Enterprise-Scale Governance: Migrating from Hive Metastore to Unity Catalog
Learn how to migrate large-scale, complex workloads from Hive metastore to Unity Catalog, leveraging both data governance and performance optimizations without disruption.
by Josh Bae and Dhaval Bagadia
- Organizations thrive on agility and data-driven decision-making, but legacy Hive metastores create governance gaps, siloed access and operational bottlenecks that hinder agility and compliance.
- Migrating to Unity Catalog provides unified governance, enabling enterprises to securely scale data analytics and AI workloads.
- This guide presents actionable strategies to manage complexity and minimize disruption during the transition.
Complexities of the Data Landscape
As businesses continue to scale their digital and data capabilities, the complexity of data infrastructure rises, and sustained value depends on timely, trustworthy and accessible information. However, many still rely on legacy Hive metastores (HMS), which were not designed for modern, at‑scale governance needs beyond a single workspace boundary.
HMS fundamentally lacks lineage tracking, multi-workspace governance and modern security controls. For example, users relying on a legacy Databricks per-workspace HMS face duplicated policies and fragmented visibility across workspace environments, while users using an external HMS risk improperly configured mounts that can unintentionally expose sensitive data to all workspace users. As teams grow more distributed and data usage accelerates, these limitations hinder agility and compliance, ultimately eroding trust in data-driven decision-making.
Unity Catalog (UC) addresses these challenges by introducing a unified governance model for all data and AI assets on the Databricks Data Intelligence Platform. With fine-grained access controls, centralized lineage tracking, and multi-workspace support, Unity Catalog provides the foundation organizations need to scale securely and operate more efficiently—capabilities that are simply impossible with HMS architecture.
Why this matters now
The timing for this migration guidance is critical—over the past several years, our understanding of what it takes to migrate to Unity Catalog and our tooling has evolved. This blog summarizes our latest methodology and best practices, representing field-tested techniques and real-world lessons learned from numerous Unity Catalog migrations across diverse enterprise environments. Organizations now have access to proven approaches that significantly reduce implementation risk and complexity.
This blog provides guidance to migrate from legacy Databricks per-workspace HMS (referred to as an internal HMS) and external HMS (such as AWS Glue) and includes the following topics:
- Evaluate governance models that support autonomy without sacrificing control
- Design and execute a scalable architecture that minimizes risk and disruption
- Operationalize governance to support secure, self-service access to data
- Build new workloads using Unity Catalog before migrating data assets
- Minimize disruption during migration and the cutover period
Key Architectural Considerations
Migrating from HMS to Unity Catalog presents organizations with the opportunity to modernize their data architecture; however, realizing the full value of Unity Catalog requires deliberate design choices from the outset. These architectural decisions should align with an organization’s pace of innovation, domain ownership model and cross-team data access needs.
While the overall principles remain the same, certain tools and migration approaches may work differently depending on the type of metastore. Due to these differences, it is crucial to assess tool compatibility and migration requirements within the context of your current architecture. With that understanding, we can examine metastore design—the foundation of the Unity Catalog governance model and a critical first step in shaping how catalogs, schemas and permissions will be organized for long-term scalability and compliance.
Metastore Design
As the top-level container for metadata in Unity Catalog, the metastore is the foundation of the governance model. It anchors the account’s access control framework by defining catalogs as the primary unit of data isolation and the central mechanism for scoping access across business domains. The Unity Catalog metastore is hosted as a multi-tenant service in the Databricks control plane and acts as the authoritative registry for catalogs, schemas, tables, views and permissions. Because of its central role, metastore design is a critical early step and must account for data governance requirements, workload isolation and long-term scalability.
This section focuses on metastore design principles. Technical details on provisioning a Unity Catalog metastore with Infrastructure as Code (IaC) are covered later in “Automated Deployment with Infrastructure as Code (IaC)”.
