Announcing Enhanced Control Flow in Databricks Workflows
Conditional execution and job-level parameters are now generally available
by Ori Zohar, Gabor Ratky and Jan van der Vegt

A key element in orchestrating multi-stage data and AI processes and pipelines is control flow management. This is why we continue to invest in Databricks Workflows' control flow capabilities which allow our customers to gain better control over complex workflows and implement advanced orchestration scenarios. A few months ago we introduced the ability to define modular orchestration in workflows which allows our customers to break down complex DAGs for better workflow management, reusability, and chaining pipelines across teams. Today we are excited to announce the next innovation in Lakehouse orchestration - the ability to implement conditional execution of tasks and to define job parameters.
Conditional execution of tasks
Conditional execution can be divided into two capabilities, the "If/else condition task type" and "Run if dependencies" which together enable users to create branching logic in their workflows, create more sophisticated dependencies between tasks in a pipeline, and therefore introduce more flexibility into their workflows.
New conditional task type
This capability includes the addition of a new task type named If/else condition. This task type allows users to create a branching condition in a control flow so a certain branch is executed if the condition is true and another branch is executed if the condition is false. Users can define a variety of conditions and use dynamic values that are set at runtime. In the following example, the scoring of a machine model is checked before proceeding to prediction:
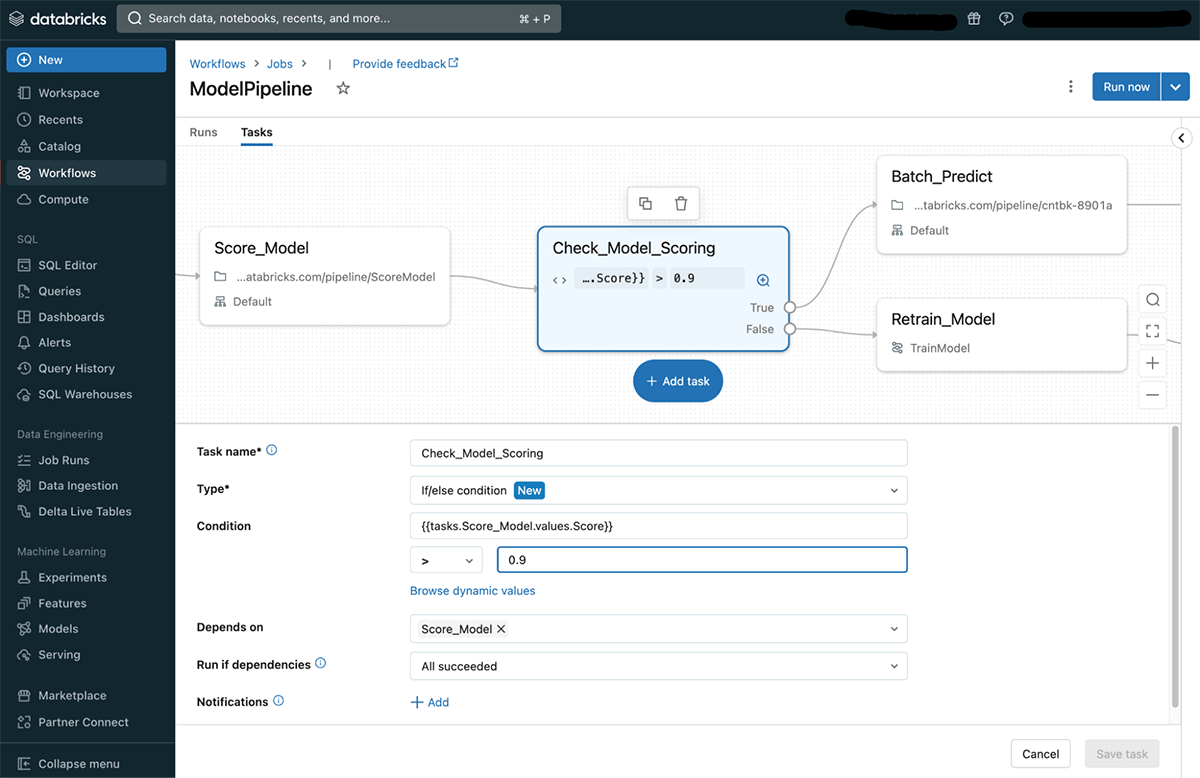
When reviewing a specific task run, users can easily see what was the condition result and which branch was executed in the run.
