How Audantic Uses Databricks Delta Live Tables to Increase Productivity for Real Estate Market Segments
by Joel Lowery, Jitesh Soni, Prithish Mathews and Amit Kara
This is a collaborative post from Audantic and Databricks. We’d like to thank co-author Joel Lowery, Chief Information Officer - Audantic, for his contribution.
At Audantic we provide data and analytics solutions for niche market segments inside of single family residential real estate. We make use of real estate data to construct machine learning models to rank, optimize, and provide revenue intelligence to our customers to make strategic data-driven real estate investment decisions in real time.
We utilize a variety of datasets, including real estate tax and recorder data as well as demographics to name a couple. To build our predictive models requires massive datasets, many of which are hundreds of columns wide and into the hundreds of millions of records, even before accounting for a time dimension.
To support our data-driven initiatives, we had ‘stitched’ together various services for ETL, orchestration, ML leveraging AWS, Airflow, where we saw some success but quickly turned into an overly complex system that took nearly five times as long to develop compared to the new solution. Our team captured high-level metrics comparing our previous implementation and current lakehouse solution. As you can see from the table below, we spent months developing our previous solution and had to write approximately 3 times as much code. Furthermore, we were able to achieve a 73% reduction in the time it took our pipeline to run as well as saving 21% on the cost of the run.
| Previous Implementation | New Lakehouse Solution | Improvement | |
|---|---|---|---|
| Development time | 6 months | 25 days | 86% reduction in development time |
| Lines of code | ~ 6000 | ~ 2000 | 66% fewer lines of code |
In this blog, I’ll walk through our previous implementation, and discuss our current lakehouse solution. Our intent is to show you how our data teams reduced complexity, increased productivity, and improved agility using the Databricks Lakehouse Platform.
Previous implementation
Our previous architecture included multiple services from AWS as well as other components to achieve the functionality we desired, including a Python module, Airflow, EMR, S3, Glue, Athena, etc. Below is a simplified architecture:
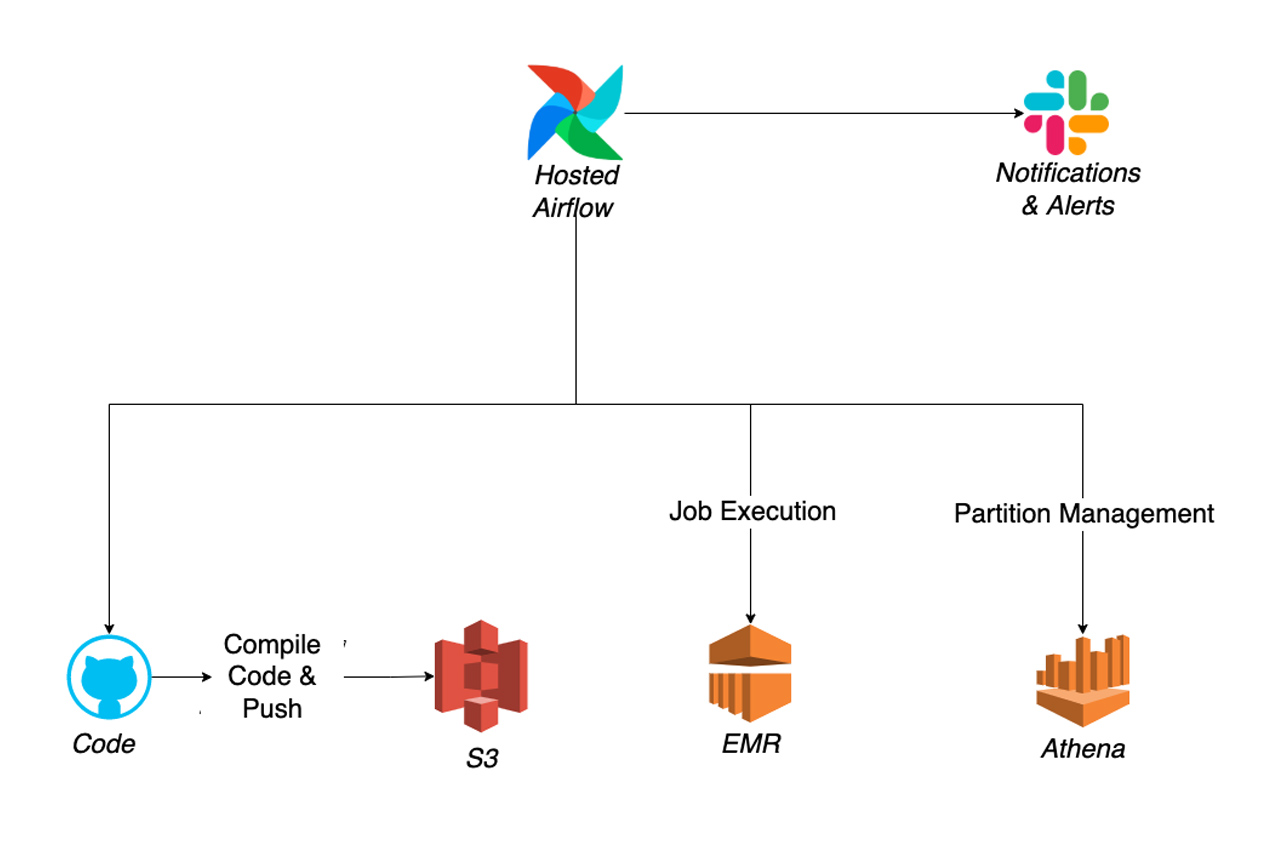
To summarize briefly, the process was as follows:
- We leveraged Airflow for orchestrating our DAGs.
