OMB M-21-31: A Cost-Effective Alternative to Meeting and Exceeding Traditional SIEMs With Databricks
by Monzy Merza
On August 29, 2021, the U.S. Office of Management and Budget (OMB) released a memo in accordance with the Biden Administration’s Executive Order (EO) 14028, Improving the Nation’s Cybersecurity. While the EO mandates that Federal Agencies adapt to today’s cybersecurity threat landscape, it doesn’t define specific implementation guidelines. However, the memo (M-21-31) describes a four-tiered maturity model for event management with detailed requirements for implementation. M-21-31 requires Federal Agencies to meet each rising level of maturity using their existing cybersecurity budget.
Early conversations with Federal Agencies have shown that their projected log collection storage requirements will increase by a factor of 4-10x. Since many Agencies use legacy Security Information and Event Management (SIEM) platforms to collect and monitor their logs, they are facing a massive increase in both the licensing and infrastructure cost for these solutions in order to meet the mandate.
Fortunately, there is an alternative architecture using the Databricks Lakehouse Platform for cybersecurity that Agencies can use to quickly, easily, and affordably meet M-21-31 requirements without forklifting operations or filtering the required raw logs. In this blog, we will discuss this architecture and how Databricks can be used to augment existing SIEM and Security Orchestration Automation and Response (SOAR) implementations. We will also provide an overview of M-21-31, the drawbacks of legacy SIEMs for fulfilling the mandate and how the Databricks approach addresses those issues while improving operational efficiency and reducing cost.
Improving investigative and remediation capabilities
Why is M-21-31 being issued now? Recent large-scale cyberattacks including SolarWinds, log4j, Colonial Pipeline, HAFNIUM and Kaseya, highlight the sophistication, complexity and increasing frequency of cyberattacks. In addition to costing the Federal government more than $4 million per incident in 2021, these cyber threats also pose a significant risk to national security. The government believes continuous monitoring of security data from an Agency's entire attack surface during, and after incidents, is required in the detection, investigation and remediation of cyber threats. Agency-level security operations centers (SOC) also require security data to be democratized to improve collaboration for more effective incident response.
Maturity model for event log management
The maturity model described in M-21-31 guides Agencies through the implementation of requirements across four event logging (EL) tiers: EL0 - EL3:
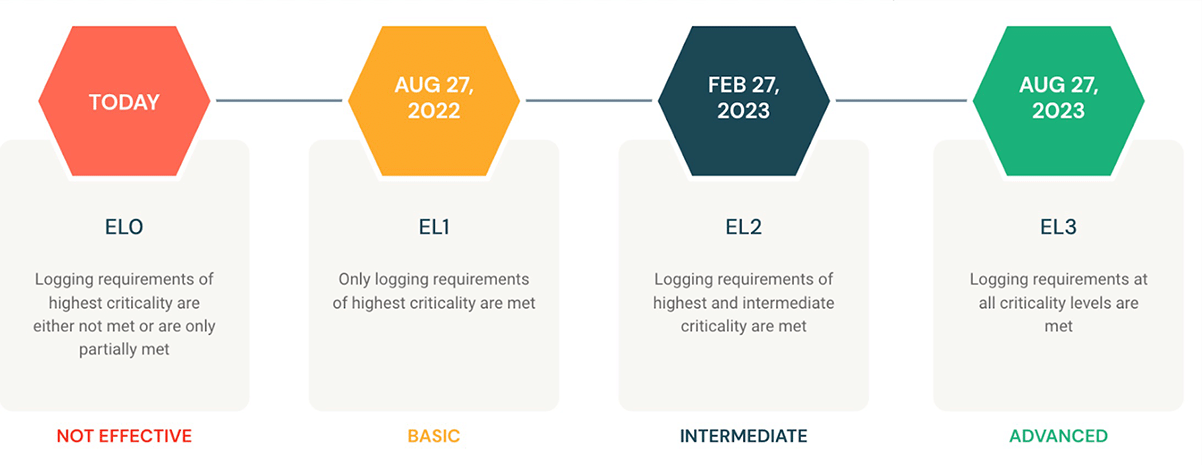
The expectation is for Agencies to immediately begin to increase performance to reach full compliance with the requirements of EL3 by August 2023. The first deadline came in October 2021 when Agencies had to assess their current maturity against the model and identify resourcing and implementation gaps. From there, Agencies are expected to achieve tiers one through three every six months. Logging requirements and technical details by log category and retention period are provided for each type of data in the memo. Almost across the board, retention period requirements are 12 months for active storage and 18 months for cold data storage.
