Parallel ML: How Compass Built a Framework for Training Many Machine Learning Models on Databricks
by Marshall Carter and Sujoy Dutta
This is a collaborative post from Databricks and Compass. We thank Sujoy Dutta, Senior Machine Learning Engineer at Compass, for his contributions.
As a global real estate company, Compass processes massive volumes of demographic and economic data to monitor the housing market across many geographic locations. Analyzing and modeling differing regional trends requires parallel processing methods that can efficiently apply complex analytics at geographic levels.
In particular, machine learning model development and inference are complex. Rather than training a single model, dozens or hundreds of models may need to be trained. Sequentially training models extends the overall training time and hinders interactive experimentation.
Compass' first foray into parallel feature engineering and model training and inference was built on a Kubernetes cluster architecture leveraging Kubeflow. The additional complexity and technical overhead was substantial. Modifying workloads on Kubeflow was a multistep and tedious process that hampered the team's ability to iterate. There was also considerable time and effort required to maintain the Kubernetes cluster that was better suited to a specialized devops division and detracted from the team's core responsibility of building the best predictive models. Lastly, sharing and collaboration were limited because the Kubernetes approach was a niche workflow specific to the data science group, rather than an enterprise standard.
In researching other workflow options, Compass tested an approach based on the Databricks Lakehouse Platform. The approach leverages a simple-to-deploy Apache Spark™ computing cluster to distribute feature engineering and training and inference of XGBoost models at dozens of geographic levels. Challenges experienced with Kubernetes were mitigated. Databricks clusters were easy to deploy and thus did not require management by a specialized team. Model training were easily triggered, and Databricks provided a powerful, interactive and collaborative platform for exploratory data analysis and model experimentation. Furthermore, as an enterprise standard platform for data engineering, data science, and business analytics, code and data became easily shareable and re-usable across divisions at Compass.
The Databricks-based modeling approach was a success and is currently running in production. The workflow leverages built-in Databricks features: the Machine Learning Runtime, Clusters, Jobs, and MLflow. The solution can be applied to any problem requiring parallel model training and inference at different data grains, such as a geographic, product, or time-period level.
An overview of the approach is documented below and the attached, self-contained Databricks notebook includes an example implementation.
The approach
The parallel model training and inference workflow is based on Pandas UDFs. Pandas UDFs provide an efficient way to apply Python functions to Spark Dataframes. They can receive a Pandas DataFrame as input, perform some computation, and return a Pandas DataFrame. There are multiple ways of applying a PandasUDF to a Spark DataFrame; we leverage the groupBy.applyInPandas method.
The groupBy.applyInPandas method applies an instance of a PandasUDF separately to each groupBy column of a Spark DataFrame; it allows us to process features related to each group in parallel.
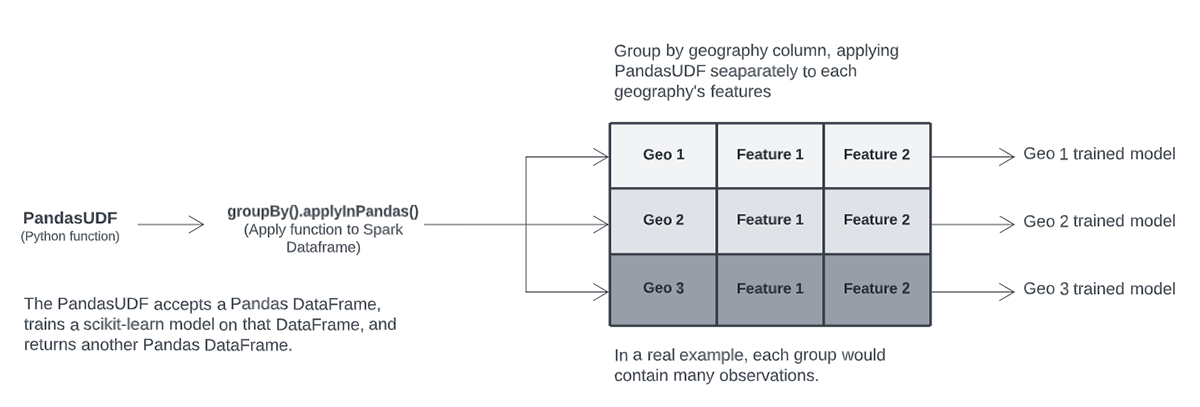
Our PandasUDF trains an XGBoost model as part of a scikit-learn pipeline. The UDF also performs hyper-parameter tuning using Hyperopt, a framework built into the Machine Learning Runtime, and logs fitted models and other artifacts to a single MLflow Experiment run.