For background on Unity Catalog concepts, including metastores, managed storage and access controls, see What is Unity Catalog? (AWS | Azure | GCP)
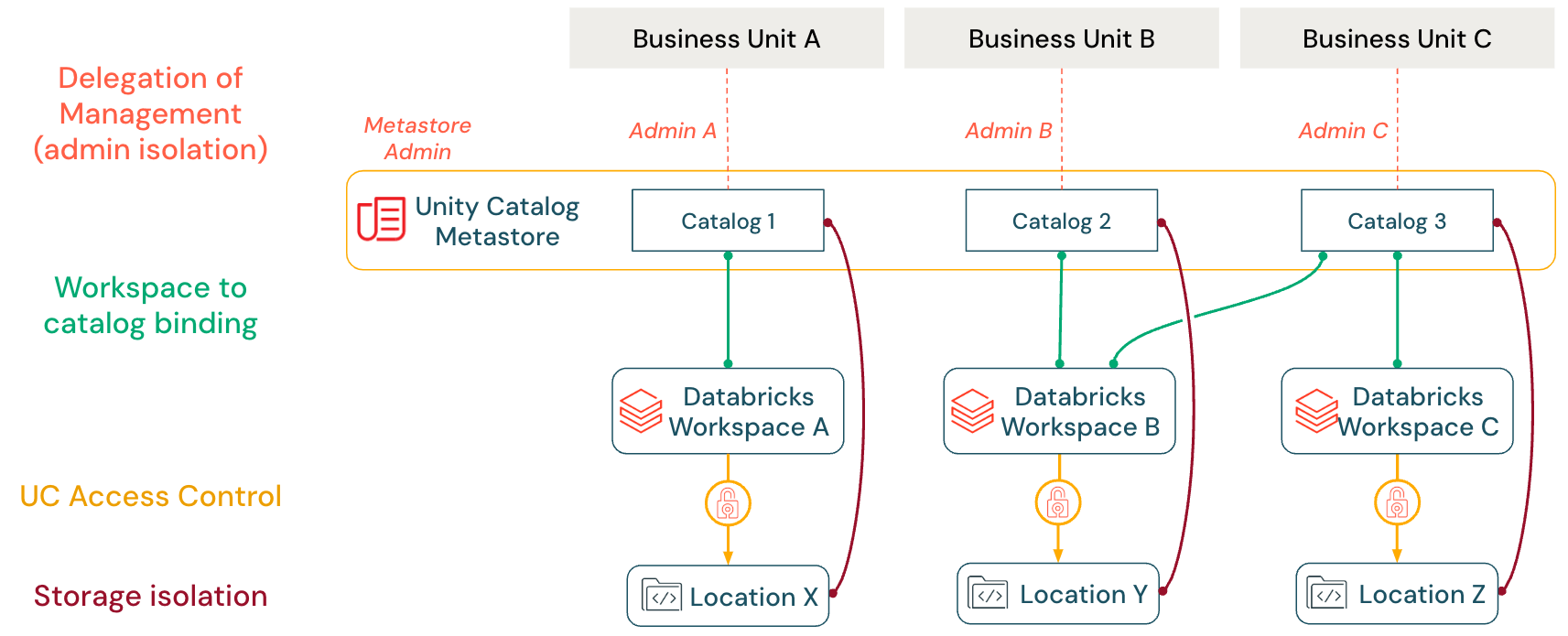
Unity Catalog supports one metastore per region but provides multiple mechanisms to enforce both logical and physical isolation across data domains. This makes a single-metastore strategy viable for most organizations—even those with complex or highly segmented environments.
In practice, most teams adopt a single metastore and enforce boundaries using catalogs and schemas, rather than provisioning multiple metastores, unless strict regional isolation is a regulatory or compliance requirement.
For guidance on sharing data across regions or cloud platforms, see Cross-region and cross-platform sharing (AWS | Azure | GCP).
