Training LLMs with AMD MI250 GPUs and MosaicML
With the release of PyTorch 2.0 and ROCm 5.4, we are excited to announce that LLM training works out of the box on AMD MI250 accelerators with zero code changes and at high performance!
At MosaicML, we've searched high and low for new ML training hardware on behalf of our customers. We do this to increase compute availability (as the world is in an NVIDIA supply crunch!), expand and educate the market, and ultimately reduce times and costs to train models. We believe that a competitive market for ML training hardware is critical to reducing prices for our customers. Our requirements for new hardware are simple:
- Real Workloads: Support for LLM training in 16-bit precision (FP16 or BF16), with the same convergence and final model quality as when we train on NVIDIA systems.
- Speed and Cost: Competitive performance and performance-per-dollar.
- Developer experience: Minimal code changes from our existing training stack (PyTorch, FSDP, Composer, StreamingDataset, LLM Foundry).
None have met the test. Until now.
With PyTorch 2.0 and ROCm 5.4+, LLM training works out of the box on AMD MI250 accelerators with zero code changes when running our LLM Foundry training stack.
Some highlights:
- LLM training was stable. With our highly deterministic LLM Foundry training stack, training an MPT-1B LLM model on AMD MI250 vs. NVIDIA A100 produced nearly identical loss curves when starting from the same checkpoint. We were even able to switch back and forth between AMD and NVIDIA in a single training run!
- Performance was competitive with our existing A100 systems. We profiled training throughput of MPT models from 1B to 13B parameters and found that the per-GPU throughput of MI250 was within 80% of the A100-40GB and within 73% of the A100-80GB. We expect this gap will close as AMD software improves.
- It all just works. No code changes were needed.
Today's results are all measured on a single node of 4xMI250 GPUs, but we are actively working with hyperscalers to validate larger AMD GPU clusters, and we look forward to sharing those results soon! Overall our initial tests have shown that AMD has built an efficient and easy-to-use software + hardware stack that can compete head to head with NVIDIA's.
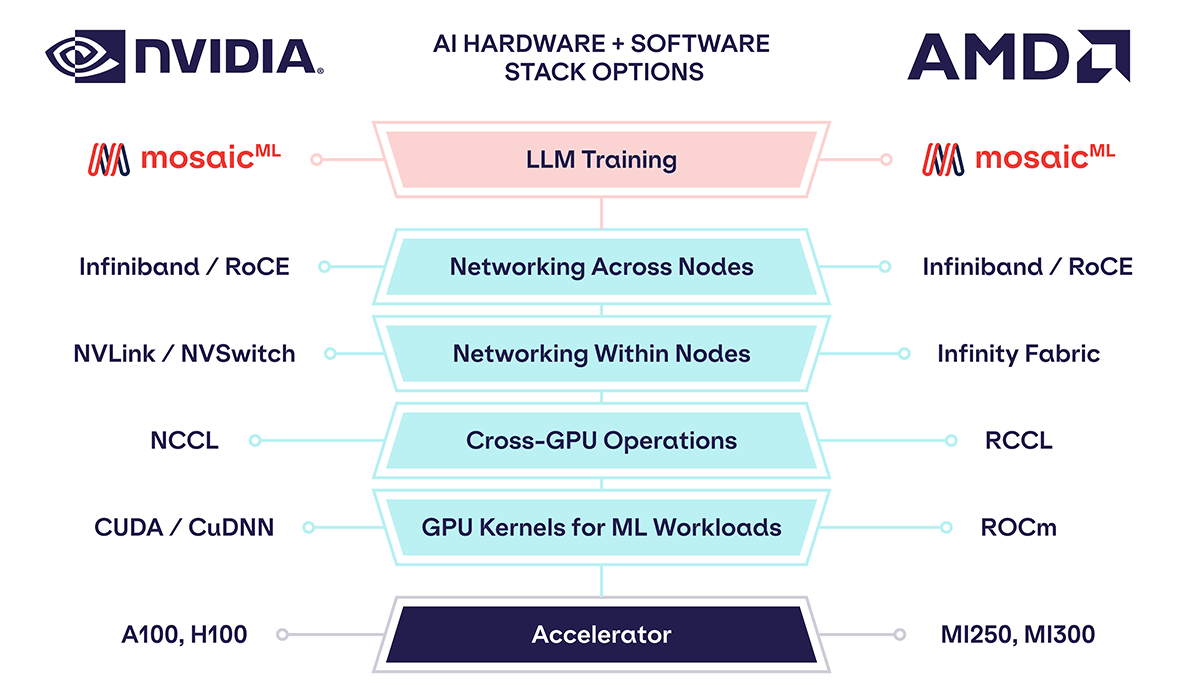
Accelerator: AMD MI250 GPU
