Better Data for Better Decisions in the Public Sector Through Entity Resolution - Part 1
Data Quality Challenges
by Robert Whiffin, Milos Colic, Marcell Ferencz, Pritesh Patel, Richard Wilson and Edward Kelly
One of the domains where better decisions mean a better society is the Public Sector. Each and every one of us has a vested interest in making the Public Sector as efficient and effective as possible. The decisions made by civil servants have the potential to affect every citizen to a greater or lesser degree. This could be as mundane as scheduling road resurfacing work, or as extraordinary as coordinating the country's pandemic response. A common theme behind all of these decisions is the use of data; how should resurfacing works be prioritized? How should resources be used in dealing with an unprecedented event such as the coronavirus pandemic? How do we make our society more sustainable? How do we attain the net 0 target?
The quality of the data used to inform decisions directly correlates to the quality of the decision made; a decision made in the absence of relevant information is by definition incomplete and biased. A common reason for making decisions on incomplete information is the difficulty of retrieving the complete set of information available. The reality in many organizations, not just in the Public Sector, is that of data silos built over many years, resulting in long effortful processes to bring everything together. Often the underlying issue is the disconnected nature of the data within these systems. Even though the data may represent the same entity (e.g. a citizen), because of the different collection times, methods and hardware there is no simple way to join these different datasets together.
Joining different datasets which represent the same underlying entity is at the core of making better decisions. Working out whether multiple records in a dataset are referencing the same real-world concept is of fundamental value. This could be anything - a person, an organization, or any kind of entity. For example, imagine a school having 120 current students and 380 former students (500 in total). However the reports are showing 501 different student records, including "Fred Smith" and "Freddy Smith" as separate records, even though there is only one student named Fred Smith in the school. To a computer, these look different. Entity resolution is the process through which these different representations are connected, and through which we achieve a 360 degree view on data.
In this post, we will consider what "better data" means and how better data impacts decisions.
Better data
The UK Government Data Quality Framework sets out an approach for all civil servants to fulfill their responsibility of establishing whether the data they manage and use is fit for purpose; to do that, through data quality work that is proactive, evidence-based and targeted. This data quality framework defines several dimensions through which we ensure that data is fit for purpose: Completeness, Uniqueness, Consistency, Timeliness, Validity and Accuracy. The framework is a commitment towards the Data Foundation pillar of National Data Strategy which looks at how we can leverage existing UK strengths to boost the better use of data (make better decisions) across businesses, government, civil society and individuals.
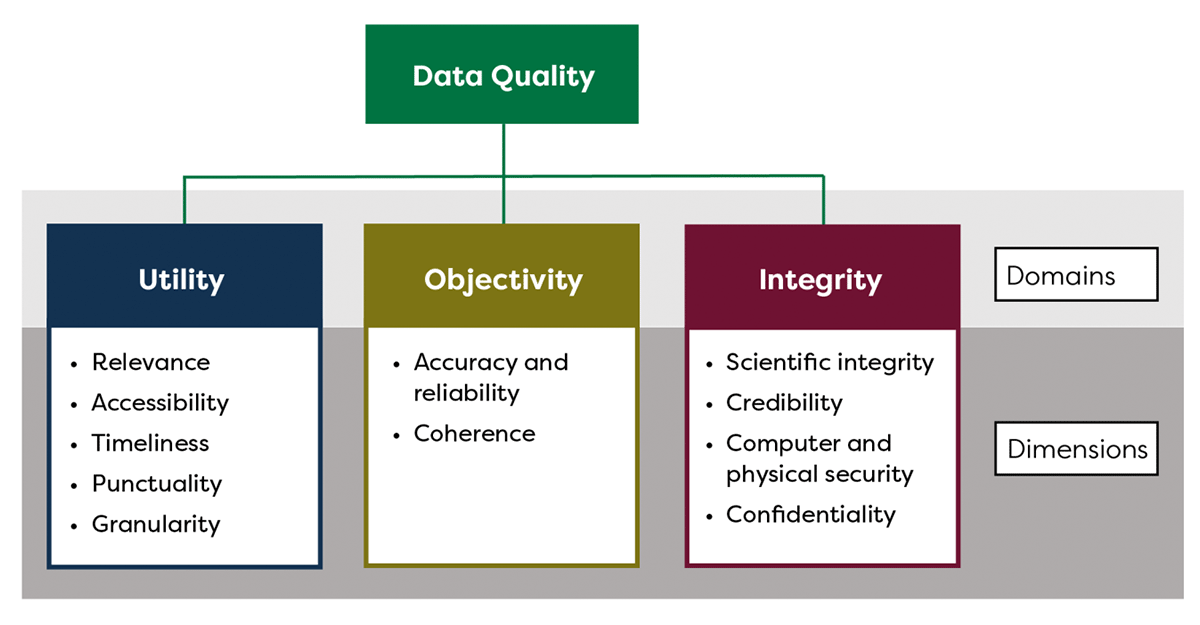
Similarly, Federal Committee on Statistical Methodology has provided a Data Quality Framework in 2020 and defines data quality as the degree to which data captures the desired information using appropriate methodologies in a manner that sustains the public trust. Beyond the dimensions that are largely similar between these frameworks, they have introduced the concept of public trust - after all the data is collected in order to increase the trust of the decision making process.