Key Isolation Mechanisms
Unity Catalog provides four key isolation mechanisms that work together to enforce data boundaries and enable decentralized governance within a single metastore architecture:
| Feature | Purpose |
|---|---|
| Delegation of Management | Transfer ownership and administrative control of catalogs, schemas and tables to domain-specific teams through the Unity Catalog object ownership model |
| Workspace-Catalog Binding | Restrict catalog access to specific workspaces, ensuring environment separation between development and production workloads |
| Fine-Grained Access Control | Apply hierarchical permissions, row filters and column masks to enforce precise data security requirements at the table and column level |
| Storage Isolation | Map catalogs to dedicated cloud storage containers through managed storage locations, providing physical separation of data assets |
Delegation of Management (Admin Isolation)
The object ownership model under Unity Catalog assigns each catalog, schema, and table a single owner while allowing controlled delegation. Object owners or metastore admins can grant the MANAGE privilege to other principals (e.g., a user, service principal or account group). This allows them to rename, drop, or modify permissions on objects without granting data access privileges such as SELECT or MODIFY.
This separation of duties supports decentralized administration. Teams can manage their data assets, while metastore admins retain authority to transfer ownership, recover access and enforce governance across the environment. Assigning ownership or MANAGE to groups rather than individuals is recommended to ensure continuity and reduce administrative overhead.
For more information on the object ownership model and managing privileges for UC-governed assets, see Manage Unity Catalog object ownership (AWS | Azure | GCP).
Workspace-to-Catalog Binding
Unity Catalog allows precise limitations on which workspaces can access which catalogs using workspace-catalog binding (AWS | Azure | GCP). For example, a production-data catalog can be bound exclusively to a specific workspace, preventing users from altering the data in developer workspaces. Given this example, workspace-catalog binding does not outright prevent all access to a particular catalog from other workspaces. For example, metastore admins or catalog owners can specify read-only access to production data for users in a developer workspace, allowing them to test as needed (a single catalog can be shared across multiple workspaces). This feature ensures that workspace boundaries are maintained for data domains, regardless of user-level privileges.
Unity Catalog Access Control
Unity Catalog enables fine-grained and hierarchical role-based access control (RBAC), allowing administrators to grant precise permissions (at the metastore, catalog, schema or table level) to users, groups or service principals. Access is managed through SQL commands or the Databricks UI and CLI, making it straightforward to restrict data access and enforce robust data governance and privacy.
Access control in Unity Catalog is built on four complementary models that work together:
- Workspace-level restrictions: Limit where users can access data by binding objects to specific workspaces.
- Privileges and ownership: Define who can access what by granting privileges on securable objects and managing object ownership.
- Attribute-based access control (Beta): Govern what data users can access using tags and flexible, centralized policies that dynamically evaluate user, resource or environment attributes.
- Table-level filtering and masking: Control what data users can see within tables with row-level filters and column masks, applied directly to the data.
See Access Control in Unity Catalog (AWS | Azure | GCP) for more information.
Storage Isolation
While metastores provide regional isolation, data isolation is typically achieved at the catalog level. Databricks recommends assigning each catalog its own managed storage container (e.g., a dedicated S3 bucket, ADLS container or GCS bucket) to enforce this. Any new managed table or volume in that catalog is written into its assigned container by default. In practice, a company might give each team or environment its catalog (e.g., sales_prod, marketing_dev) with a separate cloud bucket. This approach ensures that each team’s data remains physically isolated while simplifying governance. Policies incorporating encryption and data lifecycle management can be applied at the container level to meet compliance requirements.
Additionally, Unity Catalog uses two key constructs to govern external data access:
- A storage credential encapsulates the cloud identity (such as an IAM role, Azure service principal or GCP service account) used to access object storage
- An external location ties that credential to a specific cloud path or container. Only users granted privileges on an external location can read or write data in that path.
These can also be bound to specific workspaces, ensuring only privileged users can access sensitive data paths.
For more information, see Connect to cloud object storage using Unity Catalog (AWS | Azure | GCP).
Catalog Design
With a well-planned metastore in place, attention shifts to catalog design, where governance decisions begin to meet day-to-day data usage. While the metastore establishes the global access control plane, catalogs act as the primary mechanism for logical separation and domain-based ownership of data.
Each catalog typically corresponds to a business unit (BU), functional domain or project boundary. This mapping gives teams autonomy over their data while maintaining alignment with governance standards. Thoughtful catalog design reduces access complexity and helps ensure you can scale securely as needs evolve.