What’s an agency to do?
How does an agency go about meeting both the M-21-31 and SOC requirements specified in the memo? Generally speaking, M-21-31 is demanding that Chief Information Security Officers (CISOs) grow log collection by what many are measuring as 4-10x current ingest levels. The number of data sources being collected is expanding along with the retention, or lookback, period. In order to fulfill the mandate, the first question you need to answer is, how many terabytes of data does your agency ingest each day? From there, you can determine the increased licensing cost of your current SIEM, increased infrastructure cost and related administration costs. As this Total Cost of Ownership (TCO) for legacy SIEMs is directly related to data ingest, the cost of expansion for an existing architecture could be significant.
Traditional SIEM vs. SIEM augmentation
M-21-31 didn’t come with much warning and is an unfunded mandate. Agencies need a solution that can be implemented with existing resources and budget. Some Agencies are finding that the TCO of expanding their existing SIEM to increase licensing, storage, compute, and integration resources would cost tens of millions of dollars per year. This cost only increases if the legacy architecture is on-premises and requires additional egress costs for new cloud data sources.
SIEM augmentation using a cloud-based data\lLakehouse takes the benefits of legacy SIEMs and scales them to support the high volume data sources required by M-21-31. Open platforms that can be integrated with the IT and security toolchains provide choice and flexibility. A FedRAMP approved cloud platform allows you to run on the cloud environment you choose with stringent security enforcement for data protection. And integration with a scalable and highly-performant analytics platform, where compute and storage are decoupled, supports end-to-end streaming and batch processing workloads. No overhauling operations, specific expertise or extreme costs. Just an augmentation of the security architecture you’re already using.
The Databricks approach: Lakehouse + SIEM
For government agencies that are ready to modernize their security data infrastructure and analyze data at petabyte-scale more cost-effectively, Databricks provides an open lakehouse platform that helps democratize access to data for downstream analytics and Artificial Intelligence (AI).
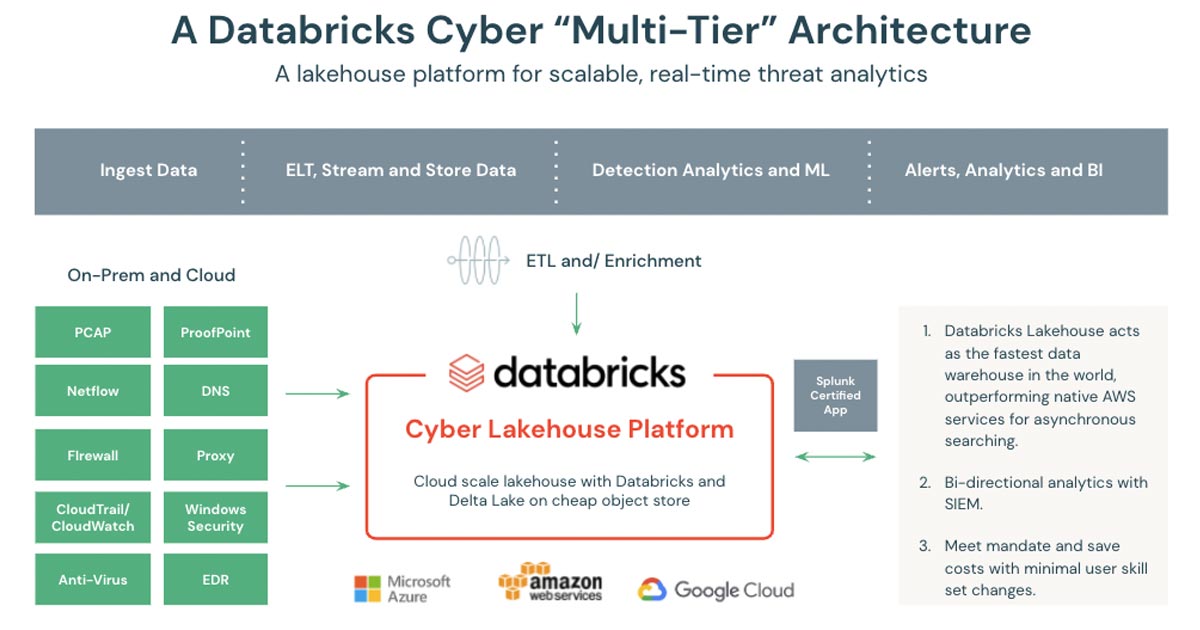
The cyber data lakehouse is an open architecture that combines the best elements of data lakes and data warehouses and simplifies onboarding security data sources. The foundation for the lakehouse is Databricks Delta Lake, which supports structured, semi-structured, and unstructured data so Federal Agencies can collect and store all of the required logs from their security infrastructure. These raw security logs can be stored for years, in an open format, in the cloud object stores of Amazon Web Services (AWS), Microsoft Azure (Azure), or Google Cloud (GCP) to significantly reduce storage costs.