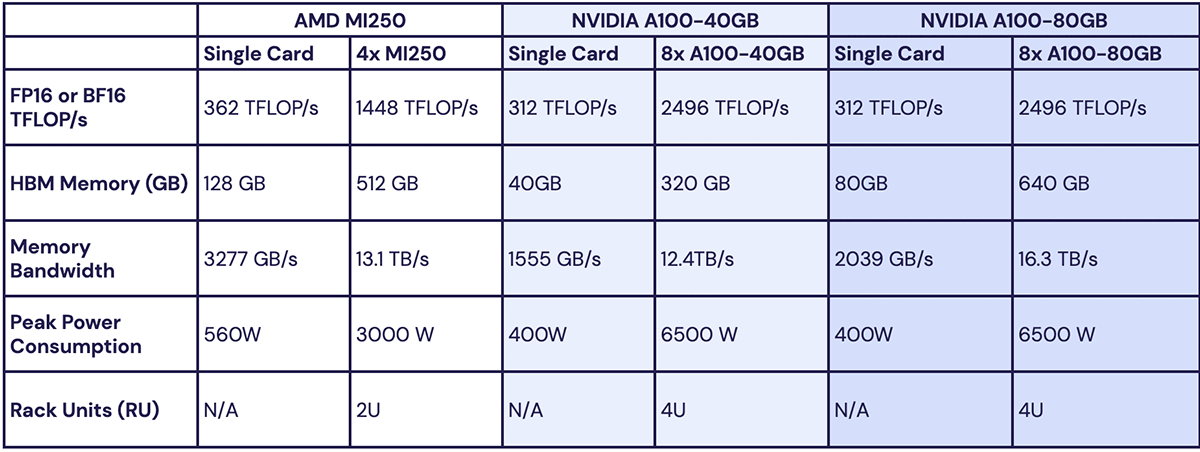
The AMD MI250 is a datacenter accelerator similar to the NVIDIA A100, with High Bandwidth Memory (HBM) and Matrix Cores that are analogous to NVIDIA's Tensor Cores for fast matrix multiplication. When training ML models at MosaicML we always use 16-bit precision, so we focus on 16-bit formats for performance comparisons. See Table 1 for details.
Some noteworthy differences between MI250 and A100 are:
- The MI250 can perform a higher peak number of trillion floating-point operations per second (TFLOP/s) than A100 in FP16 or BF16.
- The MI250 has a larger amount of HBM memory (128GB) than even the largest A100 (80GB). This means the MI250 can hold larger models for training or inference.
- The max power consumption for a single MI250 is higher than for a single A100. But when looking at system power consumption in a node, the power per GPU is about the same, or a little better for AMD.
- The MI250 traditionally comes in systems or "blades" or "nodes" with 4 GPUs, whereas the A100 traditionally comes in systems with 8 GPUs.
Overall, the MI250 has a slight edge in FLOP/s, HBM Memory, and Memory Bandwidth. But the MI250 GPUs usually come packaged in smaller system configurations, which means to reach a given compute target, you need to buy twice the number of AMD systems than NVIDIA systems.
Platform: ROCm, RCCL, Infinity, RoCE
Good software has been the Achilles' heel for most ML training chip companies. Their customers, data scientists and ML engineers, are used to working at a high level of abstraction with frameworks like PyTorch or TensorFlow. When training with NVIDIA GPUs, these frameworks translate user code to a large collection of NVIDIA software:
- CUDA/cuDNN: high-performance proprietary GPU kernels for matrix multiplication, convolution, normalization, and other operations that ML models use. CUDA is closed-source and only runs on NVIDIA GPUs.
- NCCL: a communications library for high performance cross-GPU operations like gather, scatter, reduce that are used for distributed training. NCCL also only runs on NVIDIA GPUs.
On top of this, there is a layer of networking infrastructure that makes NVIDIA hardware attractive for distributed multi-gpu and multi-node workloads (and all serious ML workloads are distributed):
- NVLink / NVSwitch: high bandwidth interconnect within a node.