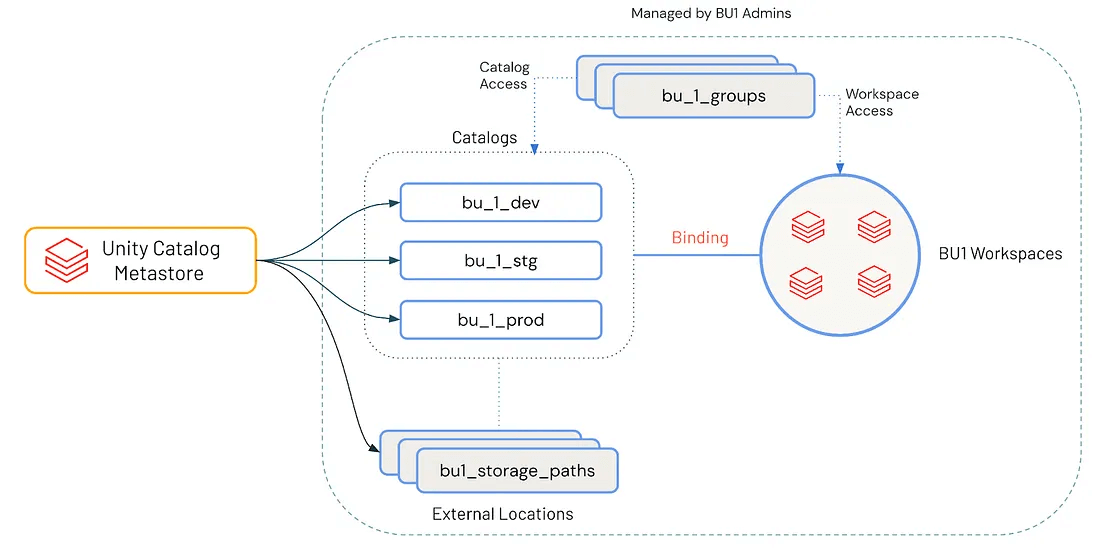
An effective cataloging strategy reflects business domain boundaries and software lifecycle stages. A widely adopted, scalable pattern is:
<business unit>_<environment> → finance_dev, sales_stg, datascience_prod
This convention enables:
- Clear Ownership: Each catalog maps to a BU or domain, managed by a dedicated team
- Environment Isolation: Data products are developed, validated, and promoted through controlled stages (dev → staging → prod)
- Policy Granularity: Access controls, encryption, and retention policies can be applied at the catalog level
With this structure, teams can manage the full lifecycle of data products while keeping environments isolated. Developers can test changes, conduct peer reviews and promote assets progressively before production release.
For organizations with strict security or compliance requirements, environment isolation often extends beyond logical boundaries. In these cases, each environment may be backed by separate storage containers, cloud networking (VPCs/VNets) or even distinct Databricks workspaces.
By aligning Unity Catalog to reflect business and environment segmentation, organizations can achieve consistency in governance, streamline approval and deployment workflows, and scale their data initiatives with confidence. This approach strikes a balance between team autonomy and safe innovation, on the one hand, and the rigor of centralized governance and traceability, on the other.
For additional guidance, refer to Unity Catalog best practices (AWS | Azure | GCP).
Governance Model: Centralized versus Distributed Ownership
While catalog design defines the structural boundaries for data domains and environments, the governance model establishes who has authority to make decisions within those boundaries. The choice between a centralized and a distributed (or federated) governance model shapes how policies are enforced, how teams can adapt to change and how data initiatives scale across the organization.
Put simply, catalogs define where data ownership resides, while the governance model defines how and who governs that ownership.