After training, our experiment run contains separate folders for each model trained by our UDF. In the chart below, applying the UDF to a Spark DataFrame with three distinct groups trains and logs three separate models.
As part of a training run, we also log a single, custom MLflow pyfunc model to the run. This custom model is intended for inference and can be registered to the MLflow Model Registry, providing a way to log a single model that can reference the potentially many models fit by the UDF.
The PandasUDF ultimately returns a Spark DataFrame containing model metadata and validation statistics that is written to a Delta table. This Delta table will accumulate model information over time and can be analyzed using Notebooks or Databricks SQL and Dashboards. Model runs are delineated by timestamps and/or a unique id; the table can also include the associated MLflow run id for easy artifact lookup. The Delta-based approach is an effective method for model analysis and selection when many models are trained and visually analyzing results at the model level becomes too cumbersome.
The environment
When applying the UDF in our use case, each model is trained in a separate Spark Task. By default, each Task will use a single CPU core from our cluster, though this is a parameter that can be configured. XGBoost and other commonly used ML libraries contain built-in parallelism so can benefit from multiple cores. We can increase the CPU cores available to each Spark Task by adjusting the Spark configuration in the Advanced settings section of the Clusters UI.
spark.task.cpus 4
The total cores available in our cluster divided by the spark.task.cpus number indicates the number of model training routines that can be executed in parallel. For instance, if our cluster has 32 cores total across all virtual machines, and spark.task.cpus is set to 4, then we can train eight model's in parallel. If we have more than eight models to train, we can either increase the number of cluster cores by changing the instance type, adjusting spark.task.cpus, or adding more instances. Otherwise, eight models will be trained in parallel before moving on to the next eight.
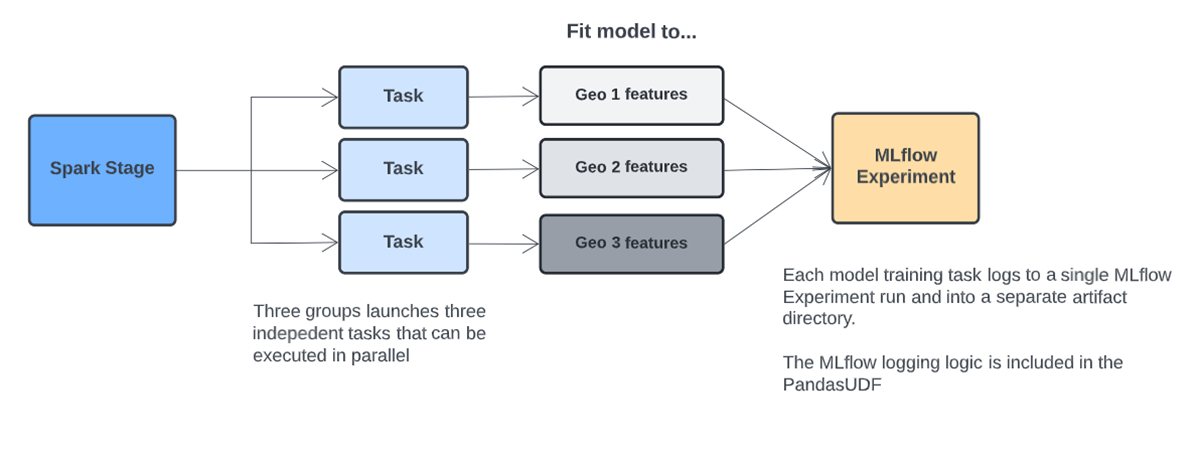
For this specialized use case, we disabled Adaptive Query Execution (AQE). AQE should normally be left enabled, but it can combine small Spark tasks into larger tasks. If fitting models to smaller training datasets, AQE may limit parallelism by combining tasks, resulting in sequential fitting of multiple models within a Task. Our goal is to fit separate models in each Task and this behavior can be confirmed using example code in the attached solution accelerator. In cases where group-level datasets are especially small and there are many models that are quick to train, training multiple models within a Task may be preferred. In this case, a number of models will be trained sequentially within a Task.
