OSTN15, a 15MB corrections file containing approx. 1.75 million parameters to transform accurately between satellite-derived coordinates and BNG coordinates.
Due to the GB-local nature of the problems OS is trying to solve, BNG is a natural choice. In the case of a more global context, we should switch our focus on H3 or S2 as more suitable global alternatives.
BNG as a Spatial Partitioning Strategy
A spatial partitioning strategy defines an approach to segmenting geospatial data into non-overlapping regions. BNG grid squares at different resolutions provide the non-overlapping regions across Great Britain in this context. By retrieving the BNG indices, which cover geometries we can use the indices attribute as a join key to collocate rows and then only test a spatial predicate within those collocated rows (e.g., does geometry A intersect geometry B or does geometry A contain geometry B).
This is very important! Splitting the original data into geospatially collocated portions of data makes our problem “embarrassingly parallel,” and, therefore, very suitable for Spark/PySpark. We can send different chunks of data to different machines and only compare local portions of the data that are likely to join one to another. There is little point in checking if a building in London contains an address in Manchester. Geospatial indices are our way to convey this intuition to the machine.
The baseline
We used Python and PySpark to bring our solution to life. OS provided the logic for converting the pair of coordinates provided as eastings and northings to a unique BNG index ID. Lastly, to ensure an unbiased output, we used a randomized dataset of points and a randomized dataset of polygons; 10 million points were scattered all over the territory of GB, 1 million polygons were scattered in the same manner. To generate such a set of polygonal data, we have loaded a GeoJSON set into a Spark dataframe, we have used a random function in conjunction with a generator function (explode) to generate an unbiased dataset. Due to randomness introduced in the data, one should expect that the relationship between points and polygons is many-to-many.
The baseline algorithm we used for our considerations is the naive join that would result in the unoptimized theta join. This approach will, at the execution time, be evaluated as a Broadcasted Nested Loop Join.
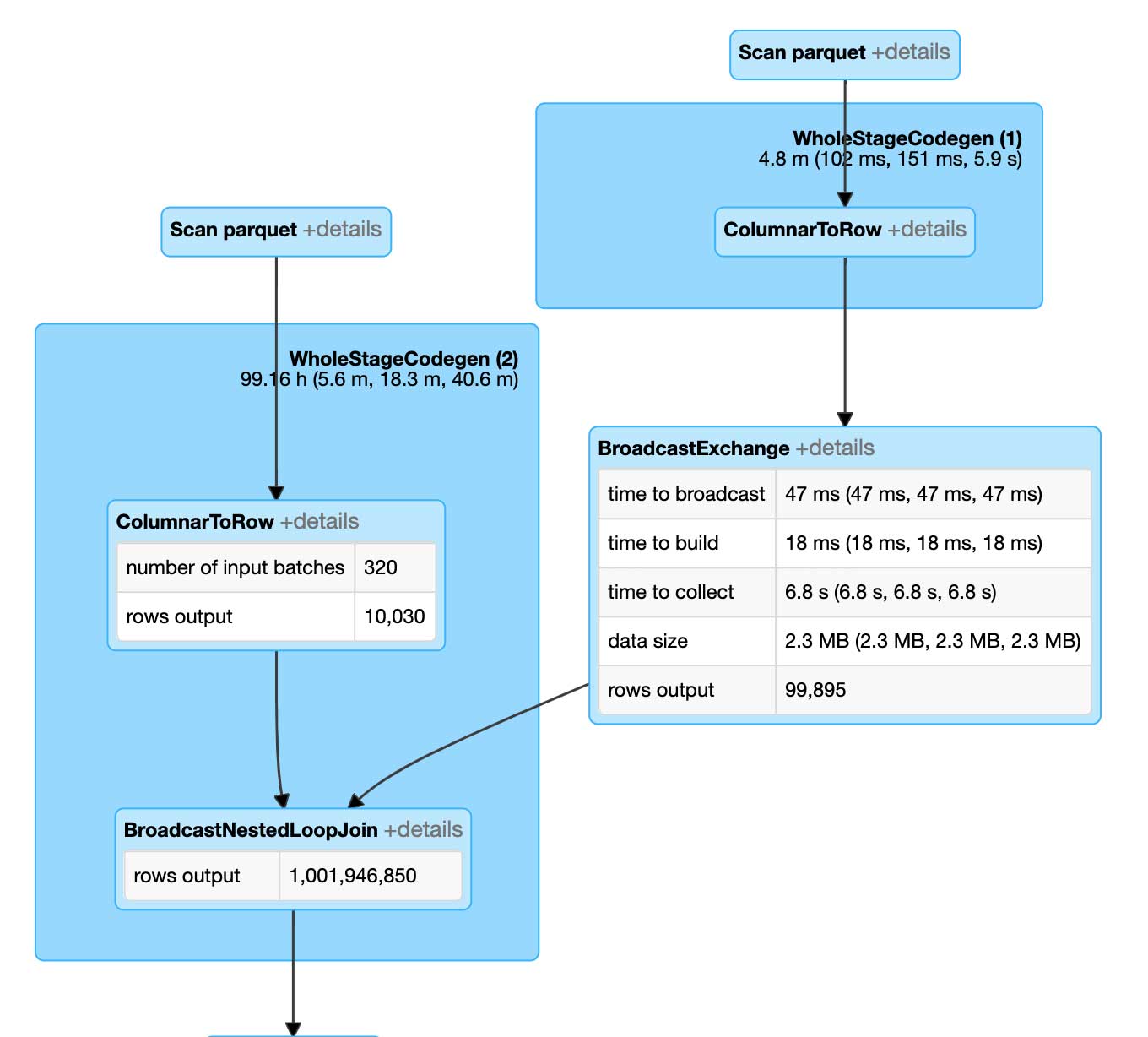
The broadcast nested loop join runs very slowly. And the reason for this is the fact it is evaluated similarly to a Cartesian join. Each of the point-polygon pairs is evaluated against a PIP relation before the join is resolved. The outcome is that we require one billion comparisons for 100 thousand points to be joined to 10 thousand polygons. Note that neither of these datasets is large enough to be called big data.