- Built custom code to send email and Slack notifications via Airflow.
- The transformation code was compiled and pushed to S3.
- Created scripts to launch EMR with appropriate Apache Spark™ settings, cluster settings, and job arguments.
- Airflow to orchestrate jobs with the code pushed to S3.
- Table schemas were added with Glue and table partition management was done using SQL commands via Athena.
With the complexity of our previous implementation, we faced many challenges that slowed our forward progress and innovation, including:
- Managing failures and error scenarios
- Tasks had to be written in such a way to support easy restart on failures, otherwise manual intervention would be needed.
- Needed to add custom data quality and error tracking mechanisms increasing maintenance overhead.
- Complex DevOps
- Had to manage Airflow instances and access to the hosts.
- Had many different tools and complex logic to connect them in the Airflow DAGs.
- Manual maintenance and tuning
- Had to manage and tune (and automate this with custom code to the extent possible) Spark settings, cluster settings, and environment.
- Had to manage output file sizes to avoid too many tiny files or overly large files for every job (using parquet).
- Needed to either do full refreshes of data or compute which partitions needed to be executed for incremental updates and then needed to adjust cluster and Spark settings based on number of data partitions being used.
- Changes in the schemas of source datasets required manual changes to the code since input datasets were CSV files or similar with custom code including a schema for each dataset.
- Built logging into the Airflow tasks, but still needed to look through logs in various places (Airflow, EMR, S3, etc.).
- Lack of visibility into data lineage
- Dependencies between datasets in different jobs were complex and not easy to determine, especially when the datasets were in different DAGs.
Current implementation: Scalable data lakehouse using Databricks
We selected the Databricks Lakehouse Platform because we had been impressed by the ease of managing environments, clusters, and files/data; the joy and effectiveness of real-time, collaborative editing in Databricks notebooks; and the openness and flexibility of the platform without sacrificing reliability and quality (e.g. built around their open-sourced Delta Lake format which prevented us from being locked-in to a proprietary format or stack). We saw DLT as going another step to remove even more of the challenges presented by the prior implementation. Our team was particularly excited by the ease and speed of ingesting raw data stored on S3, supporting schema evolution, defining expectations for validation and monitoring of data quality, and managing data dependencies.