Finally, in September 2022, European Medicines Agency has put forth a draft proposal for Data Quality Framework for EU medicines regulation. It should come as a no surprise that the dimensions of data quality proposed are: Reliability (Precision, Accuracy and Plausibility), Extensiveness (Completeness and Coverage), Coherence (Format, Structure, Semantics, Uniqueness and Conformance), Timeliness (Currency/Lateness) and Relevance. EMA further states that for any regulatory activity it is critical to understand to which degree the data adheres to these concepts and that these concepts evolve throughout the data life cycle. Ultimately, data used for one use case can be repurposed (if ethical and regulatical rules adhere) for many other use cases and good data quality assures better interoperability.
Across these quality standards we can identify some key concepts that entity resolution can bring a large amount of value to.
Consistency
Every data professional is familiar with the story of the conflicting "sources of truth". When different systems report different information about the same concepts, time is spent on reconciling and understanding these inconsistencies. Imagine a database of students from an elementary school stores the following data about the students:
- Birthday in format year-month-day
- First name
- Last name
- Address in format street number, postcode, city
On the other hand, the highschool data of students may contain the following information:
- Birthday in format day/3 letter month/year
- First name and last name
- Address in format postcode, city
Combining these two views in order to provide, for example, government sponsored educational benefits would be very challenging since traditional relational data combination techniques would fail to solve the problem.Entity resolution offers a solution to condense these multiple representations into one.
Accessibility
It is an age old maxim - people follow the path of least resistance. The harder it is to get the necessary data, the less likely it is to be used, resulting in a need to create user friendly, accessible datasets which decision-makers and analysts can use with minimal fuss and effort. Imagine an organization that provides access to an open data asset. Accessibility can further be expanded to accessibility to insight. Accessing data sources without the ability to access and extract the insights from the data isn't very useful. Entity resolution unlocks the insights and value otherwise hidden behind the forest of disparate and seemingly disconnected data assets. On top of this tall order, entity resolution has to itself be easy to access and easy to use in order to alleviate the already existing data access pains.
Completeness
Data completeness (and data coverage) answers for the amount of information captured in our data assets. It is often (if not always) the case that our data sources only partially represent the information and cover only for the use case that the data was collected for. Data that is siloed and hard to combine creates inefficiencies both for the data users and the decision-makers. It is common for these silos to exist because there is no natural way of joining the datasets together; the datasets do not share a common attribute or key, which is identical across records representing the same entity. Entity resolution allows for joining datasets which do not have these common keys.
Uniqueness
Uniqueness describes to which degree there is no duplication in the data. The aim of uniqueness is to ensure 360 view over concepts reducing the number of duplicates and partial views of the same individuals, organizations, and data rows in general. One of the principal use cases for ER is that of deduplication and insurance of uniqueness. Unique representation of entities is critical for correct statistical representation of reality such as ONS inflation and price indices, Eurostat population and demography data, National Health and Nutrition data, …
These 4 areas all share a common thread: efficiency. Time spent compiling datasets is time not spent analyzing and understanding the data. Those with the skills to write complex data manipulation queries should be freed up to do so, whilst those with the need to access complete, consistent data should be able to do so without a dependency on other teams. This is reflected in the first mission of the UK National Data Strategy - unlocking the value of data across the economy. Putting all of these concepts together we can attain a common understanding of "better data": an accessible data asset that is coherent with both internal and external (trusted) data assets and when combined with said assets it provides a complete picture of concepts and entities without replication.