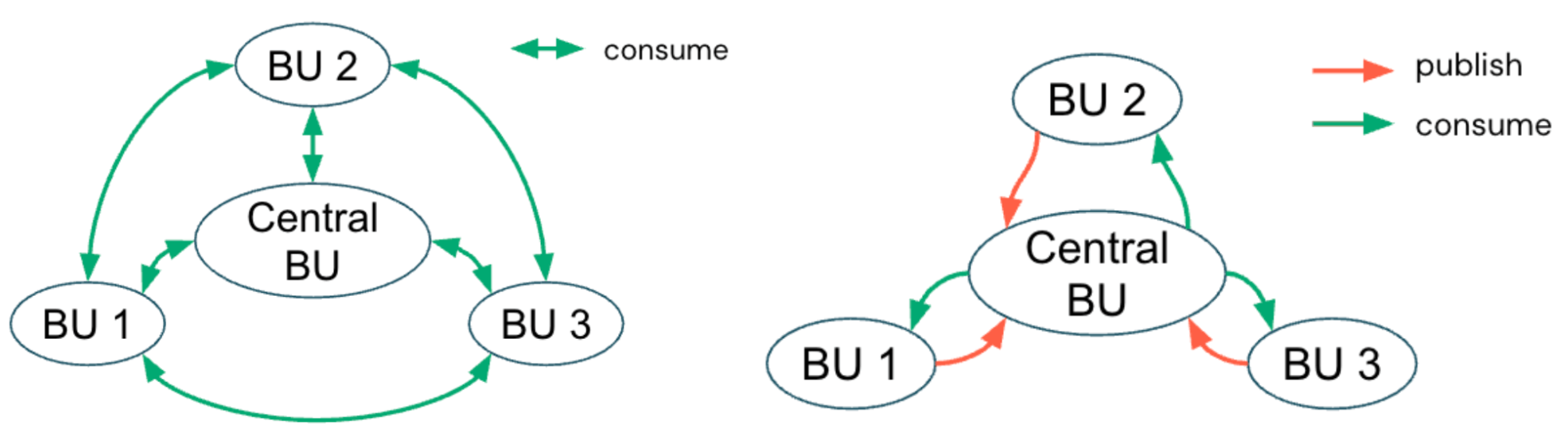
Centralized Model
In a centralized governance model, a dedicated platform or data governance team manages the Unity Catalog metastore and enforces access boundaries through catalogs. The team defines catalogs as BU- or domain-aligned containers and configures workspace-to-catalog bindings to separate development and production use. They also apply fine-grained permissions at the catalog, schema and table levels.
This central team also curates shared datasets and maintains compliance, quality and metadata standards across all domains, ensuring consistent policies organization-wide. This model streamlines compliance and auditing, particularly for organizations in regulated industries or those with tightly controlled data environments.
For example, some global manufacturing organizations that adopt a centralized governance model can streamline communication across regions, apply consistent quality standards and optimize operational costs throughout their supply chains.
Distributed Model
Conversely, a distributed (or federated) governance model decentralizes control by empowering individual BUs to own their catalogs and data products end-to-end. While a central platform team may govern infrastructure, security guardrails and compliant architecture, each domain team independently manages its catalog permissions, data quality and publishing workflows. This model promotes domain accountability and agility, aligning with Data Mesh principles, where data is treated as a product and collaboration occurs across autonomous teams within a common governance framework.
A distributed approach scales well as data estates grow, since ownership is distributed. Each team is directly responsible for the quality, lineage and documentation of its data, which fosters stronger accountability and accelerates the delivery of trusted data products to the wider organization.
This particular model is often well-suited for organizations with a diverse business portfolio requiring localized compliance or operations spanning multiple regions with differing regulatory requirements.
Which one should I pick?
Most organizations find it practical to start with a centralized governance model using Unity Catalog, as it provides consistent policies, simplified compliance and unified oversight across all data assets. A distributed governance model should be considered for organizations with specific constraints that make centralization impractical—such as organizations with highly autonomous BUs, specialized data workloads or regulatory requirements that vary across regions may find centralization too rigid.
