Detecting Undiagnosed Conditions and Automating Medicare Risk Adjustment
by Amir Kermany, Michael Sanky, Moritz Steller and David Talby
The Limitations of ICD-10 Coding
Structured ICD-10 diagnosis codes exist primarily for submitting claims for reimbursement. A far more comprehensive portrayal of patient health history and conditions exists in the unstructured, narrative text. Extracting conditions from clinical notes that are not otherwise found in structured data can serve a wide range of use cases across the healthcare ecosystem.
Use Cases for Extracting Undiagnosed Conditions from Unstructured Text
Medicare Risk Adjustment for Payers
In the United States, the Centers for Medicare & Medicaid Services adjusts reimbursement rates for private Medicare plan sponsors based on the assessed risk of their members. The CMS Hierarchical Condition Category (HCC) model assigns a Risk Adjustment Factor (RAF) score to each Medicare patient. This score is used to estimate future expenditures for Medicare beneficiaries.
Information found in unstructured medical records is more indicative of member risk than a narrow, temporal window of coded claims. The process of identifying these conditions from clinical documentation, and ultimately coding them, creates more accurate risk assessments and reimbursement.
Top HCCs include conditions like diabetes and congestive heart failure. If a diabetic patient has not been actively treated - and coded - for diabetes, that HCC would not be represented unless the payer takes additional action. Each HCC can contribute $2,000 or more towards member reimbursement rates from CMS; the specific calculator and rates change over time. A payer with 1M Medicare members that identifies an average of one previously undiagnosed HCC for 15% of its population is looking at a $300M adjustment (150,000 HCCs (x) $2,000 per HCC).
Provider Coding & Population Health Management
Like payers, providers have incentives to properly code patients. In a fee-for-service world, coding drives reimbursement, and in a value-based world, clinical documentation provides a more comprehensive view of patient health and risk. Clinical documentation even can form the basis of automated coding rules, enabling providers to spend more time focusing on care delivery rather than coding.
There is another important use case for providers to extract information relating to conditions from clinical documentation: The unstructured text offers a lens into the provider-patient interaction that often contains insights essential for delivering tailored interventions, such as undiagnosed anxiety and other mental health conditions. While these conditions may not be coded, they are critical to treating the whole patient.
BioPharma Assessment of Unmet Need
BioPharma organizations make billion dollar clinical investment decisions based in large part on their assessment of market opportunity and unmet need. Many times, science is ahead of codes. Drug discovery for rare disease may target conditions without an official ICD diagnosis. There are countless other examples of conditions, like cachexia, that are underdiagnosed by coded standards and yet appear in clinical documentation and weight measurements. As such, extracting undiagnosed conditions from clinical documentation has massive implications for the future of drug development.
Extracting undiagnosed conditions requires a scalable data platform and robust Natural Language Processing pipelines
The use cases described above have important implications ranging from reimbursement to the future of treatments, and they all begin with processing and analyzing unstructured text.
The path forward begins with the Databricks Lakehouse, a modern data platform that combines the best elements of a data warehouse with the low-cost, flexibility and scale of a cloud data lake. This new, simplified architecture enables healthcare and life sciences organizations to bring together all their data—structured (like diagnoses and procedure codes found in EMRs), semi-structured (like clinical notes), and unstructured (like image)— into a single, high-performance platform for both traditional analytics and data science.

Building on these capabilities, Databricks has partnered with John Snow Labs, the leader in healthcare natural language process (NLP), to provide a robust set of NLP tools tailored for healthcare text. This is critical as 80% of patient data is unstructured and much of that data is text containing insights on a patient's condition. You can learn more about our partnership with John Snow in our previous blog, Applying NLP to Health Text at Scale.
Solution Accelerator for Automating Medicare Risk Adjustment
To help organizations with use cases like Medicare Risk Adjustment, we built a solution accelerator notebook for extracting medical conditions from unstructured text using NLP. While the example use case in this accelerator is focused on patient risk adjustments, the methods can be applied to many other use cases as well.
High-level Accelerator Workflow
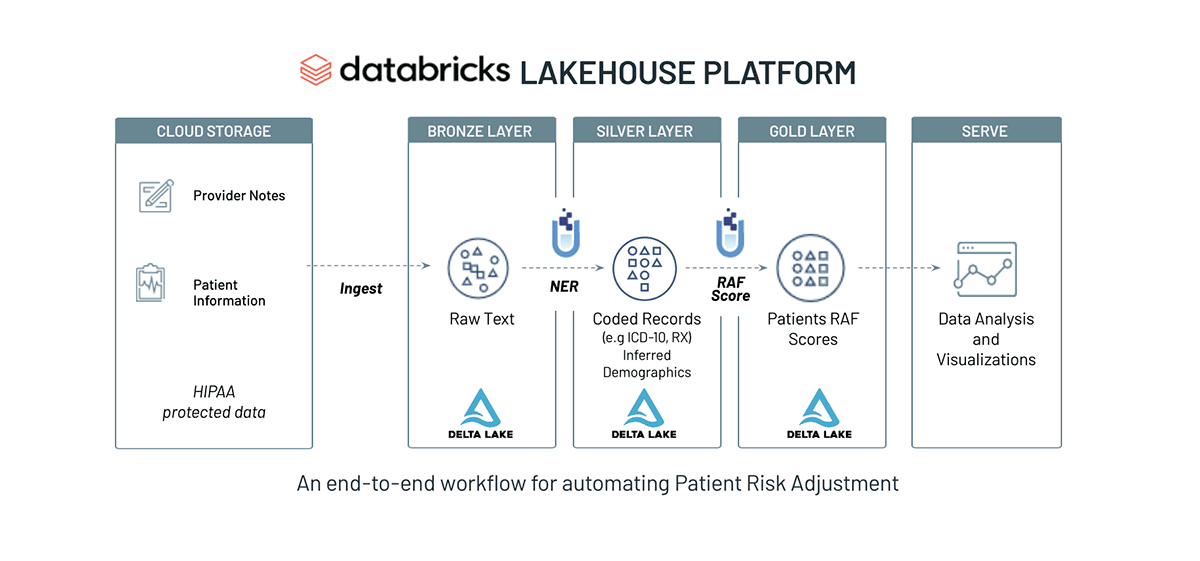
In this accelerator, you will learn how to automatically extract and codify patient conditions for the purpose of Medicare reimbursements. Included in the notebook are detailed instructions, sample code and pipelines. Here is a high-level overview of the workflow:
Step 1: Ingest unstructured medical reports into Delta Lake to prepare for downstream analysis. In this accelerator, you will use transcribed medical reports from www.mtsamples.com. Links to the data are provided within the notebook.

