Build Reliable Production Data and ML Pipelines With Git Support for Databricks Workflows
by Vaibhav Sethi and Roland Fäustlin
We are happy to announce native support for Git in Databricks Workflows, which enables our customers to build reliable production data and ML workflows using modern software engineering best practices. Customers can now use a remote Git reference as the source for tasks that make up a Databricks Workflow, for example, a notebook from the main branch of a repository on GitHub can be used in a notebook task. By using Git as the source of truth, customers eliminate the risk of accidental edits to production code. They also remove the overhead of maintaining a production copy of the code in Databricks and keeping it updated, and improve reproducibility as each job run is tied to a commit hash. Git support for Workflows is available in Public Preview and works with a wide range of Databricks supported Git providers including GitHub, Gitlab, Bitbucket, Azure Devops and AWS CodeCommit.
Customers have asked us for ways to harden their production deployments by only allowing peer-reviewed and tested code to run in production. Further, they have asked for the ability to simplify the automation and improve reproducibility of their workflows. Git support in Databricks Workflows has already helped numerous customers achieve these goals.
"Being able to tie jobs to a specific Git repo and branch has been super valuable. It has allowed us to harden our deployment process, instill more safeguards around what gets into production, and prevent accidental edits to prod jobs. We can now track each change that hits a job through the related Git commits and PRs." - said Chrissy Bernardo, Lead Data Scientist at Disney Streaming