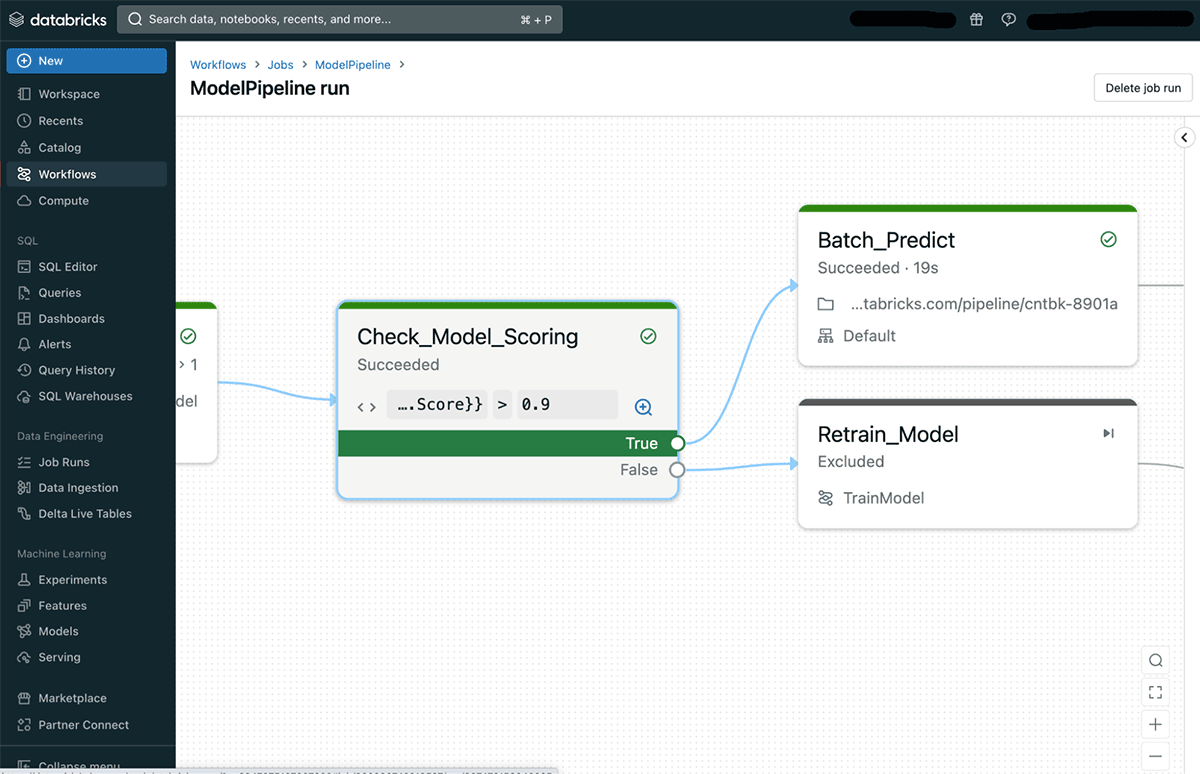
If/else conditions can be used in a variety of ways to enable more sophisticated use cases. Some examples include:
- Run additional tasks on weekends in a pipeline that is scheduled for daily runs.
- Exclude tasks if no new data was processed in an earlier step of a pipeline.