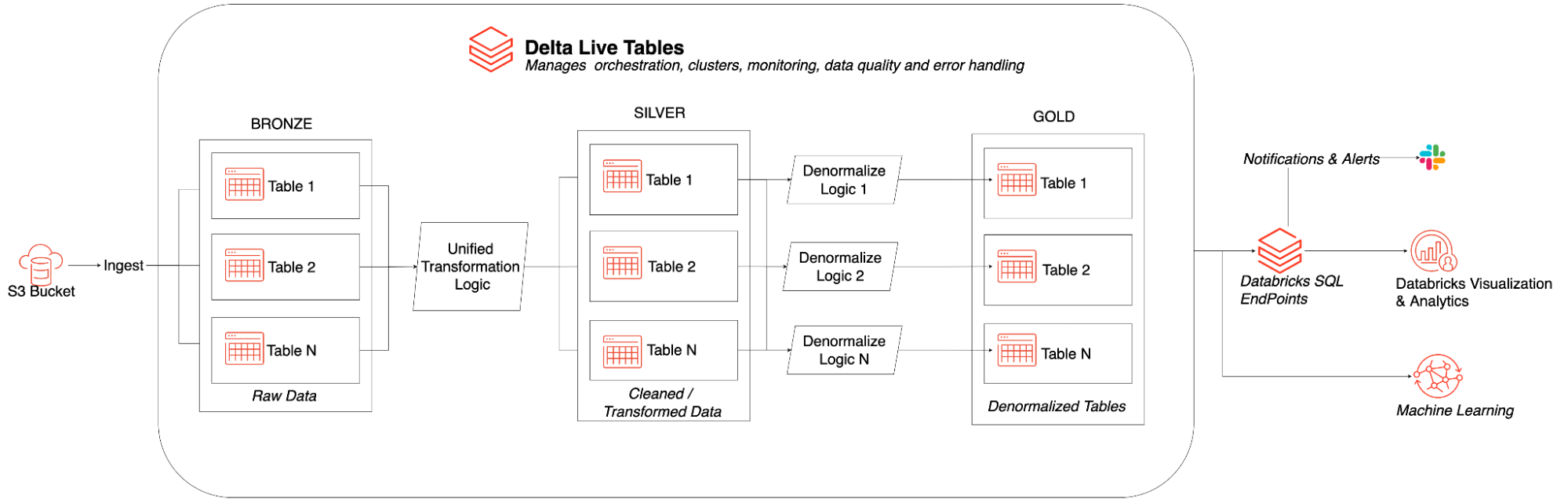
Benefits of Delta Live Tables
Delta Live Tables (DLT) made it easy to build and manage reliable data pipelines that deliver high-quality data on Delta Lake. DLT improved developer productivity by 380%, helping us deliver high quality datasets for ML and data analysis , much more quickly.
By using Delta Live Tables, we have seen a number of benefits including:
- Stream processing
- Built-in support for streaming with option to full refresh when needed
- Simpler DevOps
- Our team didn’t need to manage servers, since DLT managed the entire processing infrastructure .
- The administrators were able to easily manage Databricks users
- Smaller number of tools that functioned together more smoothly.
- For example:
- New implementation: tables created by DLT were immediately accessible with DB SQL.
- Previous implementation: table schema created with Glue and then new partitions added with Athena in addition to the underlying data created/added by a Spark job.
- For example:
- Streamlined maintenance and performance tuning
- Best practice by default with Spark and cluster settings in DLT.
- File size managed with auto-optimize and vacuum.
- Easy viewing of status, counts, and logs in DLT.
- Automatic data lineage
- DLT maintains data dependencies and makes lineage easy to view from the data source to the destination.
- Improved data quality
- Built-in data quality management with the ability to specify data quality expectations provides logging and option to ignore/drop/quarantine -- our previous implementation required separate, custom Airflow tasks and sometimes human intervention to manage data quality.
Working with Databricks SQL
Using Databricks SQL, we were able to provide analysts a SQL interface to directly consume data from the lakehouse removing the need to export data to some other tool for analytical consumption. It also provided us with enhanced monitoring into our daily pipelines via Slack notifications of success and failures.
Ingesting files with Auto Loader
Databricks Auto Loader can automatically ingest files on cloud storage into Delta Lake. It allows us to take advantage of the bookkeeping and fault-tolerant behavior built into Structured Streaming, while keeping the cost down close to batching.
Conclusion
We built a resilient, scalable data lakehouse on the Databricks Lakehouse Platform using Delta Lake, Delta Live Tables, Databricks SQL and Auto Loader. We were able to significantly reduce operational overhead by removing the need to maintain Airflow instances, manage Spark parameter tuning, and control dependency management.
Additionally, using Databricks’ technologies that innately work together instead of stitching together many different technologies to cover the functionality we needed resulted in a significant simplification. The reduction of operational overhead and complexity helped significantly accelerate our development life cycle and has already begun to lead to improvements in our business logic. In summary, our small team was able to leverage DLT to deliver high-value work in less time.
Future work
We have upcoming projects to transition our machine learning models to the lakehouse and improve our complex data science processes, like entity resolution. We are excited to empower other teams in our organization with understanding of and access to the data available in the new lakehouse. Databricks products like Feature Store, AutoML, Databricks SQL, Unity Catalog, and more will enable Audantic to continue to accelerate this transformation.
Next steps
Check out some of our resources for getting started with Delta Live Table
- Please watch this webinar to learn how Delta Live Tables simplifies the complexity of data transformation and ETL
- Get started with DLT guide
- Take a look at the short Delta Live Tables Demo
- Visit the Delta Live Tables homepage to learn more
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.