Artifact management and model inference
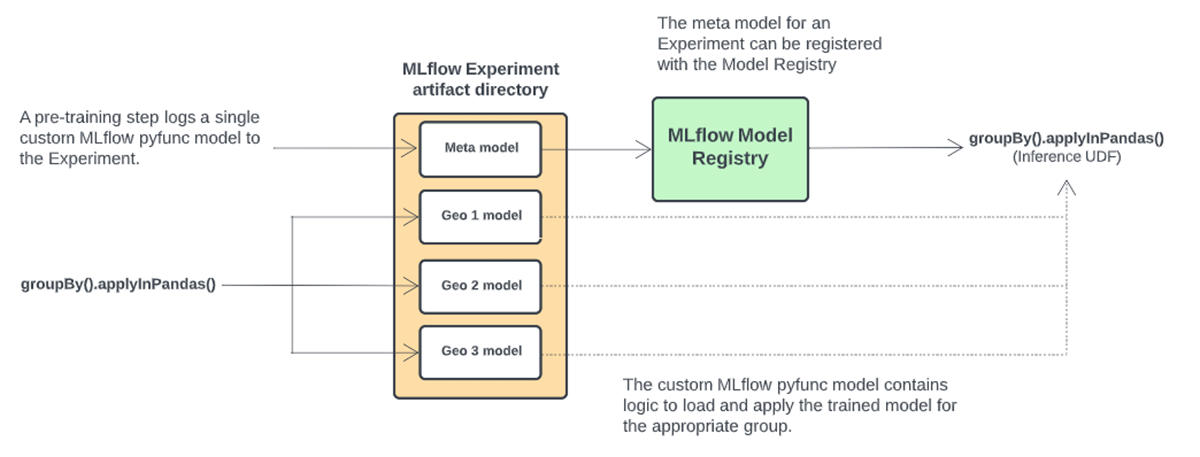
Training multiple versions of a machine learning algorithm on different data grains introduces workflow complexities compared to single model training. The model object and other artifacts can be logged to an MLflow Experiment run when training a single model. The logged MLflow model can be registered to the Model Registry where it can be managed and accessed.
With our multi-model approach, an MLflow Experiment run can contain many models, not just one, so what should be logged to the Model Registry? Furthermore, how can these models be applied to new data for inference?
We solve these issues by creating a single, custom MLflow pyfunc model that is logged to each model training Experiment run. A custom model is a Python class that inherits from MLflow and contains a "predict" method that can apply custom processing logic. In our case, the custom model is used for inference and contains logic to lookup and load a geography's model and use it to score records for the geography.
We refer to this model as a "meta model". The meta model is registered with the Model Registry where we can manage its Stage (Staging, Production, Archived) and import the model into Databricks inference Jobs. When we load a meta model from the Model Registry, all geographic-level models associated with the meta model's Experiment run are accessible through the meta model's predict method.