- Infiniband, or RDMA over Converged Ethernet (RoCE): high bandwidth interconnect across nodes. Infiniband has lower latency but tends to be more expensive than RoCE.
Unless a new hardware platform has significant performance benefits, most users have no incentive to spend time porting their software. With new model architectures and research coming out every day, waiting for software to catch up is simply not an option. Flexibility and compatibility with existing training frameworks is a must-have for new hardware platforms.
To answer these challenges, AMD has developed its own collection of software and networking infrastructure:
- ROCm replaces CUDA
- RCCL replaces NCCL
- Infinity Fabric replaces NVSwitch within a node
- Infiniband or RoCE are similarly supported across nodes
At each layer of the stack, AMD has built software libraries (ROCm, RCCL), or networking infrastructure (Infinity Fabric), or adopted existing networking infrastructure (Infiniband or RoCE) to match NVIDIA's stack.
Note: In this blog, we were limited to a single node of 4xMI250 and so have not yet tested multi-node scaling. However, since we already use RoCE multi-node networking on NVIDIA systems to great success (see our earlier blogs), we are fairly confident that RoCE will work well on multi-node AMD systems as well.
"Everything Just Works" with PyTorch and LLM Foundry
How does all this work with our open-source LLM Foundry training stack?
- Start with a ROCm 5.4 Docker image: `rocm/dev-ubuntu-20.04:5.4.3-complete`
- Install PyTorch for ROCm 5.4: `pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2`
- Install ROCm-based FlashAttention following the instructions here.
- Run any of the LLM Foundry training or finetuning workloads with config settings:
- `model.attn_config.attn_impl=flash` rather than default `triton`.
- `model.loss_fn=torch_crossentropy` to use native torch CrossEntropyLoss rather than default `fused_crossentropy`.
That's it!
(We will soon share pre-built AMD GPU Docker images to replace installation steps 1-3.)
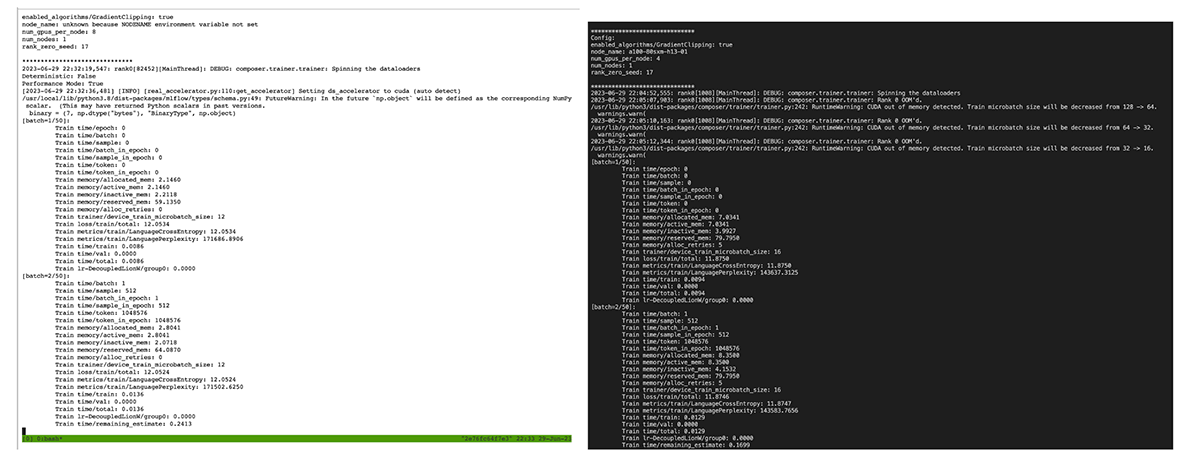
Under the hood, PyTorch is mapping every floating point operation, every GPU command, and every distributed operation like `torch.matmul()`, `torch.cuda.current_device()`, `inputs.to('cuda:0')`, `torch.dist.all_gather()`, etc. call to the appropriate ROCm and RCCL operations on the AMD system. See Figure 1 for screenshots of what this looks like. We agree, it's funny to run `torch.cuda` on an AMD machine, but it works!
