Arctic Wolf’s Liquid Clustering Architecture Tuned for Petabyte Scale
by Justin Lai, Rajneesh Arora, Krishan Kumar and Cindy Jiang
- Arctic Wolf processes 1+ trillion security events each day, generating 260+ billion enriched observations maintained in a petabyte-scale Delta Lake. Our architecture is designed to deliver near real-time access to that data.
- We recently migrated to using liquid clustering on Unity Catalog managed tables with Predictive Optimization (PO), complimenting our partitioned external tables with incremental, workload-aware clustering for better query performance.
- Together, liquid clustering and PO keep tables tuned for up to 8x faster queries and improved data freshness from hours to minutes.
Every day, Arctic Wolf processes over one trillion events, distilling billions of enriched records into security-relevant insights. This translates to more than 60 TB of compressed telemetry, powering AI-driven threat detection and response—24x7, without gaps. To power real-time threat hunting, we needed this data available to customers and Security Operation Center as quickly as possible, with the goal that most queries return in 15 seconds.
Historically, we have had to leverage other fast datastores to provide access to recent data as partitioning + z-ordering could not keep up. When we detect suspicious activity, our team can immediately pivot across three months of historical context to understand attack patterns, lateral movement, and the full scope of compromise. This real-time historical analysis against 3.8+ PB of compressed data is critical in modern threat hunting: the difference between containing a breach in hours versus days can mean millions in damage prevented.
When every second counts, speed and freshness matter. Arctic Wolf needed to accelerate access across massive datasets without driving up ingestion costs or adding complexity. The challenge? Investigations were slowed by heavy file I/O and stale data. By rethinking how data is organized, our architecture efficiently manages multi-tenant data skew, where a small fraction of customers generate most events, while also accommodating late-arriving data that can appear up to weeks after initial ingestion. Measurable benefits include cutting file counts from 4M+ to 2M, slashed query times by ~50% across percentiles, and reduced 90-day queries from 51 seconds to just 6.6 seconds. Data freshness improved from hours to minutes, enabling access to security telemetry almost immediately.
Read on to learn how liquid clustering and Unity Catalog managed tables made this possible—delivering consistent performance and near-real-time insights at scale.
Legacy Bottlenecks: Why Arctic Wolf Rebuilt
Our legacy table, partitioned by occurrence date-hour and z-ordered by tenant identifier, could not be queried in near real time due to the large number of small files split across the partitions. Moreover, the data is only available outside of the last 24 hours, as we had to run OPTIMIZE with Z-ordering before data could be queried.
Even then, performance issues persisted due to late-arriving data. This occurs when a system goes offline before transmitting data, which would result in new data landing in older partitions and impacting performance.
Stale data blinds us. That delay is the difference between containing an adversary and allowing them to move laterally.
To mitigate these performance challenges and provide the data freshness we needed to duplicate our hot data in a data accelerator and query blend it with data from our Data Lake to satisfy our business requirement. This system was costly to run and required significant engineering effort to maintain.
To address these challenges of using a data accelerator, we redesigned our data layout to distribute data evenly and support late-arriving data. This optimizes query performance and enables near real-time access for current and emerging agentic AI use cases
