Turning 2 Trillion Data Points of Traffic Intelligence into Critical Business Insights
Open source utility project for Databricks
This is a guest authored post by Stephanie Mak, Senior Data Engineer, formerly at Intelematics.
This blog post offers my experience of contributing to the open source community with Bricklayer, which I'd started during my time at Intelematics. Bricklayer is a utility for data engineers whose job is to farm jobs, build map layers and other structures with geospatial data, which was built using Databricks Lakehouse Platform. Having to deal with a copious amount of geospatial data, Bricklayer makes it easier to manipulate and visualize geospatial data and parallelize batch jobs programmatically. Through this open source project, teams working with geospatial data are able to increase their productivity by spending less time writing code for these common functionalities.
Background
Founded in Melbourne in 2001, Intelematics has spent two decades developing a deep understanding of the intelligent transport landscape and its impact on customers. Over the years, a total data footprint of almost 2 trillion data points of traffic intelligence has been accumulated from smart sensors, vehicle probes in both commercial and private fleets, and a range of IoT devices. To make sense of this enormous amount of data, the INSIGHT traffic intelligence platform was created, which helps users with fleet GPS tracking and management and access to a single source of truth for planning, managing and assessing projects that require comprehensive and reliable traffic data and insights.
With the help of Databricks, the INSIGHT traffic intelligence platform is able to process 12 billion road traffic data points in under 30 seconds. It also provides a detailed picture of Australia’s road and movement network to help solve complex road and traffic problems and uncover new opportunities.
The INSIGHT team initially started our open source project, Bricklayer, as a way to monitor internal productivity and to address some of the pain points experienced when performing geospatial analysis and multi-processing. We were able to solve the inefficiencies in our workflow, which entailed switching between our online data retrieval tool (Databricks) and offline geospatial visualization tool (QGIS), and simplify performing arbitrary parallelization in pipelines. We then decided to join the open source community to help shape the foundation of the big data processing ecosystem.
GIS data transformation
The need for spatial analysis in Databricks Workspace
Spatial analysis and manipulation of geographical information was traditionally done by using QGIS, a desktop application running locally or in a server with features like support for multiple vector overlays and immediate visualization of geospatial query and geoprocessing results.
Our development of data transformation pipelines are implemented in a Databricks workspace. To support the fast iteration of data asset development, which progresses from analysis, design, implementation, validation and downstream consumptions, spatial analysis in the local environment is inefficient and impossible with the amount of data we have.
Building map layer to display in Databricks notebook
We decided to use folium maps to render geometry on map tileset such as OpenStreetMap and display in Databricks notebook.
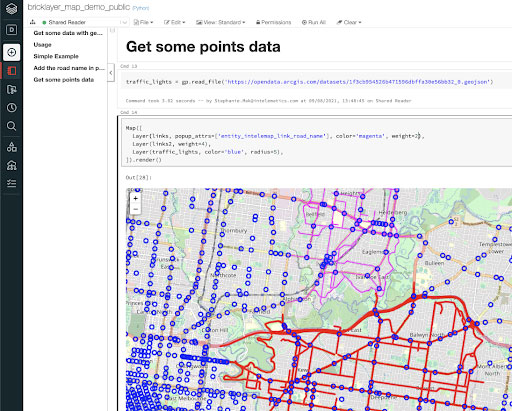
For an example of what this may look like, this public map demo notebook may provide some guidance on usage.
Scaling and parallel batch processing
The need for parallel batch processing
Geospatial transformation is computationally intensive. With the amount of data we have (96 timeslots per day for several years on hundreds of thousands of road segments), it would be impossible to load all data into memory even with the largest instance size in Databricks. Using a "divide and conquer" approach, data can be chopped along the time dimension into evenly distributed batches and be processed in parallel. Since this workload is running in Python, it was not possible to parallelize in threads and not trivial to use Apache Spark™ parallelization.
Job spawning using Jobs API
Databricks allows you to spawn jobs inline using the `dbutils.notebook.run` command; however, running the command is a blocking call, so you are unable to start jobs concurrently. By leveraging Databricks REST API 2.0, Bricklayer can spawn multiple jobs at the same time to address the parallelization problem. We wrap around some common use cases when dealing with jobs, such as creating new jobs with a new job cluster, job status monitoring or terminating the batch.
To trigger multiple jobs:
To retrieve specific jobs and terminate them:
What’s next
Databricks accelerates innovation by unifying workflow of data science, data engineering and business in a single platform. With Bricklayer, Intelematics’ mission is to create more seamless integration to make the life of engineers easier.
We are planning to continuously improve error messages to make them more useful and informative, auto generate tables in multiple formats based on schema provided in Avro and Swagger/ OpenAPI, and validate catalog according to schema. For more updated details please visit the roadmap.
About Intelematics
Founded in Melbourne in 2001, Intelematics has spent two decades developing a deep understanding of the intelligent transport landscape and what it can mean for our customers. We believe that the ever-increasing abundance of data and the desire for connectivity will fundamentally change the way we live our lives over the coming decades. We work with clients to harness the power of technology and data to drive smarter decisions and innovate for the benefit of their customers.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.