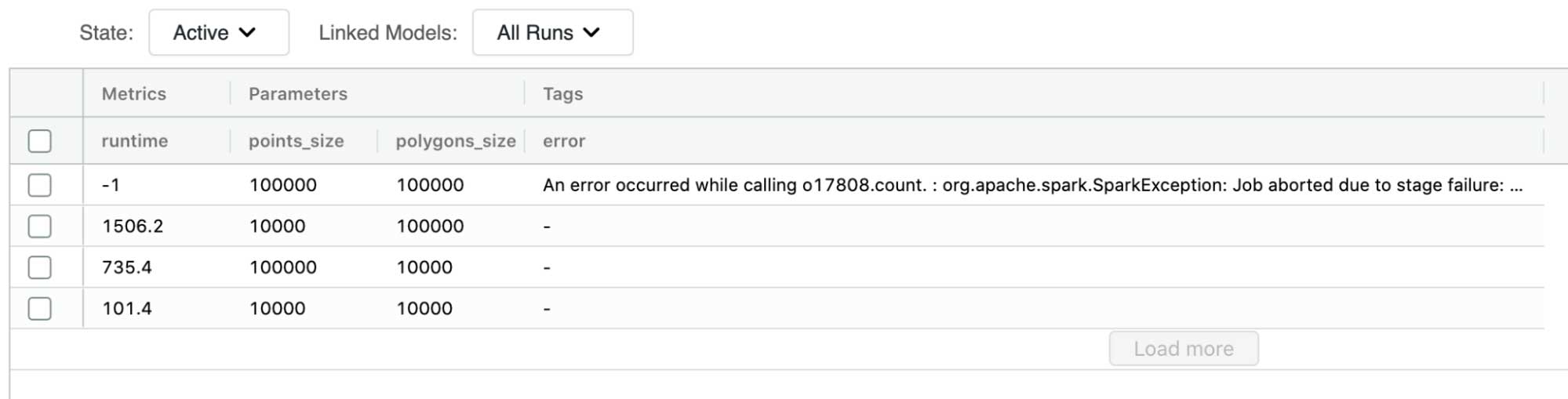
We used MLflow to conduct a series of naive joins to evaluate the baseline performance we are trying to outperform. For the naive approach, the largest join we were able to successfully execute was 10 thousand points to 100 thousand polygons. Any further increase in data volume resulted in our Spark jobs failing without producing the desired outputs. These failures were caused by the unoptimized nature of the workloads we were trying to run.
Let’s frame our problem
What if we represented all of our geometries, no matter their shape, with a corresponding BNG-aligned bounding box? A bounding box is a rectangular polygon that can fit the entirety of the original geometry within. And what if we represented said bounding box as a set of BNG indices at a given resolution that together covers the same area.

Now we can execute our joins via a more optimized theta join. We will only check whether a point is inside the polygon via PIP relation if a point falls into one of the BNG indices that are used to represent the polygon. This reduces our join effort by multiple orders of magnitude.
In order to produce the said set of BNG indices, we have used the following code; note that the bng_to_geom, coords_to_bng and bng_get_resolution functions are not provided with this blog.
This code ensures that we can represent any shape in a lossless manner. We are using intersects relation between a BNG index candidate and the original geometry to avoid blindspots in representation. Note that a more efficient implementation is possible by using contains relation and a centroid point; that approach is only viable if false positives and false negatives are acceptable. We assume the existence of the bng_to_geom function that given a BNG index ID can produce a geometry representation, the bng_get_resolution function that given a BNG index ID determines the selected resolution and coords_to_bng function that given the coordinates returns a BNG index ID.
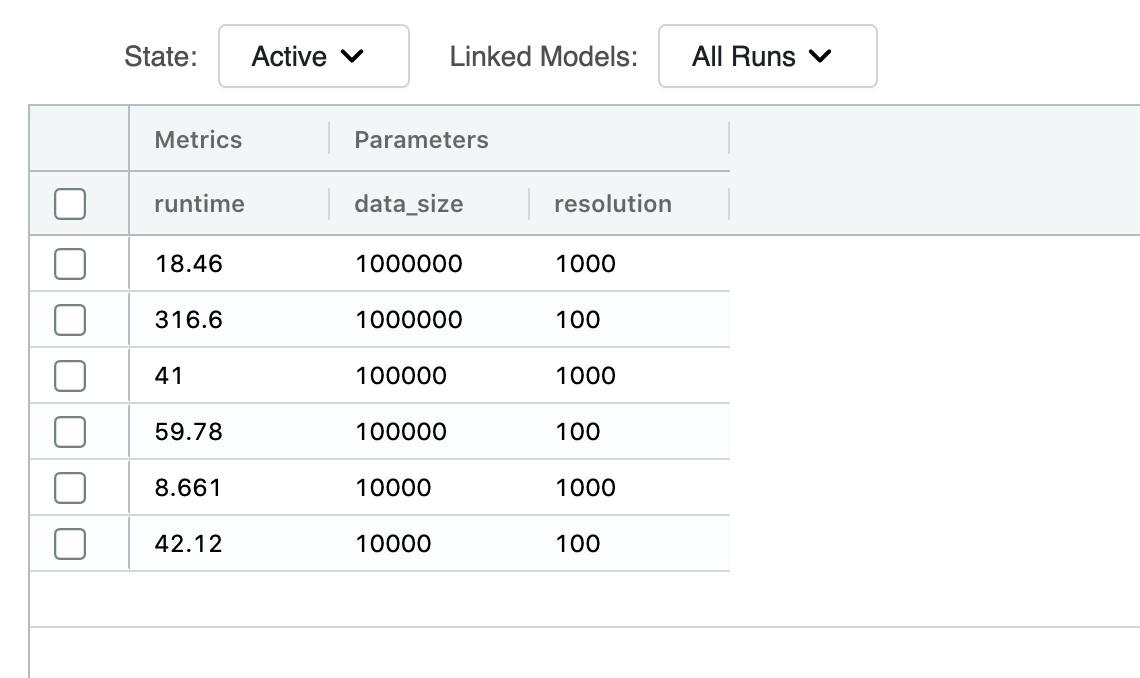
We have run our polygon bounding box representation for different resolutions of the BNG index system and for different dataset sizes. Note that running this process was failing consistently for resolutions below 100. Resolutions are represented in meters in these outputs. The reason for consistent failures at resolutions below 100m can be found in over-representation; some polygons (due to random nature) are much larger than others, and while some polygons would be represented by a set of a dozen indices, other polygons can be represented by thousands of indices, and this can result in a big disparity in compute and memory requirements between partitions in a Spark job that is generating this data.