The benefit of this approach is that existing PyTorch code requires no changes when switching from NVIDIA to AMD. Since our LLM Foundry codebase is built on top of pure PyTorch, it also works with no code changes. Even advanced distributed training algorithms like Fully Sharded Data Parallelism (FSDP) work seamlessly. In Figure 2 you can see what it looks like in your terminal when training an MPT model on an AMD system with LLM Foundry – it's exactly the same as on an NVIDIA system.

LLM Training Performance
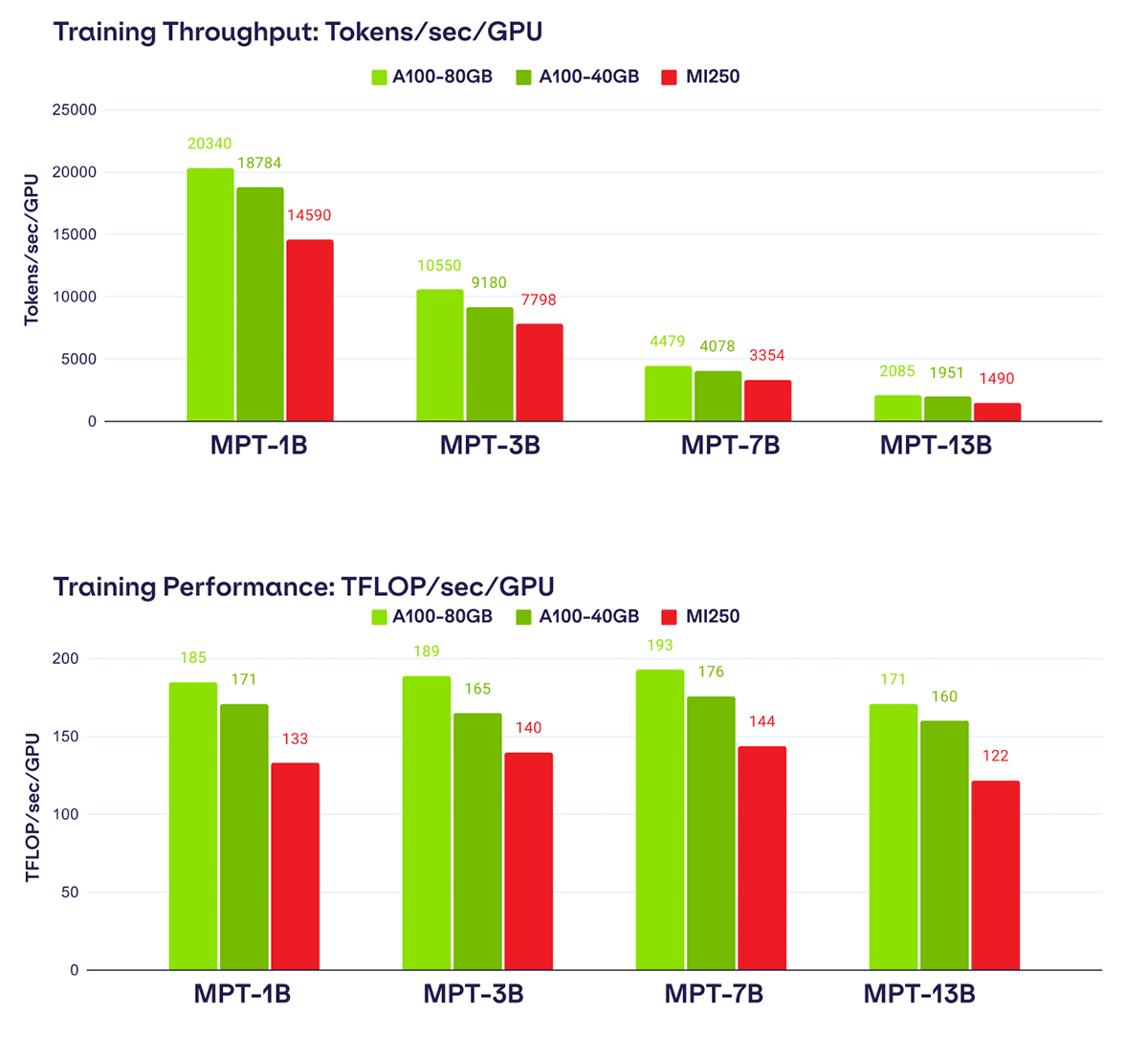
Let's get down to brass tacks: how fast is MI250? When looking at LLM training performance today, we find that the MI250 is ~80% as fast as A100-40GB and ~73% as fast as A100-80GB.