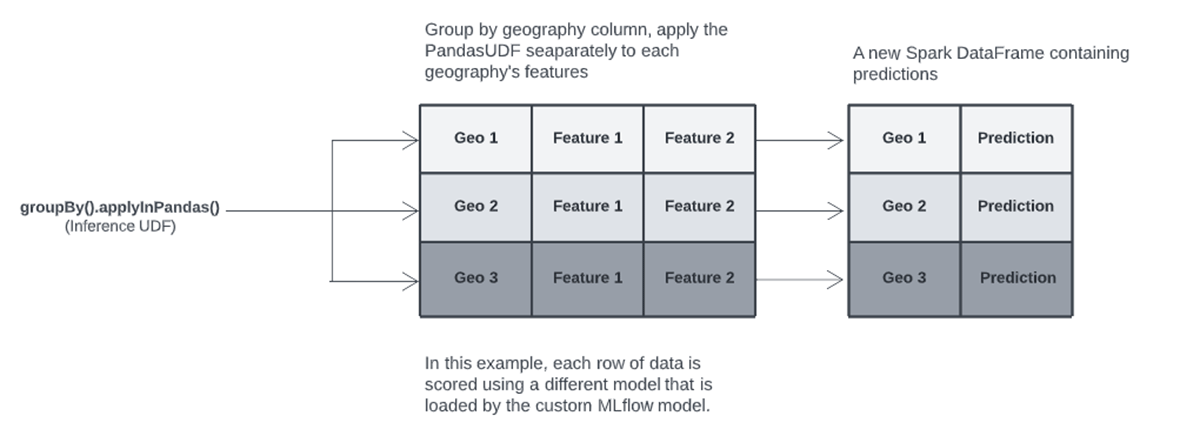
Similar to our model training UDF, we use a Pandas UDF to apply our custom MLflow inference model to different groups of data using the same groupBy.applyInPandas approach. The custom model contains logic to determine which geography's data it has received; it then loads the trained model for the geography, scores the records, and returns the predictions.
Model tuning
We leverage Hyperopt for model hyperparamter tuning and this logic is contained within the inference UDF. Hyperopt is built into the ML Runtime and provides a more sophisticated method for hyper-parameter tuning compared to traditional grid search, which tests every possible combination of hyper-parameters specified in the search space. Hyperopt can explore a broad space, not just grid points, reducing the need to choose somewhat arbitrary hyperparameters values to test. Hyperopt efficiently searches hyperparameter combinations using Baysian techniques that focus on more promising areas of the space based on prior parameter results. Hyperopt parameter training runs are referred to as "Trials".
Early stopping is used throughout model training, both at an XGBoost training level and at the Hyperopt Trials level. For each Hyperopt parameter combination, we train XGBoost trees until performance stops improving; then, we test another parameter combination. We allow Hyperopt to continue searching the parameter space until performance stops improving. At that point we fit a final model using the best parameters and log that model to the Experiment run.
To recap, the model training steps are as follows; an example implementation is included in the attached Databricks notebook.
- Define a Hyperopt search space
- Allow Hyperopt to choose a set of parameters values to test
- Train an XGBoost model using the chosen parameters values; leverage XGBoost early stopping to train additional trees until performance does not improve after a certain number of trees
- Continue to allow Hyperopt to test parameter combinations; leverage Hyperopt early stopping to cease testing if performance does not improve after a certain number of Trials
- Log parameter values and train/test validation statistics for the best model chosen by Hyperopt as an MLflow artifact in .csv format.
- Fit a final model on the full dataset using the best model parameters chosen by Hyperopt; log the fitted model to MLflow
Conclusion
The Databricks Lakehouse Platform mitigates the DevOps overhead inherent in many production machine learning workflows. Compute is easily provisioned and comes pre-configured for many common use cases. Compute options are also flexible; data scientist's developing Python-based models using libraries like scikit-learn can provision single-node clusters for model development. Training and inference can then be scaled up using a Cluster and the techniques discussed in this article. For deep learning model development, GPU-backed single node clusters are easily provisioned and related libraries such as Tensorflow and Pytorch are pre-installed.
Furthermore, Databricks' capabilities extend beyond the data scientist and ML engineering personas by providing a platform for both business analysts and data engineers. Databricks SQL provides a familiar user experience to business analysts accustomed to SQL editors. Data engineers can leverage Scala, Python, SQL and Spark to develop complex data pipelines to populate a Delta Lake. All personas can leverage Delta tables directly using the same platform without any need to move data into multiple applications. As a result, execution speed of analytics projects increases while technical complexity and costs decline.
Please see the associated Databricks Repo that contains a tutorial on how to implement the above workflow, https://github.com/marshackVB/parallel_models_blog
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.