Databricks can be used to normalize raw security data to conform with Federal Agency taxonomies. The data can also be further processed to simplify the creation of Agency Security Scorecards and Security Posture reports. In addition, Databricks implements table access controls, a security model that grants different levels of access to security data based on each user’s assigned roles to ensure data access is tightly governed.
The cyber lakehouse is also an ideal platform for the implementation of detections and advanced analytics. Built on Apache Spark, Databricks is optimized to process large volumes of streaming and historic data for real-time threat analysis and incident response. Security teams can query petabytes of historic data stretching months or years into the past, making it possible to profile long-term threats and conduct deep forensic reviews to uncover infrastructure vulnerabilities. Databricks enables security teams to build predictive threat intelligence with a powerful, easy-to-use platform for developing AI and ML models. Data scientists can build machine-learning models that better score alerts from SIEM tools, reducing reviewer fatigue caused by too many false positives. Data scientists can also use Databricks to build machine learning models that detect anomalous behaviors existing outside of pre-defined rules and known threat patterns. To provide an example, last year Databricks published a blog on Detecting Criminals and Nation States through DNS Analytics. This blog includes a notebook that ingests passive DNS data into Delta Lake and performs advanced analytics to detect threats and find correlations in the DNS data with threat intelligence feeds.
Additionally, Databricks created a Splunk-certified add-on to augment Splunk for Enterprise Security (ES) for cost-efficient log and retention expansion. Designed for cloud-scale security operations, the add-on provides Splunk analysts with access to all data stored in the Lakehouse. Bi-directional pipelines between Splunk and Databricks allow agency analysts to integrate directly into Splunk visualizations and security workflows. Now you can interact with data stored within the lakehouse without leaving the Splunk User Interface (UI). And Splunk analysts can include Databricks data in their searches and Compliance/SOC dashboards.
The following diagram provides an overview of the proposed solution:
Databricks + Splunk: a cost-saving case study
Databricks integrates with the SIEM/SOAR/UEBA of your choice, but because a lot of agencies use Splunk, the Splunk-certified Databricks add-on can be used to meet both OMB and SOC needs. The following example features a global media telco’s security operation, however, the same add-on can be used by government agencies.