We have omitted the benchmarks for points dataset transformations since this is a relatively simple operation that does not yield any new rows; only a single column is added, and the different resolutions do not affect execution times.
With both sides of the join being represented with their corresponding BNG representations, all we have to do is to execute the adjusted join logic:
These modifications in our code have resulted in a different Spark execution plan. Spark is now able to first run a sort merge join based on the BNG index ID and vastly reduce the total number of comparisons. In addition, each pair comparison is a string-to-string comparison which is much shorter than a PIP relationship. This first stage will generate all the join set candidates. We will then perform a PIP relationship test on this set of candidates to resolve the final output. This approach ensures that we limit the number of times we have to run the PIP operation.
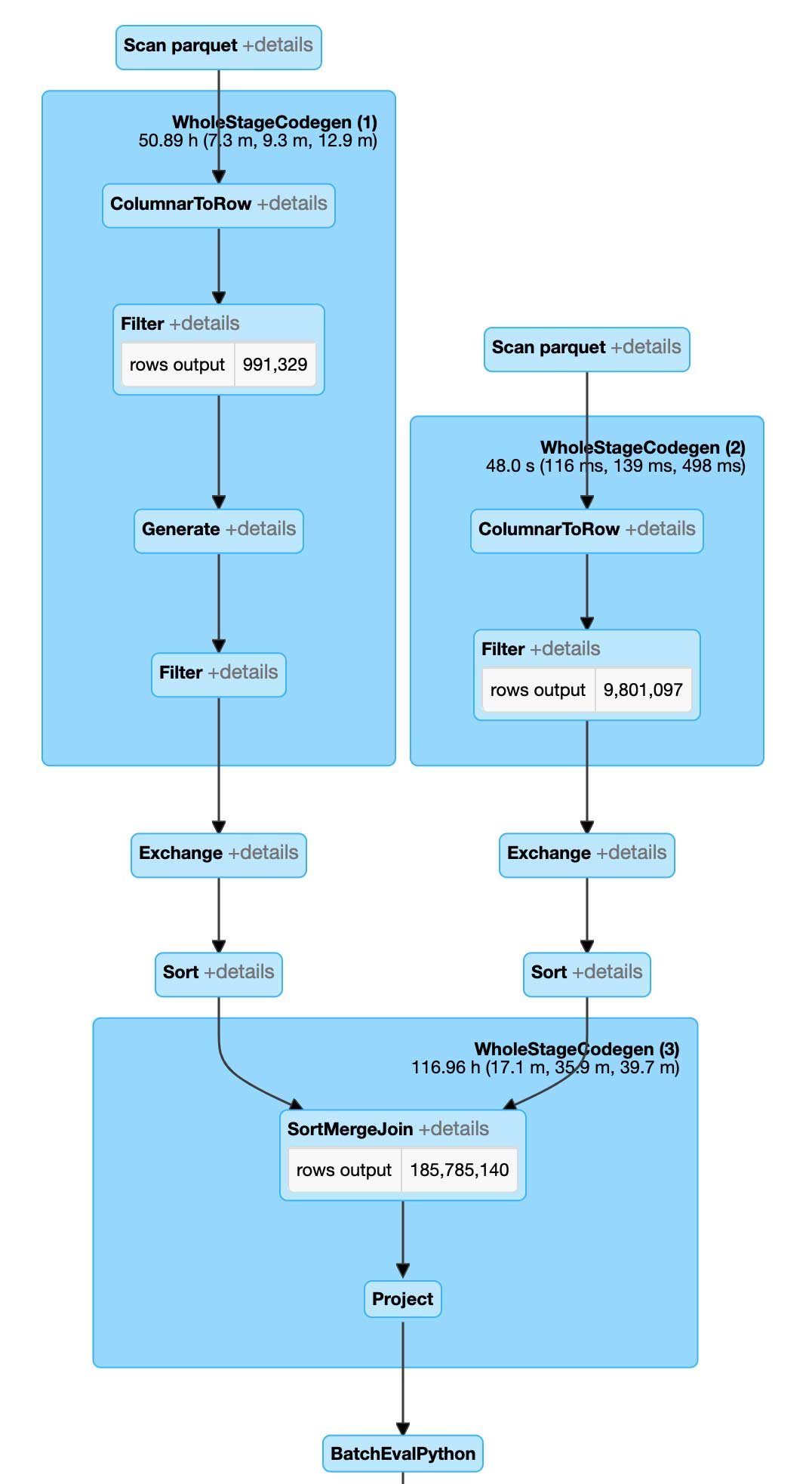
From the execution plan, we can see that Spark is performing a very different set of operations in comparison to the naive approach. Most notably, Spark is now executing Sort Merge Join instead of Broadcast Nested Loop Join, which is bringing a lot of efficiencies. We are now performing about 186 million PIP operations instead of a billion. This alone is allowing us to run much larger joins with better response time whilst avoiding any breaking failures that we have experienced in the naive approach.