Ultimately, the choice depends on factors like organizational structure, regulatory requirements, data maturity and collaboration needs. Below is a quick summary of the strengths and trade-offs of each approach to help guide your decision:
| Aspect | Centralized Governance | Distributed Governance |
|---|---|---|
| Control and Compliance | Strong centralized control simplifies auditing and regulatory compliance. | Requires clear guardrails but offers flexibility; central team manages guardrails, not data access. |
| Speed and Agility | Slower due to approval bottlenecks and centralized workflows. | Faster innovation as BUs own data lifecycle and access management. |
| Ownership and Accountability | Central team is responsible for data quality and metadata consistency. | Domain teams own data quality, documentation and publishing, promoting accountability. |
| Complexity and Scale | Easier to manage initially, but can become bottlenecked at scale. | Scales well with growing data estates but requires mature policies and monitoring. |
| Collaboration | Collaboration is controlled via workspace-catalog bindings managed centrally. | Collaboration enabled by shared policies; teams operate with autonomy within catalog boundaries. |
| Ideal For | Organizations that have a core group to make authoritative governance decisions. | Organizations with autonomous domain teams that adhere to their own processes. |
Regardless of the approach, effective governance requires clear mapping of ownership to catalogs, robust access controls and mechanisms for transparent collaboration. This ensures that security and innovation can thrive as your Unity Catalog environment scales.
Technical Solution Breakdown
With the conceptual foundation of governance and architecture established, the focus shifts to the practical engineering efforts involved in migrating your actual data assets to UC. While the high-level steps (see Overview of upgrade steps [AWS | Azure | GCP]) outline what needs to be done, the technical execution often involves navigating complex dependencies, minimizing downtime and accommodating existing workflows. Real-world migrations rarely follow a one-size-fits-all path, and as a result, teams must tailor their approach based on their current data estate, operational constraints and business priorities.
To help address these complexities, the following sections dive into three critical technical considerations for modern data organizations: pre-migration data discovery to understand current assets and dependencies, automated deployment using Infrastructure as Code (IaC) and phased migration strategies to enable incremental adoption.
1. Pre-migration Data Discovery
Before migrating Hive tables and updating workloads, teams must understand their existing data environments. This discovery phase defines the migration scope, identifies risk areas and helps prevent regressions or service disruptions.
This involves mapping active tables, views, jobs, permissions and teams in HMS to determine what needs conversion to Unity Catalog. For large organizations with multiple workspaces and vast data volumes, manually tracking data ownership, access controls and job dependencies quickly becomes unsustainable.
Data Discovery with UCX
To address this concern, Databricks Labs developed UCX (AWS | Azure | GCP), an open source tool that automates data discovery, readiness assessment and migration planning. Once deployed, UCX scans legacy HMS workspaces, inventories relevant assets and generates a detailed report to guide migration efforts. The assessment report by UCX provides a “readiness” metric based on the total number of assets scanned and categorizes findings to help prioritize remediation.
When reviewing UCX output, organizations should look beyond raw counts and readiness scores to make informed decisions, such as:
- Reducing migration scope by identifying and excluding stale or redundant tables
- Checking activity signals like last access time or last update time to separate critical workloads from unused data
- Rationalizing assets to consolidate overlapping schemas or standardize naming before migration
- Prioritizing dependencies where downstream pipelines, BI dashboards or regulatory requirements dictate what must move first
Through this automated discovery process, organizations gain value by:
- Understanding the complete scope of BUs, teams and their data products
- Mapping access controls and dependencies between users, groups and assets
- Identifying actively used tables and views versus candidates for archiving
- Prioritizing critical legacy workflows while phasing out others
For organizations managing just a few or even hundreds of Databricks workspaces, UCX reduces engineering effort by automating discovery and clarifying migration scope. It minimizes human error and identifies compatibility gaps and hidden dependencies, ensuring workloads meet governance standards prior to migration.
For an introduction to UCX, see Use the UCX utilities to upgrade your workspace to Unity Catalog (AWS | Azure | GCP).
2. Automated Deployment with Infrastructure as Code (IaC)
Once data discovery has provided a comprehensive picture of existing assets, dependencies and access patterns, the next challenge is to provision a Unity Catalog environment that supports them. While this environment deployment can be done manually through the account console (with the proper admin privileges), leveraging the Databricks Terraform provider is strongly recommended to avoid manual configuration errors or inconsistencies.