"We used the Databricks Terraform provider to define jobs with a git source. This feature simplified our CI/CD setup, replacing our previous mix of python scripts and Terraform code and relieved us of managing the 'production' copy. It also encourages good practices of using Git as a source for notebooks, which guarantees atomic changes of a collection of related notebooks" - said Edmondo Procu, Head of Engineering at Sapient Bio.
"Repos are now the gold standard for our mission critical pipelines. Our teams can efficiently develop in the familiar, rich notebook experience Databricks offers and can confidently deploy pipeline changes with Github as our source of truth - dramatically simplifying CI/CD. It is also straightforward to set up ETL workflows referencing Github artifacts without leaving the Databricks UI. " - says Anup Segu, Senior Software Engineer at YipitData
"We were able to reduce the complexity of our production deployments by a third. No more needing to keep a dedicated production copy and having a CD system, invoke APIs to update it." - says Arash Parnia, Senior Data Scientist at Warner Music Group
Getting started
It takes just a few minutes to get started:
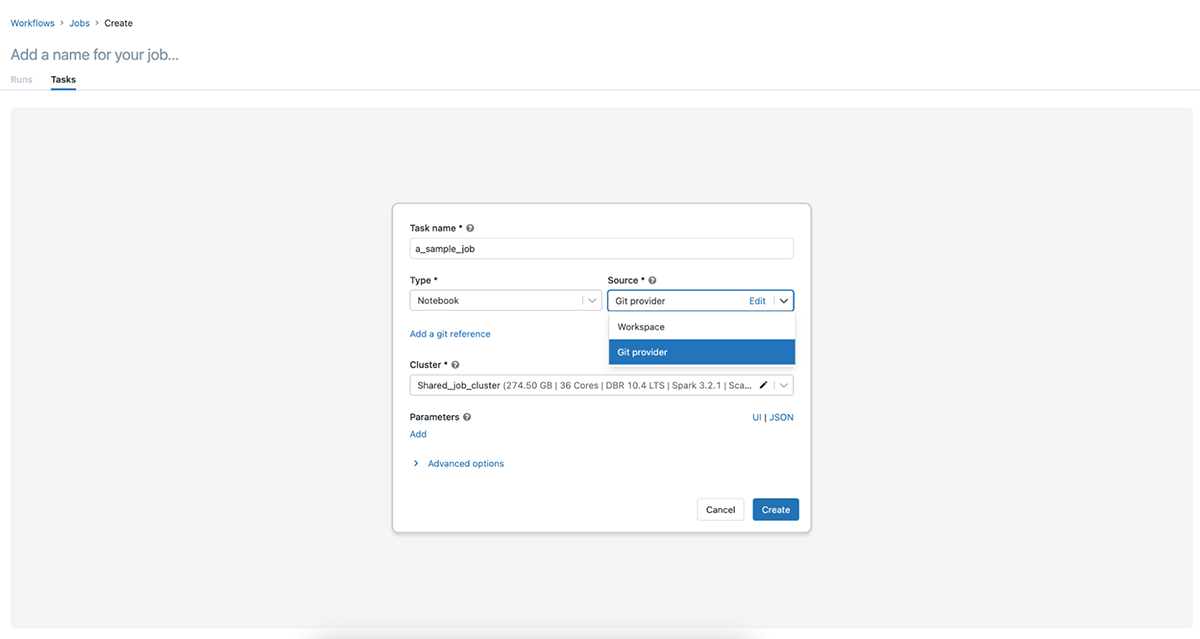
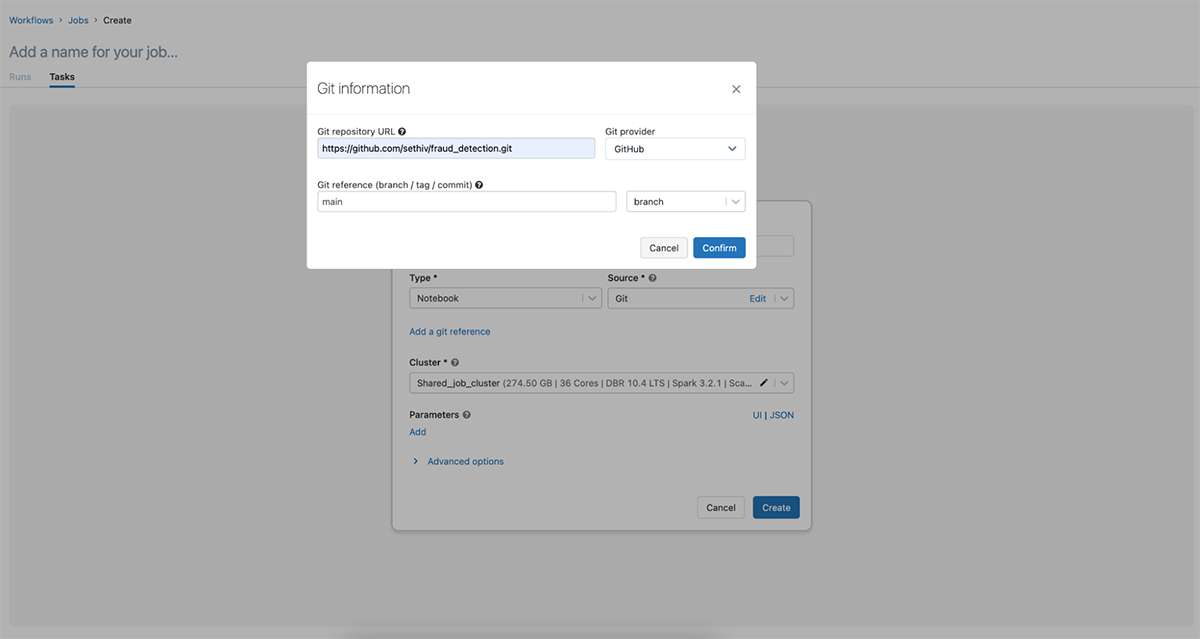
These actions can also be performed via v2.1 and v.2.0 of the Jobs API.
Once you have added the Git reference you can use the same reference for other notebook tasks in a job with multiple tasks.
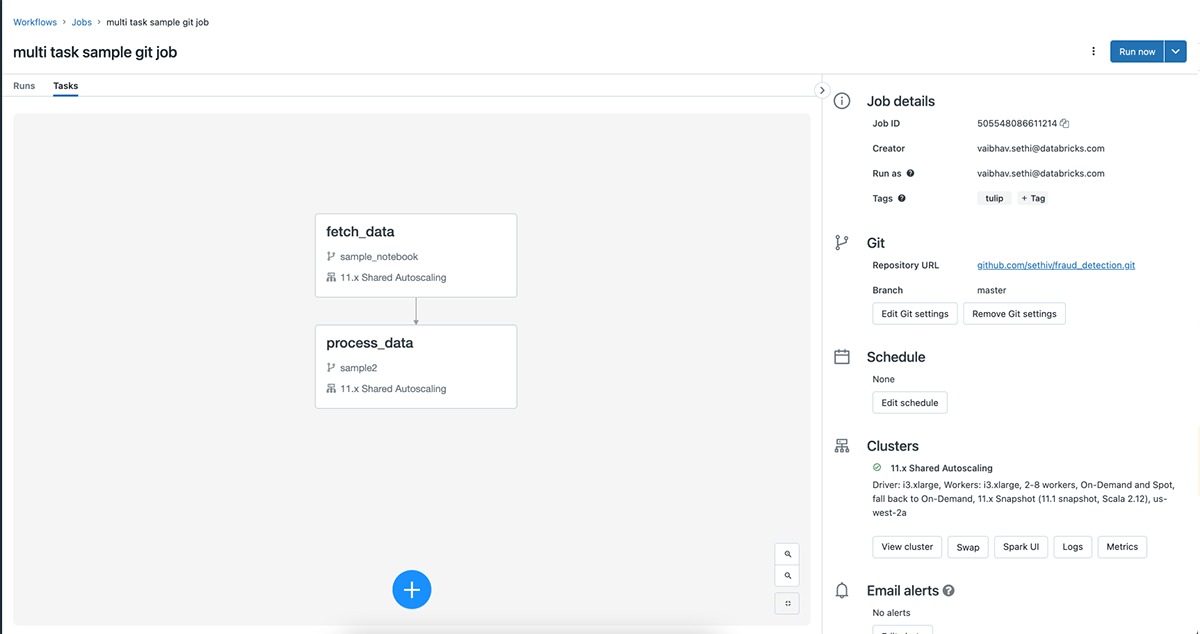
Every notebook task in that job will now fetch the pre-defined commit/branch/tag from the repository on every run. For each run the git commit SHA will be logged and it is guaranteed that all notebook tasks in a job are run from the same commit.