Finally, it is worth noting that solving the data quality is not a one-off job but an undertaking that requires a continual process to handle constantly arriving new data. This in turn means that traditional approaches will struggle to handle both the scale and complexity of the challenge. Consider the volume of data that needs processing - events like financial year end will result in huge increases in the amount of data compared to a typical day. Traditional on-premise approaches to infrastructure result either in costly capacity which sits mostly unused except for the rare spikes in demand, or considerable delays at crunch time as what is required for a typical day fails when demand spikes.
How can better data improve decision-making?
Timeliness
How much time do analysts spend finding, verifying and collating their data? Is data at their fingertips ready to use, or are they spending days combing through different systems and cross checking conflicting sources? If that time is reduced, your overall decision time is reduced without impacting on quality. Furthermore, the efficiency of individuals is increased yielding better work satisfaction.
Quality
How up-to-date is the data your decision is based on? How complete is it? If your decision is based on just a subset of the available data, there is the potential that the remaining data may have influenced your decision in a different direction. This is not to say that more data always makes for better decisions - however not including existing data due to accessibility or findability does lead to incomplete information and incomplete decisions.
Effort
How much resource is expended in producing data for decision making? Does it require a team of skilled engineers, or is access freely available regardless of technical ability? The harder the data is to get, the less likely it is to be used.
A testament to the truthfulness of these statements can be found in the fact that the Federal Chief Data Officers (CDO) Council comprised of roughly 90 chief data officers is leading the charge in the U.S. Federal Government in an effort to undertake one of the largest Federal transformation initiatives in decades. The aim is "to transform all Federal agencies to enable data-driven decision making in a fast-paced, changing, and competitive world and national economy" - Forbes. Data permeates all of the decisions surrounding us, such as global foreign policy initiatives, stewardship of natural resources, evidence based policy making, COVID-19 response. Similarly, the UK National Data Strategy proclaims the mission to unlock the value of data across the economy and to transform the Government's use of data.
It is of utmost value the fact that the governments and the regulators have recognized the value of good data quality and the value of decisions made from trusted quality data. Finally, the importance of good data quality is reflected not only in the decisions made but in the process of making those decisions - the individuals involved in the decision making process should focus on the interpretation of information and on serving the public rather than on data access and data quality.
Entity Resolution for better data
There are two fundamental questions underlying this issue: how easy is it to get data, and how useful is it once you have it? These are the same fundamental questions underpinning the 2020 UK National Data Strategy. The NDS is all about improving the use of data in government. Doing this has to be done in a way that is governed, efficient, and scalable.
- Governed: The public sector holds great power and has the potential to drastically impact on citizen's day to day lives. Controlling and monitoring who can access this data and what they can do with it, especially after it has been brought together to make it easy to use is going to be paramount to maintaining trust and transparency that the public sector is there to serve the citizenry. This means having a technological solution which is flexible enough to meet the needs of the user, and simple enough that the complexity of managing large organizations is not overwhelming and liable to create loopholes and accidental breaches.
- Efficient: Government has a duty to use taxpayer's money wisely. Use machines to do the things that machines are good at, and use people to do the things that people are good at. Don't let a skilled engineer or analyst burn time due to outdated systems that could be spent on a valuable project making full use of their skills. From a technology perspective, this means using modern advances in machine learning to automate the boring stuff, and let people focus on the interesting bits.
- Scalable: This refers to both the technology side of things in terms of using elastic cloud resources that can scale up and down to meet demand, and also the higher level approach. Specifically in the sense of Entity Resolution, it would work to hire thousands of people to comb through your data and manually check if two records are the same. Is it feasible? Absolutely not. You need to consider using modern ML based approaches that can do the easy bits, and let the valuable human time get spent on the difficult bits.
Conclusion
The Public Sector is unique in the scale and scope of its reach and its duty to provide value to and for the citizens it serves. Small changes can have large impacts in the context of such large organizations. In this post we have introduced the what, how and why of entity resolution as a general concept, and in January we will be running an enablement workshop in partnership with the National Innovation Centre for Data, Microsoft Azure, and the Ministry of Justice's Analytical Services team on a practical example using Splink, an open source entity resolution tool developed by the MoJ and in use across public and private sector globally. This workshop will be open to data practitioners across the UK Public Sector - stay tuned for more information and for followup blogs in this series.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.