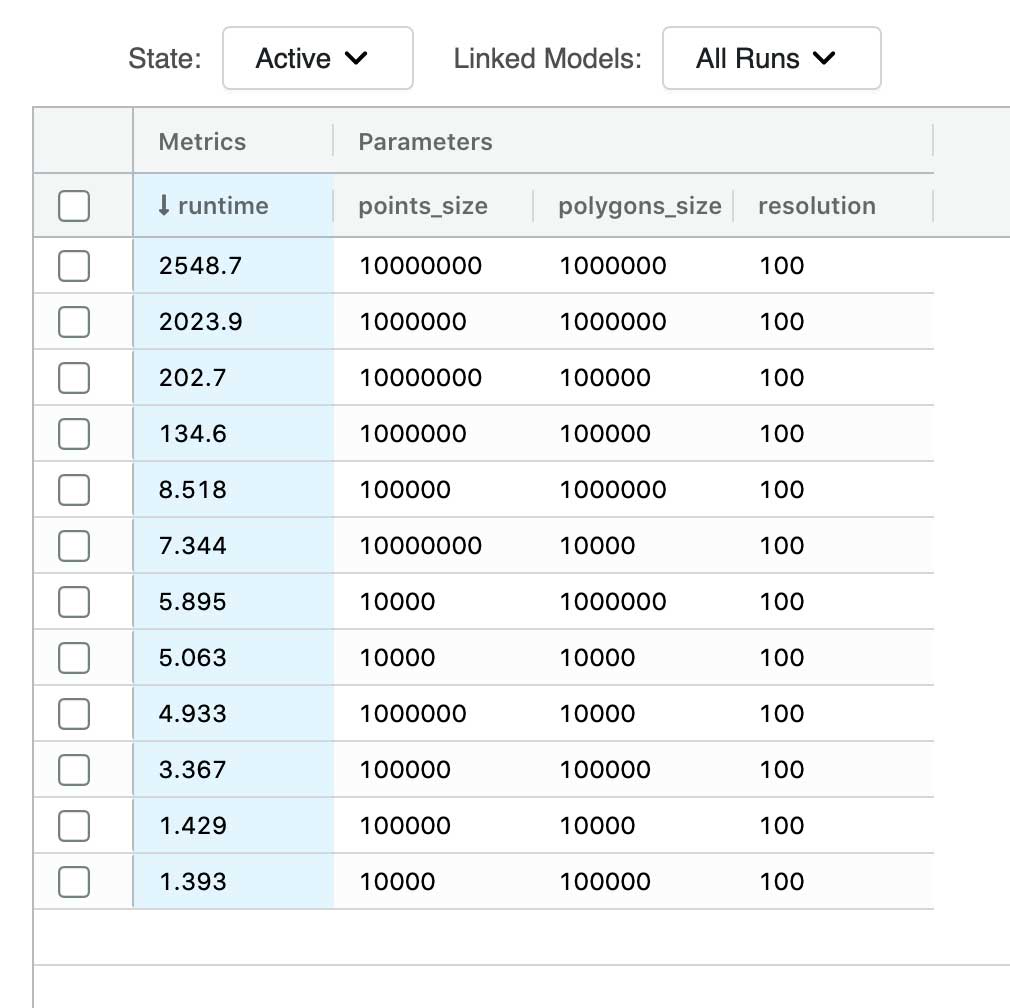
This simple yet effective optimization has enabled us to run a PIP join between 10 million points and 1 million polygons in about 2500 seconds. If we compare that to the baseline execution times, the largest join we were able to successfully execute was 10 thousand points to 100 thousand polygons, and even that join required about 1500 seconds on the same hardware.
Divide and conquer
Being able to run joins between datasets in the million rows domain is great; however, our largest benchmark join took almost 45 minutes (2500 seconds). And in the world where we want to run ad hoc analytics over large volumes of geospatial data, these execution times are simply too slow.
We need to further optimize our approach. The first candidate for optimization is our bounding box representation. If we are representing polygons via bounding boxes, we include too many false positive indices, i.e., indices that do not overlap at all with the original geometry.
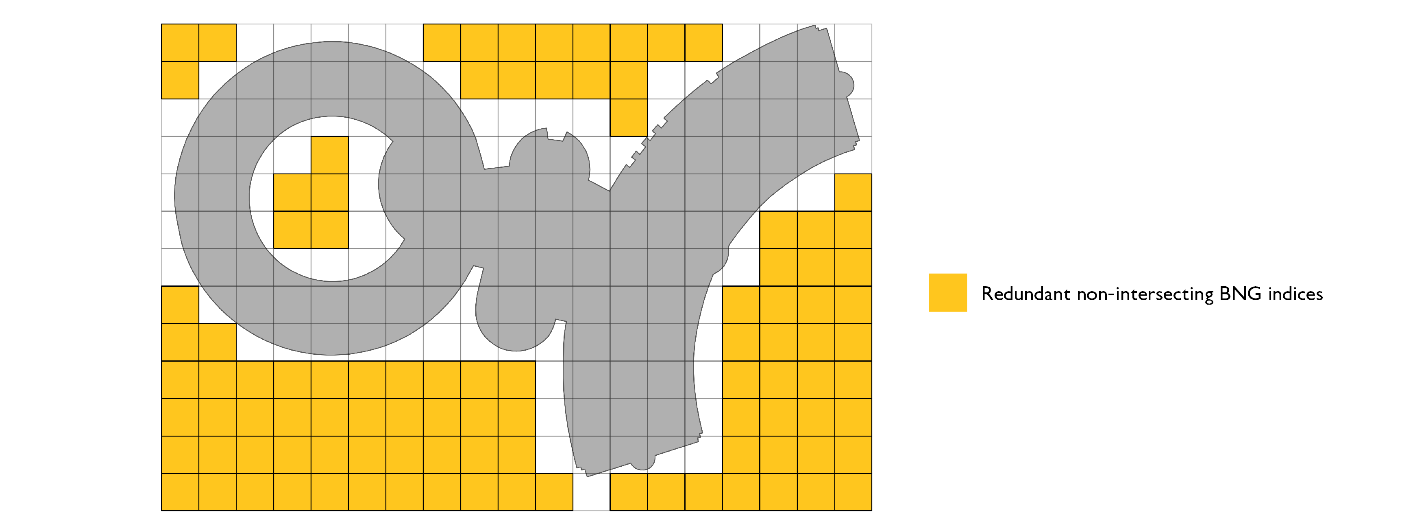
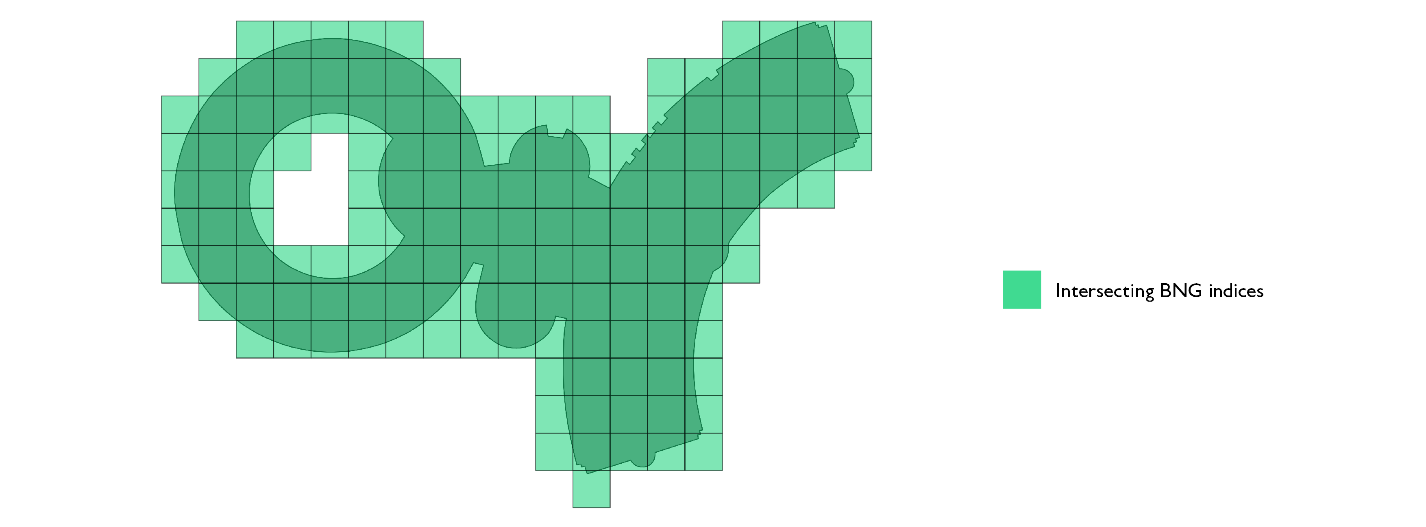
The way to optimize that portion of the code is to simply use intersects function call in our polyfill method on the original geometry.
