Sharing Context Between Tasks in Databricks Workflows
Databricks Workflows is a fully-managed service on Databricks that makes it easy to build and manage complex data and ML pipelines in your lakehouse without the need to operate complex infrastructure.
Sometimes, a task in an ETL or ML pipeline depends on the output of an upstream task. An example would be to evaluate the performance of a machine learning model and then have a task determine whether to retrain the model based on model metrics. Since these are two separate steps, it would be best to have separate tasks perform the work. Previously, accessing information from a previous task required storing this information outside of the job's context, such as in a Delta table.
Databricks Workflows is introducing a new feature called "Task Values", a simple API for setting and retrieving small values from tasks. Tasks can now output values that can be referenced in subsequent tasks, making it easier to create more expressive workflows. Looking at the history of a job run also provides more context, by showcasing the values passed by tasks at the DAG and task levels. Task values can be set and retrieved through the Databricks Utilities API.
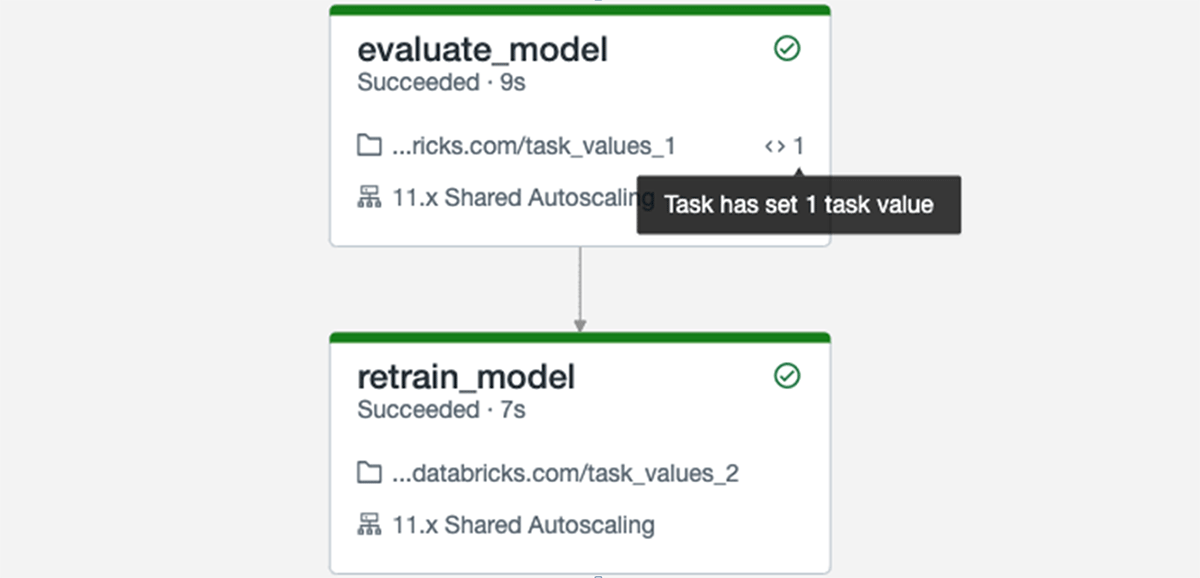

Task values are now generally available. We would love for you to try out this new functionality and tell us how we can improve orchestration even further!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.