For this use case, the telco company wanted to implement exactly what M-21-31 is requiring agencies to do: expand lookback and data ingestion for better cybersecurity. Unfortunately, with Splunk alone, the more logs retained, the more expensive it gets to maintain. The Databricks add-on solves this problem by increasing the efficiency of Splunk.
Ingesting 35TB/day with 365-day lookbacks can potentially cost 10s of millions per year in Splunk Cloud. Databricks can be leveraged for big resources like DNS, Cloud Native, PCAP — all from the comfort of Splunk — without new personnel skillsets needed and at lower costs.
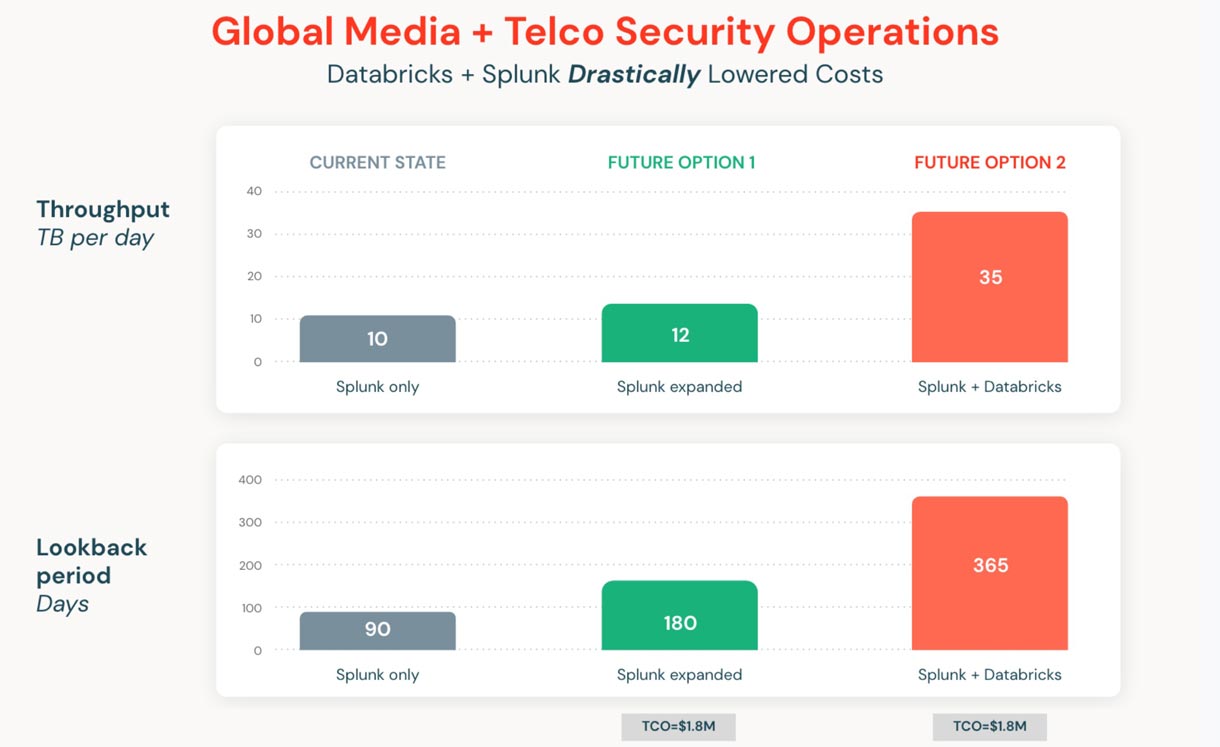
The diagram above represents the results of the Databricks add-on for Splunk versus Splunk alone and Splunk expanded. The telco organization grew throughput from 10TB per day with only 90 days look back, to 35TB per day with 365 days lookback using the Databricks SIEM augmentation. Despite the 250% increase in data throughput and more than quadrupling the lookback period, the total cost of ownership, including infrastructure and license, remained the same. Without the Databricks add-on, this expansion would have cost 10s of millions per year in the Splunk Cloud, even with significant discounts or remaining on-prem.