Please note that in a multitask job, there can't be a notebook task that uses a notebook in Databricks Workspace or Repos and another task that uses a remote repository. This restriction doesn't apply to non-notebook tasks.
- First, you will need to add your Git provider personal access token (PAT) token to Databricks. This can be done in the UI via Settings > User Settings > Git Integration or programmatically via the Databricks Git credentials API
- Next, create a Job and specify a remote repository, a git ref (branch, tag or commit) and the relative path to the notebook (relative to the root of the repository).
- Add more tasks to your job
- Run the job and view its details
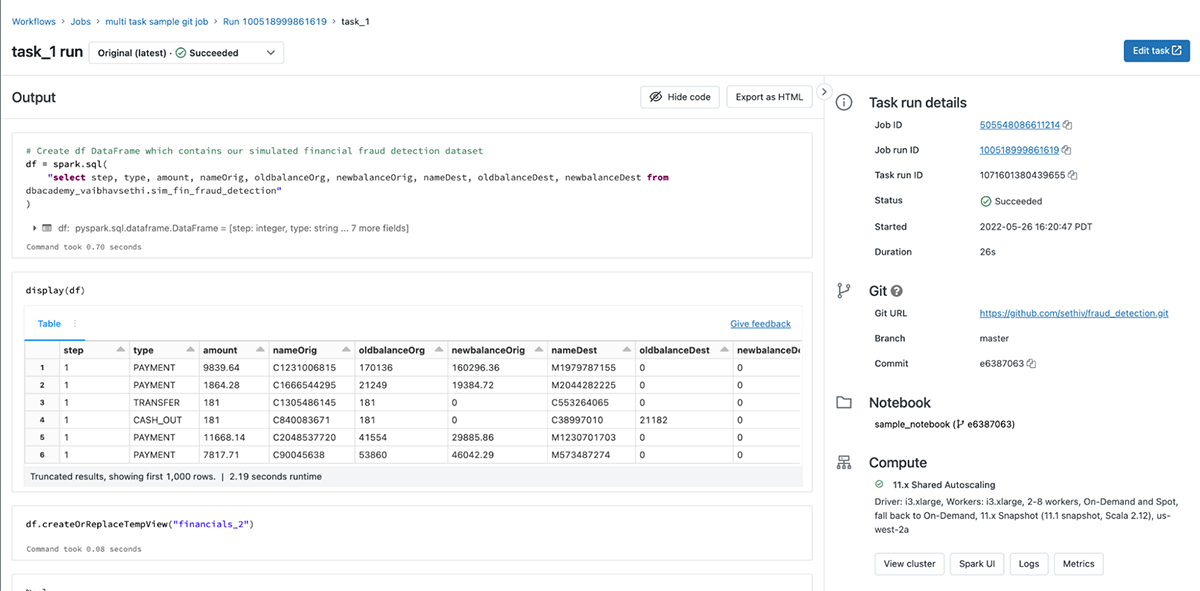
All Databricks notebook tasks in the job run from the same Git commit. For each run, the commit is logged and visible in the UI. You can also get this information from the Jobs API.
Ready to get started? Take Git support in workflows for a spin or dive deeper with the below resources:
- Dive deeper into Databricks Workflows documentation
- Check out this code sample and the accompanying webinar recording showing a end to end notebook production flow using Git support in Databricks workflows
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.