Run if dependencies
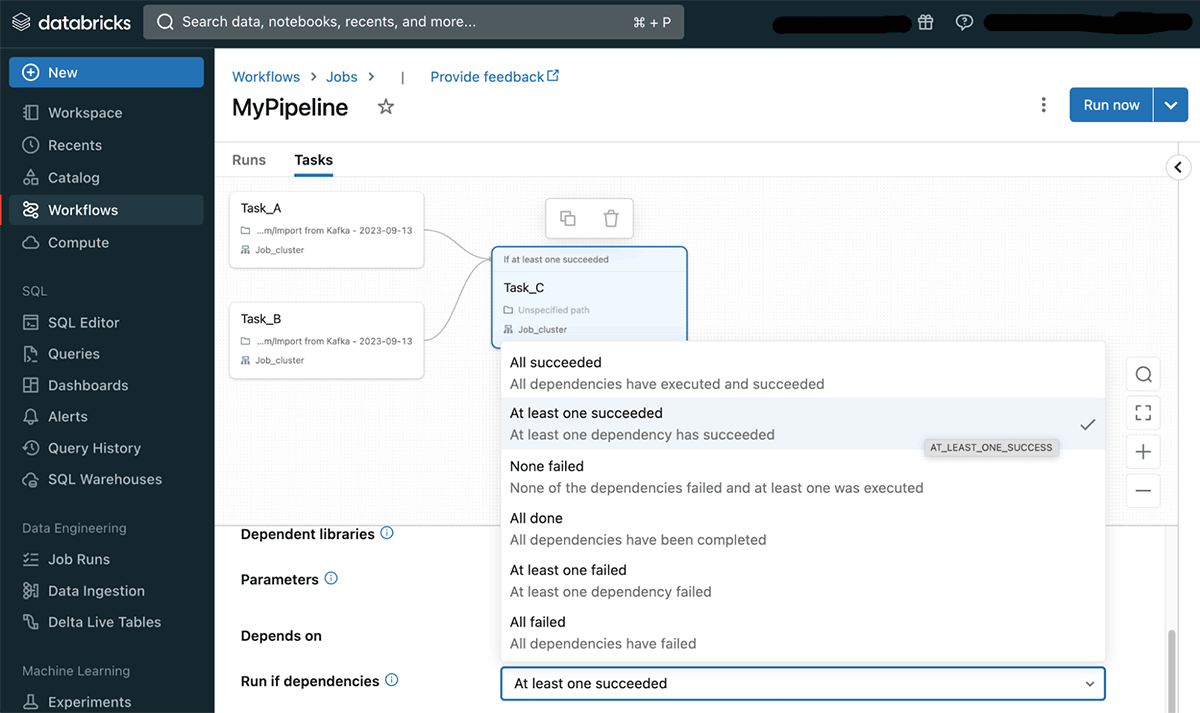
Run if dependencies are a new task-level configuration that provides users with more flexibility in defining task dependency. When a task has several dependencies over multiple tasks, users can now define what are the conditions that will determine the execution of the dependent task. These conditions are referred to as "Run if dependencies" and can define that a task will run if all dependencies succeded, at least one succeeded, all finished regardless of status etc. (see the documentation for a complete list and more details on each option).
In the Databricks Workflows UI, users can choose a dependency type in the task-level field Run if dependencies as shown below.
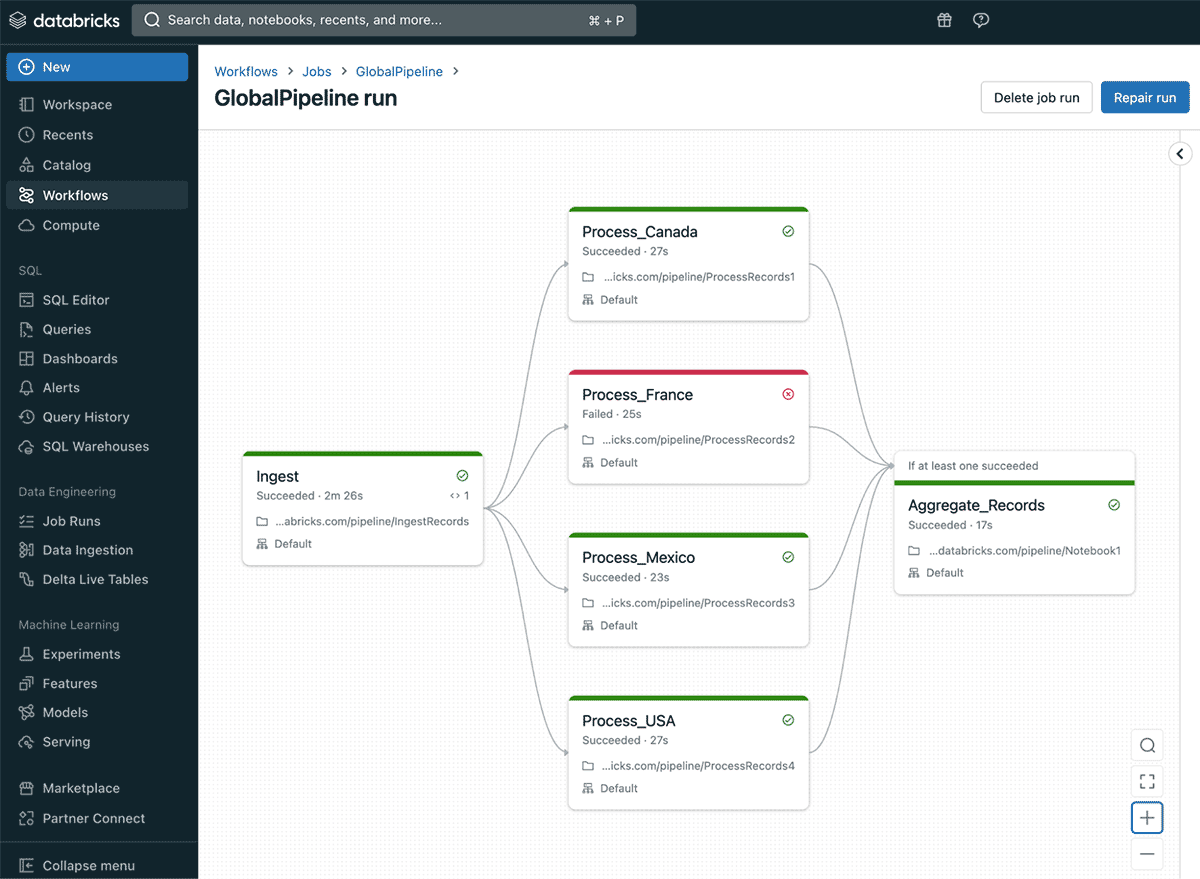
Run if dependencies are useful in implementing several use cases. For example, imagine you are implementing a pipeline that ingests global sales data by processing the data for each country in a separate task with country-specific business logic and then aggregates all the different country datasets into a single table. In this case, if a single country processing task fails, you might still want to go ahead with aggregation so an output table is created even if it only contains partial data so it is still usable for downstream consumers until the issue is addressed. Databricks Workflows offers the ability to do a repair run which will allow getting all the data as intended after fixing the issue that caused one of the countries to fail. If a repair run is initiated in this scenario, only the failed country task and the aggregation task will be rerun.
Both the "If/else condition" task types and "Run if dependencies" are now generally available for all users. To learn more about these features see this documentation.
Job parameters
Another way we are adding more flexibility and control for workflows is through the introduction of job parameters. These are key/value pairs that are available to all tasks in a job at runtime. Job parameters provide an easy way to add granular configurations to a pipeline which is useful for reusing jobs for different use cases, a different set of inputs or running the same job in different environments (e.g. development and staging environments).
Job parameters can be defined through the job settings button Edit parameters. You can define multiple parameters for a single job and leverage dynamic values that are provided by the system. You can learn more about job parameters in this documentation.