This optimization, while increasing the cost by utilizing intersects call, will result in smaller resulting index sets and will make our joins run faster due to the smaller join surface
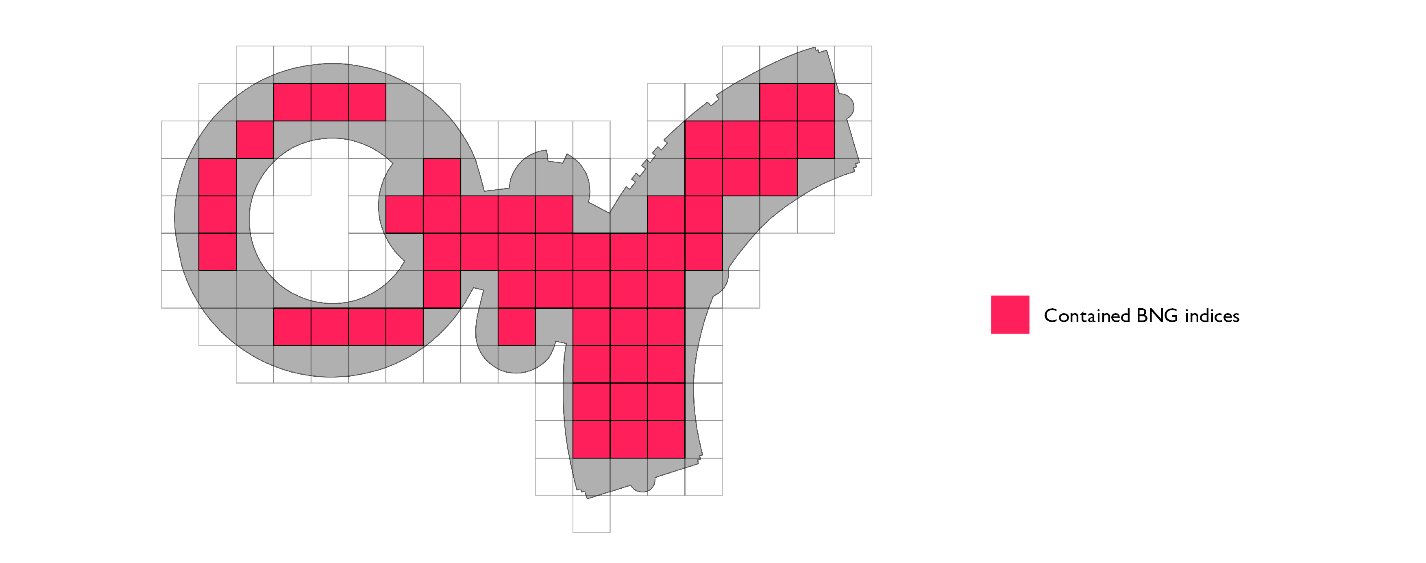
The second optimization we can employ is splitting the representation into two sets of indices. Not all indices are equal in our representation. Indices that touch the border of the polygon require a PIP filtering after an index to index join. Indices that do not touch the border and belong to the representation of the polygon do not require any additional filtering. Any point that falls into such an index definitely belongs to the polygon and, in such cases, we can skip the PIP operation.
The third and final optimization we can implement is the mosaic approach. Instead of associating the complete original geometry with each index that belongs to the set of indices that touch the polygon border (border set), we can only keep track of the section of interest. If we intersect the geometry that represents the index in question and the polygon, we get the local representation of the polygon; only that portion of the original polygon is relevant over the area of the index in question. We refer to these pieces as polygon chips.