We arrive at these figures by measuring training throughput of MPT models from 1B to 13B parameters using LLM Foundry on three systems: 4xMI250-128GB, 8xA100-40GB, and 8xA100-80GB.
In each setting, we ran the exact same training scripts from LLM Foundry using BF16 mixed precision, FlashAttention (`triton`-based on NVIDIA systems and ROCm-based on AMD systems) and PyTorch FSDP with sharding_strategy: FULL_SHARD. We also tune the microbatch size for each model on each system to achieve maximum performance.
The results are plotted in Figure 3 with raw data available in Table 2. Overall we find that AMD MI250 achieves an average of ~80% of the per-GPU training throughput of A100-40GB and ~73% of A100-80GB across the different MPT models. We predict that AMD performance will get better as the ROCm FlashAttention kernel is improved or replaced with a Triton-based one: when comparing a proxy MPT model with `n_heads=1` across systems, we found a substantial lift that brings MI250 performance within 94% of A100-40GB and 85% of A100-80GB.
Given the consistent performance we see across many MPT model sizes, we believe that at the right price, AMD and NVIDIA systems are interchangeable for LLM training and we would recommend to use whichever one has higher availability or performance per dollar.
![Table 2: LLM Training throughput [Tokens/sec/GPU] and floating point performance [TFLOP/sec/GPU] for MPT models](https://www.databricks.com/sites/default/files/inline-images/training-llms-amd-mosaicml-img-6.png)
LLM Training Convergence
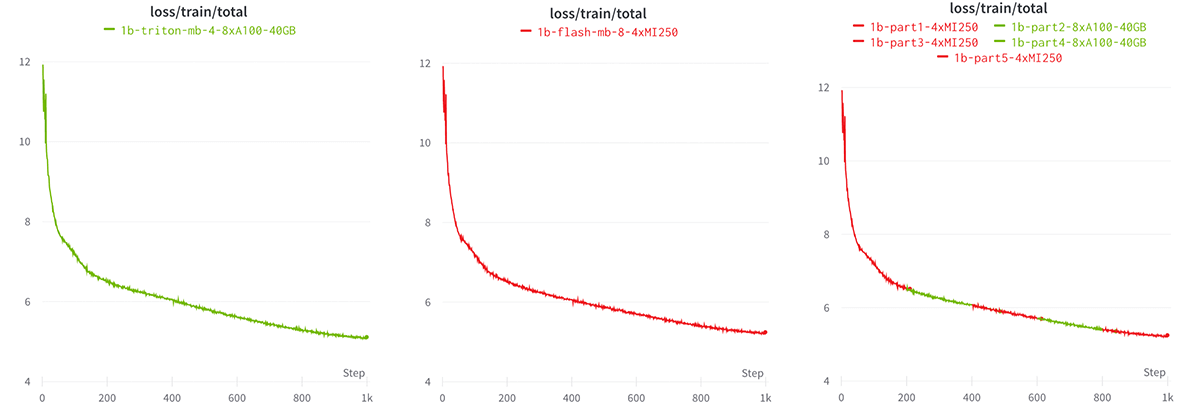
What if we go beyond profiling, and train some MPT models for real? Given that we only had a single node of 4xMI250 at the time of this blog, we limited our experiments to a small MPT-1B model. Despite the limitations, what we found was encouraging!