Step 2: Extract medical conditions from the unstructured text using healthcare NLP models from John Snow Labs. The pretrained NLP models can be used to automatically append ICD-10 and HCC codes to extracted patient conditons. Results from this step can be visualized as shown below and output into a dataframe for further analysis.

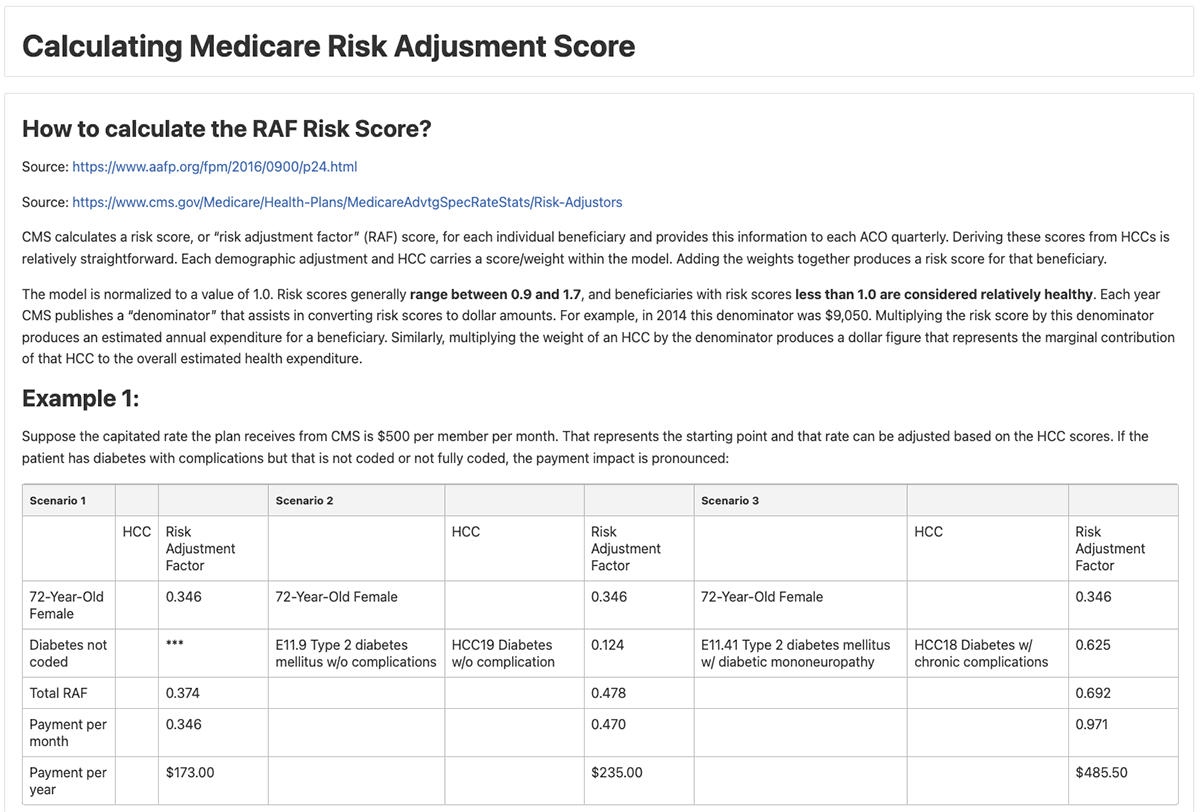
Step 3: Calculate the Risk Adjustment Factor (RAF) score using parameters provided by CMS. The RAF score is used to determine additional reimbursements. As a final step in the notebook, a patients profile can be parsed and displayed with their updated RAF score.
Get started analyzing undiagnosed conditions with NLP on Databricks
- Download our solution accelerator notebook for detecting undiagnosed conditions
- Watch our on-demand demo for this solution
- Learn more about our Lakehouse for Healthcare and Life Sciences
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.