Building the Streaming Data Foundation with liquid clustering
With our new architecture, our key objective is to be able to query the most recent data, provide consistent query performance across different customer sizes, while queries should return in seconds.
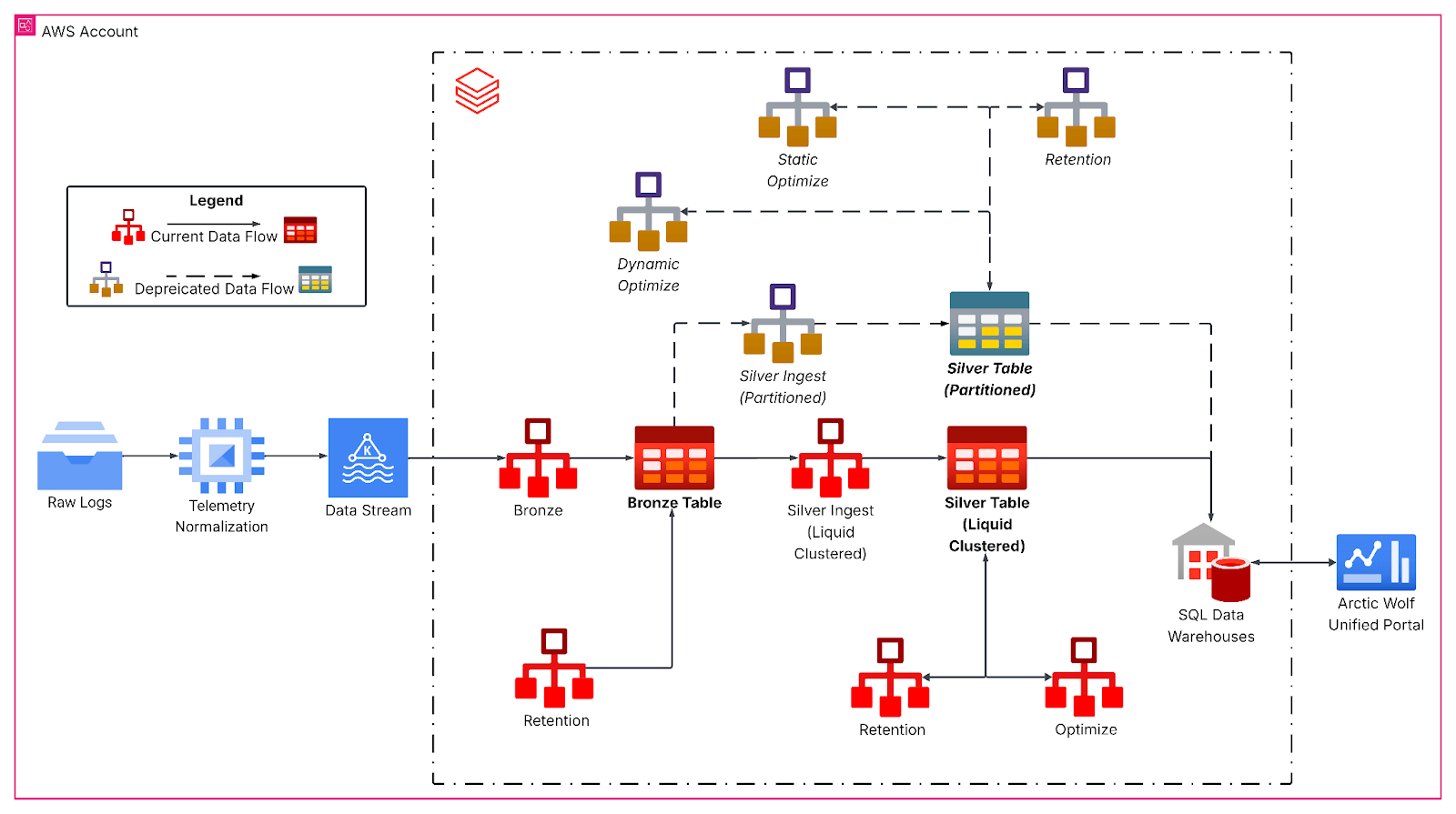
The rearchitected pipeline follows a medallion architecture, starting with continuous Kafka ingestion into a bronze layer for raw event data. Hourly structured streaming jobs then flatten nested JSON payloads and write to silver tables with liquid clustering, forming the primary analytical foundation. Here, bronze-to-silver transformations handle schema evolution, generate derived temporal columns, and prepare data for downstream analytical workloads with strict latency SLAs.
Liquid clustering replaced rigid partitioning schemes with workload-aware, multi-dimensional clustering keys aligned to query patterns , specifically by tenant identifier and date granularity, table size, and data arrival characteristics. Making the data more evenly distributed and in our instance increased average file sizes to over 1GB, dramatically reducing the number of files scanned during typical time-windowed queries for our table.
Deep Dive: Clustering on Write
Moreover, our structured streaming jobs leverage clustering on write to maintain file layout as new data arrives. It functions like a localized OPTIMIZE operation, applying clustering to only the newly ingested data. So, the data ingested is already optimized. However, if ingestion batches are too small, they produce many small but well-clustered files that still need to be clustered during a global OPTIMIZE to achieve an ideal data layout. In contrast, if the batch size at ingestion approaches the batch size needed by global Optimize, additional optimization is often unnecessary.
For workloads that ingest very large volumes of data (e.g., terabytes), we recommend batching at the source, such as using foreachBatch with maxBytesPerTrigger, to ensure efficient clustering and file layout. With maxBytesPerTrigger, we can control the batch size eliminating many tiny clustered islands that would require reconciliation via OPTIMIZE operation. With sizes close to what OPTIMIZE operation works on, we were able to create optimal batches to reduce the work further needed by OPTIMIZE.
Impact on Arctic Wolf’s Security Analytics
Arctic Wolf’s migration to Liquid Clustering delivered substantial quantifiable improvements in performance, data freshness, and operational efficiency. UC Managed Tables with Predictive Optimization also reduced the need to schedule maintenance.
File counts dropped from 4M+ to 2M, minimizing file I/O during queries while maintaining good cluster quality. As a result, query performance improved drastically, allowing security analysts to investigate incidents faster: ~50% faster across percentiles and ~90% faster a large number of our customers, with 90-day queries dropping from 51 seconds to 6.6 seconds.
By implementing clustering-on-write, we reduced data freshness from hours to minutes, accelerating time-to-insight by approximately ~90%. This improvement enables near-real-time threat detection in Arctic Wolf’s Data Lake.
Transitioning to liquid clustering and Unity Catalog managed tables eliminated legacy partitioning, reduced technical debt and unlocked advanced governance and performance features. With an architecture capable of processing and querying 260+ billion rows daily, we deliver faster, more efficient access to critical security data from all these sources. Combined with our 24/7 Concierge Security® Team and real-time threat detection, this enables quicker, more accurate threat response and mitigation. These differentiators help our customers achieve a stronger, more agile security posture and greater confidence in Arctic Wolf’s ability to protect their environments and support ongoing business success.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.