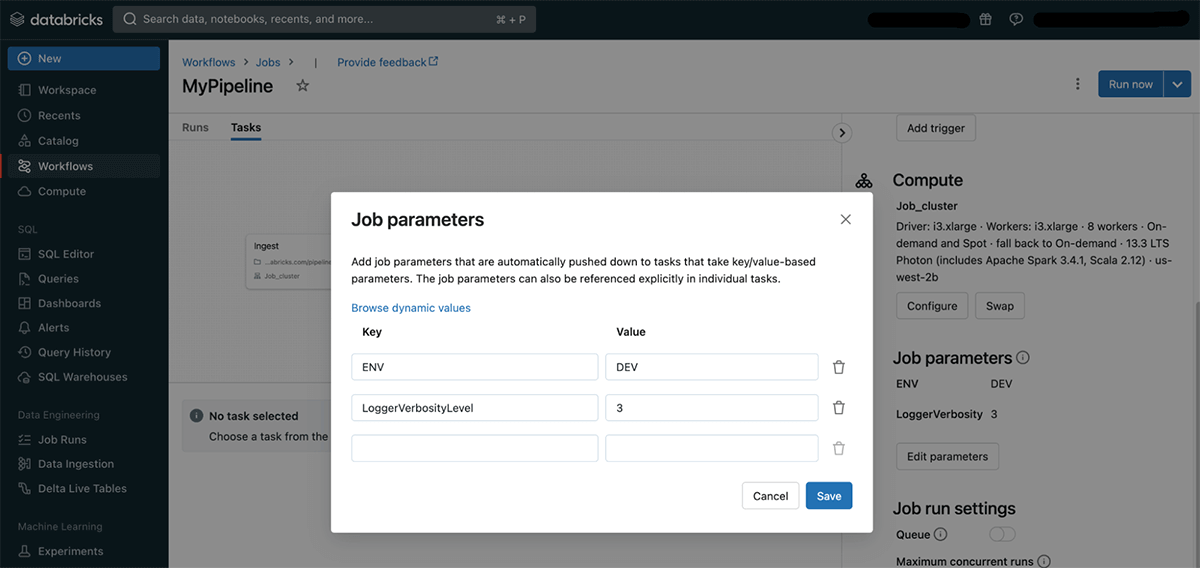
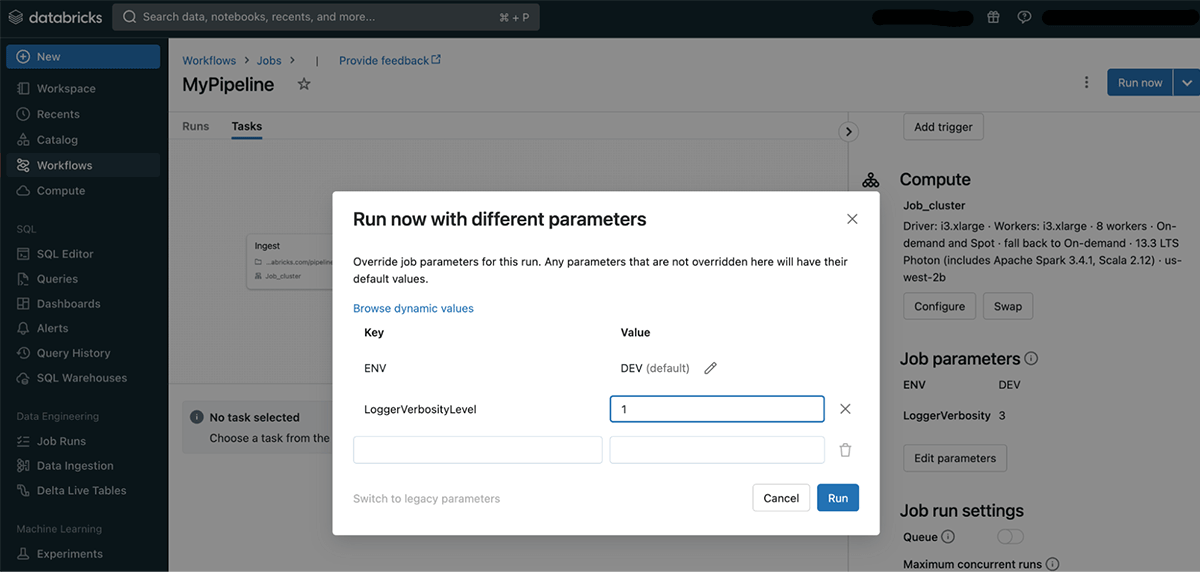
When instantiating a job run manually, you can provide different parameters by choosing "Run now with different parameters" In the "Run now" dropdown. This can be useful for fixing an issue, running the same workflow over a different table or processing a specific entity.
Job parameters can be used as input for an "If/else condition" task to control the flow of a job. This allows users to author workflows with several branches that only execute in specific runs according to user-provided values. This way a user looking to run a pipeline in a specific scenario can easily control the flow of that pipeline, possibly skipping tasks or enabling specific processing steps.
Get started
We are very excited to see how you use these new capabilities to add more control to your workflows and tackle new use cases!
- Learn more about Databricks Workflows by exploring this demo.
- Learn how to use these new features in the documentation for conditional execution and job parameters.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.