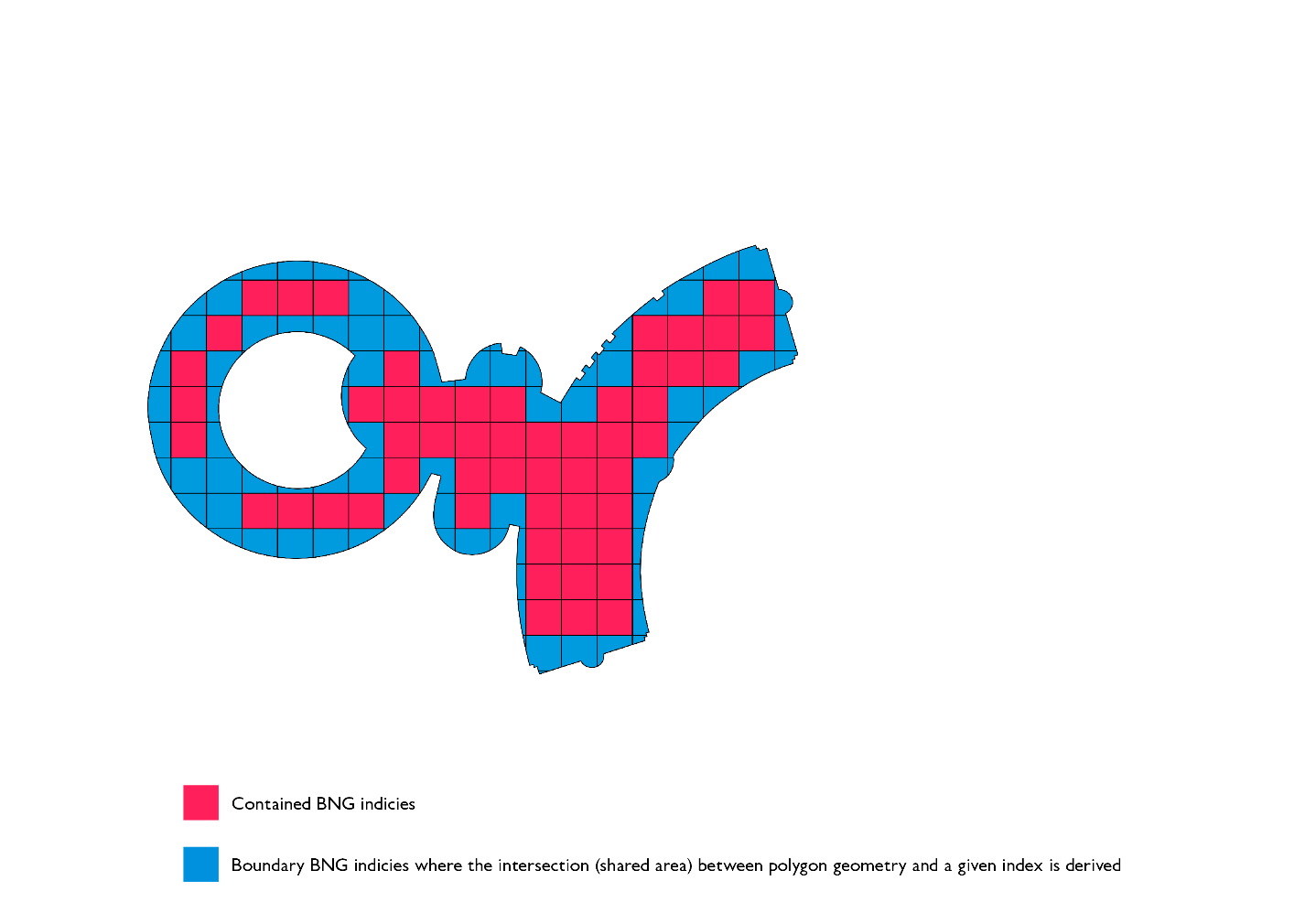
Polygon chips serve two purposes from the optimization perspective. Firstly, they vastly improve the efficiency of the PIP filter that occurs after the index-to-index join is executed. This is due to the fact that the ray tracing algorithm runs in O(v) complexity and individual chips on average have an order of magnitude fewer vertices than the original geometry. Secondly, the representation of chips is much smaller than the original geometry, as a result of this, we are shuffling much less data as part of the shuffle stage in our sort merge join stage.
Putting all of these together yields the following code:
This code is very similar to the original bounding box methods, and we have only done a few minor changes to make sure we are not duplicating some portions of the code; hence, we have isolated the add_children helper method.