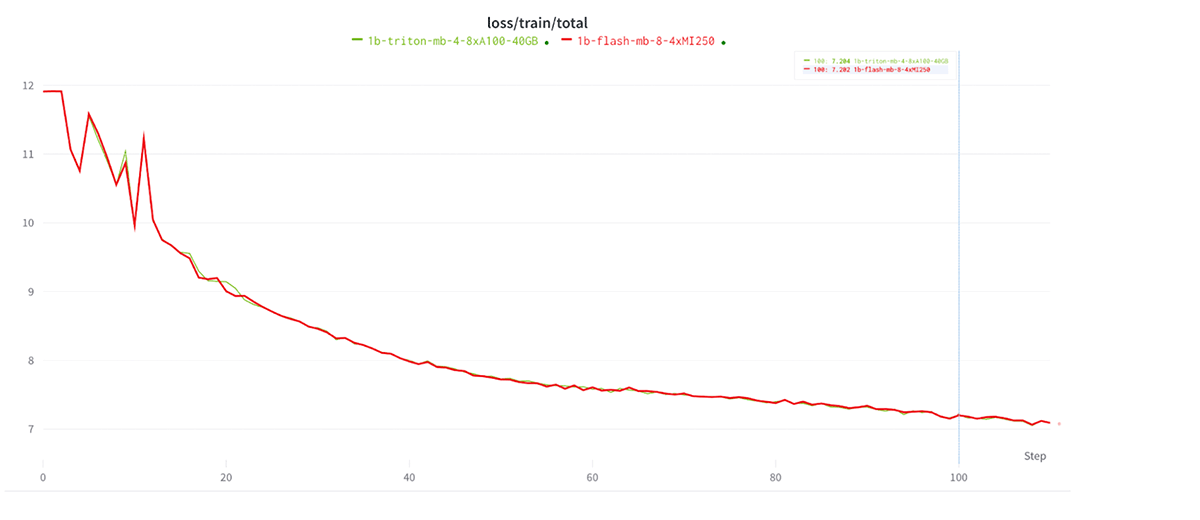
Starting from the same initial checkpoint, we trained an MPT-1B model on 1B tokens of the C4 dataset, either on an NVIDIA 8xA100-40GB system or an AMD 4xMI250-128GB system. To be specific, we trained for 1000 batches with a global batch size of 512 sequences, and a max sequence length of 2048 tokens. In Figure 4, we see that the loss curves are nearly identical over 1B tokens. We zoom in on the first 100 steps of training in Figure 5 and see that loss curves really are overlapping. Considering that these runs are on two totally different hardware stacks, seeing such consistency is a small miracle!
For fun, we perform the run a third time and switch back and forth between NVIDIA and AMD GPUs every 200 batches, using Composer's object store checkpointing to seamlessly save/load the checkpoints from one GPU cluster to another. See Figure 4.
This result is made possible by determinism at many levels of the stack:
- StreamingDataset provides elastic determinism while streaming data from object storage. Elastic determinism means that the set of samples in the global batch at timestep T is deterministic regardless of the # of nodes, # of devices, or # of CPU dataloader workers. This is important because we are reading from the same dataset in object store but with 4xMI250 vs. 8xA100-40GB.
- Composer's microbatching engine enables accurate gradient calculation regardless of the microbatch size used. This is important because on the 4xMI250-128GB system, we are using a microbatch size of 8, but on the 8xA100-40GB system we are using a smaller microbatch size of 4 due to less GPU memory.
- We use a shared initial weights checkpoint for all runs.
- We don't use any non-deterministic operations (e.g. Dropout).
- PyTorch FSDP and BF16 autocast are consistent across both systems.
- ROCm-based FlashAttention and Triton-based FlashAttention are numerically close.
- CUDA and ROCm kernels are numerically close.
- NCCL and RCCL distributed collectives are numerically close.
Overall, we are pleased to report that LLM training on AMD systems appears stable and consistent with training on NVIDIA systems. We look forward to larger scale convergence runs once we get access to larger AMD clusters!
What's next?
In this blog we've taken the first step toward validating AMD datacenter GPUs for modern ML workloads like training LLMs. We've also done so while using a simple training stack built on PyTorch, with zero code changes required to run on NVIDIA vs. AMD. If your codebase is also built on PyTorch, it might work out of the box on AMD too!
Next, we plan to profile larger models on larger clusters to confirm that AMD systems continue to perform at scale. We are actively partnering with hyperscalers today to do this, and we are excited to share results in the near future.
We're also looking forward to comparing AMD's new MI300x GPU against NVIDIA's latest H100 GPU. The H100s have just begun to arrive in cloud datacenters and are already showing great promise (see our H100 profiling blog here). But the MI300x is reported to have significantly higher memory capacity (192GB vs. 80GB) and memory bandwidth (5.2TB/s vs. 3.2TB/s). We don't yet know what the TFLOP/s numbers are for MI300x, but we are excited to find out!
We also plan to profile inference benchmarks as well as other workloads (e.g. diffusion models) on both NVIDIA and AMD systems in future blog posts.
Overall, we are incredibly optimistic about the future market for AI training hardware. More good options means more compute supply, more market pressure on prices, and ultimately lower costs for users who want to train their own models. We are thrilled to see promising alternative options for AI hardware, and look forward to evaluating future devices and larger clusters soon.
If you're interested in training your own LLMs on the MosaicML platform, reach out to get started!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.