Because Databricks is an add-on to Splunk, your user interface doesn’t change and the user experience is seamless. With our Splunk-certified Databricks Connector app, integration, use, and adoption is quick and easy. From the comfort of the Splunk UI, agencies can keep existing processes and procedures, improve security posture, and reduce costs, while meeting the M-21-31 mandate.
Meeting the mandate while maximizing the most value for the lowest TCO
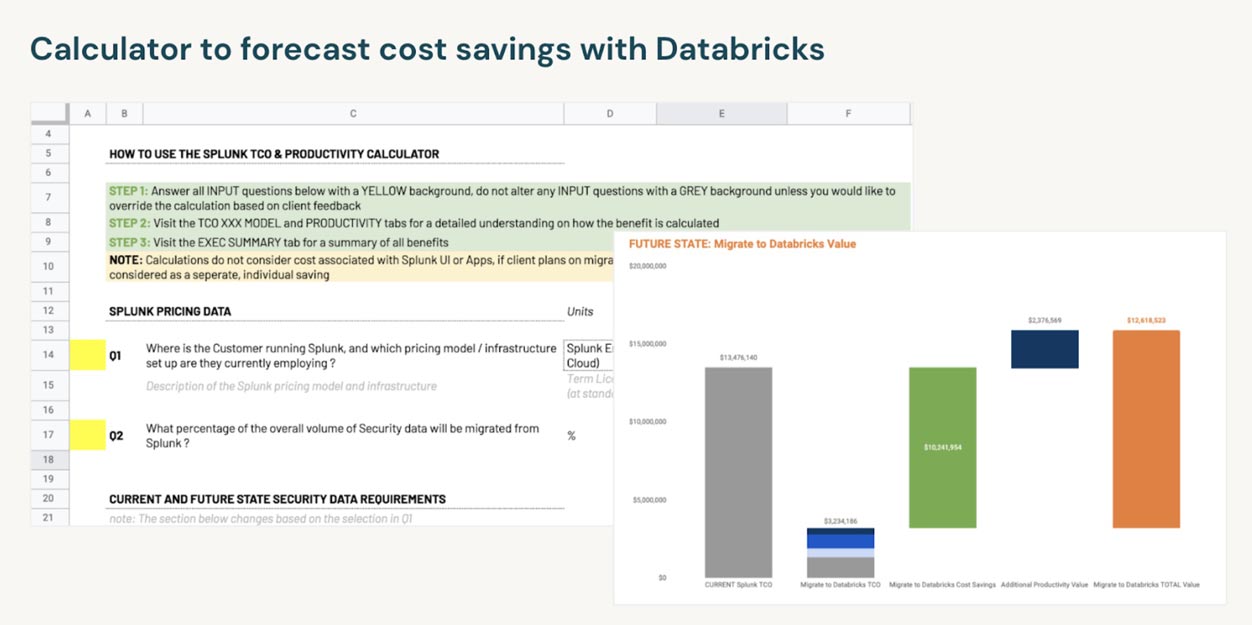
Of course, the nuances of your agency are what will determine TCO to fulfill the mandate within the time requirements. We are positive that the Databricks add-on for Splunk is the most efficient and cost-conscious solution to increasing logs and retention. That’s why Databricks created an editable ROI calculator to personalize your choices and let you weigh your options against your budget and available resources. With our expert resources guiding you through the calculator, you’ll have a clear understanding of how Databricks can help address your most pressing concerns and realize significant operational savings for OMB M-21-31.
Explore your cost-saving opportunities with Databricks as you navigate the M-21-31 mandate.
What's next
Contact us today for a demo and ROI exercise focused on helping you remain compliant with the OMB’s required timelines without going over budget or using unnecessary resources.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.