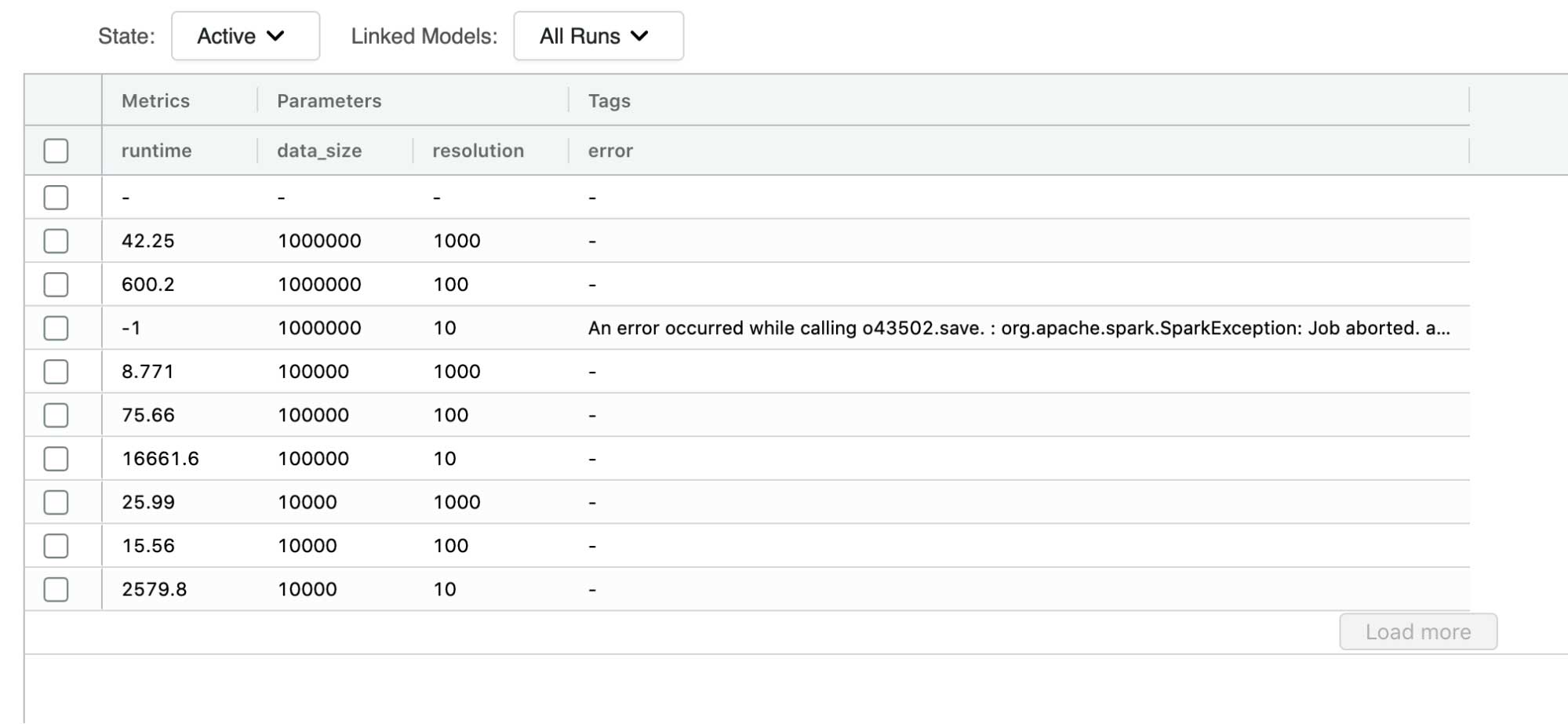
We have performed the same data generation benchmarking as we have done for our bounding box polygon representation. One thing we found in common with the original approach is that resolutions below 100m were causing over-representation of the polygons. In this case, we were, however, able to generate data up to 100 thousand polygons on a resolution of 10m, granted the runtime of such data generation process was too slow to be considered for production workloads.
At the resolution of 100m, we have got some very promising results; it took about 600 seconds to generate and write out the dataset of 1 million polygons. For reference, it took about 300 seconds to do the same for the bounding box approach. Bounding box was a simpler procedure, and we are adding some processing time in the data preparation stage. Can we justify this investment?
Mosaics are pretty (fast!)
We have run the same benchmark for PIP joins using our mosaic data. We have adapted our join logic slightly in order to make sure our border set and core set of indices are both utilized correctly and in the most efficient way.
is_dirty column is introduced by our polyfill method. Any index that touches the border of the original geometry will be marked as dirty (i.e., is_dirty=True). These indices will require post-filtering in order to correctly determine if any point that falls into said index is contained within the comparing geometry. It is crucial that is_dirty filtering happens first before the pip_fiter call because the logical operators in Spark have a short-circuiting capability; if the first part of the logical expression is true, the second part won't execute.
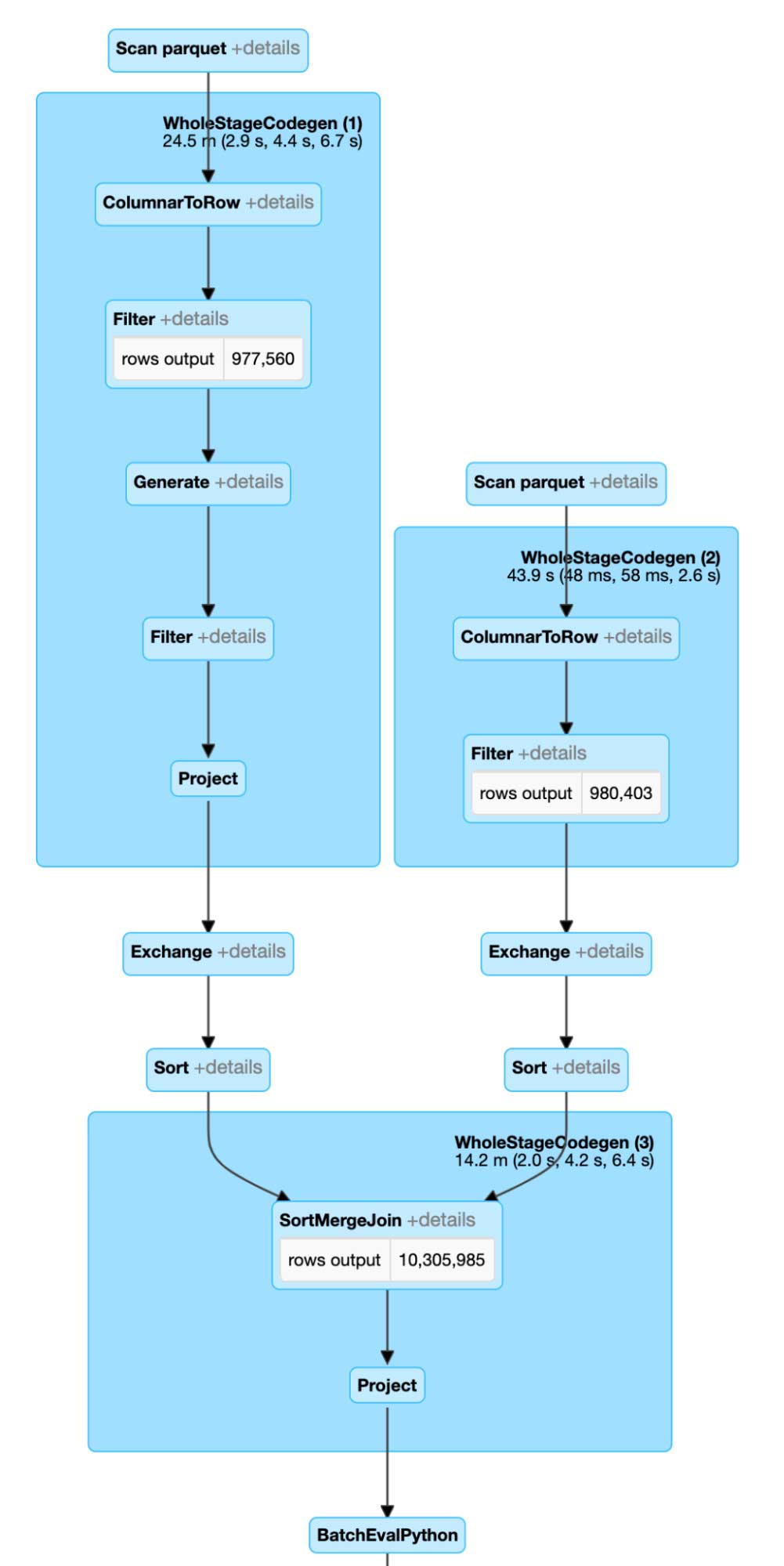
This code will yield a much more efficient execution plan in Spark. Due to better representation in the index space, our join surfaces are much smaller. In addition, our post-filters benefit from 2 set representation and mosaic splitting of the geometries.
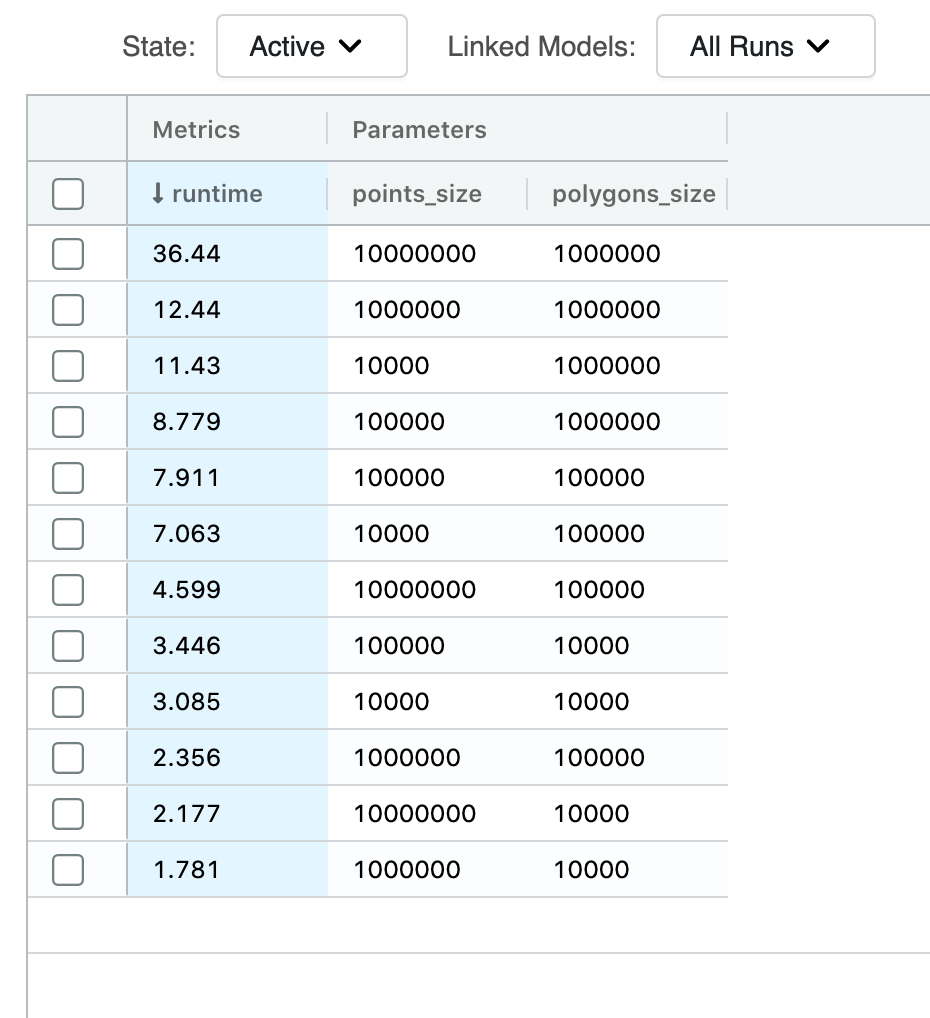
We can finally quantify our efforts. A PIP type join between 10 million points and 1 million polygons via our new mosaic approach has been executed in 37 seconds. To bring this into context, the bounding box equivalent join at the same index resolution was executed in 2549 seconds. This results in a 69X improvement in run time.
This improvement purely focuses on the serving run time. If we include the preparation times, which were 600 seconds for the mosaic approach and 317 seconds for the bounding box approach, we have the total adjusted performance improvement of 4.5X.
The total potential of these improvements largely depends on how often you are updating your geometrical data versus how often you query it.
A general approach
In this post, we have focused on Point in Polygon (PIP) joins using the British National Grid (BNG) as the reference index system. However, the approach is more general than that. The same optimizations can be adapted to any hierarchical geospatial system. The difference is that of the chip shapes and available resolutions. Furthermore, the same optimizations can help you scale up theta joins between two complex geometries, such as large volume polygon intersection joins.
Our focus remained on a PySpark first approach, and we have consciously avoided introducing any third-party frameworks. We believe that ensures a low barrier to consume our solution, and it is custom-tailored primarily to Python users.
The solution has proved that with few creative optimizations we can achieve up to 70 times the performance improvements of the bounding box approach with a minimal increase in the preprocessing investment.
We have brought large-scale PIP joins into the execution time domain of seconds, and we have unlocked the ad-hoc analytical capabilities against such data.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.