{kind=link}
Using Terraform, teams can automate the creation and configuration of Unity Catalog resources across any supported cloud platform, making the migration process reproducible and auditable. For example, while a Databricks account admin can manually create a Unity Catalog metastore (AWS | Azure | GCP) through the account console, that person could also use Terraform by programmatically provisioning the databricks_metastore resource. Similarly, they could use it to define catalogs and schemas within the metastore, apply managed storage configurations and set access privileges. Using this more robust approach of IaC, the entire Unity Catalog setup can be fully automated with some scripting (e.g., Terraform + REST APIs) and templatized to be replicated across all BUs within the organization, enabling zero manual provisioning.
For the complete guide to create your custom Terraform module for deployment, see Automate Unity Catalog setup using Terraform (AWS | Azure | GCP).
In Unity Catalog migrations, this approach has proven especially powerful in building the necessary infrastructure so that teams can:
- Ensure governance standards are applied consistently across environments
- Minimize the risk of misconfiguration during migration
- Enable continuous delivery of governance infrastructure for future expansion
3. Migration Strategies
With a complete inventory of HMS assets and Unity Catalog-enabled workspaces provisioned via IaC, the focus shifts from setup to controlled, low-risk workload migration. Organizations can choose a strategy aligned with their complexity, structure and risk tolerance, ranging from simple pilot projects to enterprise-wide transformations.
While most organizations benefit from starting with an incremental adoption approach, scaling beyond initial pilots requires careful planning and structured execution. Organizations planning and executing a comprehensive Unity Catalog migration can engage with their Databricks account team and/or Delivery Solutions Architect (DSA) for migration assistance and access to specialized migration methodologies.
Incremental Adoption with a Pilot Approach
For most production environments, a “big-bang” migration is rarely practical. Instead, Databricks recommends starting with a pilot migration: a representative BU or team whose workloads mirror common organizational patterns, have clear data boundaries and include engaged stakeholders. This pilot phase validates tools, processes and governance controls in a controlled setting, helping teams uncover edge cases, refine rollout sequencing and improve effort estimates. Insights gained reduce uncertainty and risk for subsequent migrations.
From there, organizations can scale to full adoption in phases, maintaining platform stability, building stakeholder confidence and enabling predictable progress—advantages that are difficult to achieve with a wholesale lift-and-shift.
Databricks recommends two different incremental approaches for moving workloads from HMS to Unity Catalog.
Option A: Pipeline-by-Pipeline Migration
This approach involves migrating one pipeline at a time, encompassing its associated tables, jobs, dashboards and dependencies, to Unity Catalog before proceeding to the next pipeline. By encapsulating the entire data lineage and consumer-producer path of a single pipeline, this method localizes risk and leverages lessons learned for subsequent migrations. Teams benefit from the opportunity to test, validate and tune each Unity Catalog cutover in isolation, resulting in continuous improvement and reduced disruption across the platform.
Option B: Layer-by-Layer Migration (Gold → Silver → Bronze)
The layer-by-layer strategy, rooted in the medallion architecture, recommends progressing Unity Catalog migration through distinct layers—Gold (user-facing analytical outputs), Silver (cleansed and deduplicated datasets) and Bronze (raw ingested data). Contrary to the bottom-up tradition in some data engineering practices, Databricks often recommends starting with the Gold layer, which includes dashboards, BI assets and high-visibility tables. This reduces business impact and avoids downstream interruptions from lower-layer changes while maintaining continuity for analytics consumers.
Migration Sequence for Option B:
- Gold layer first: Migrate gold tables to Unity Catalog first, then realign critical dashboards, BI tools and ad hoc queries to point to their replacements in Unity Catalog. These assets are frequently the most visible and, when migrated first, minimize risk to business operations.
- Silver layer next: With gold consumers validated in Unity Catalog, update transformation jobs and tables that supply them—typically the silver layer. This step encompasses broader data cleansing and conformance processes.
- Bronze layer last: Complete the cycle by migrating external ingestion jobs and raw landing tables to Unity Catalog. Once upstream ingestion is unified, the lineage for the entire data stack is brought under the governance of Unity Catalog.
Databricks advises augmenting the above migration strategies with disciplined operational practices. For example, annotate legacy HMS tables referencing their Unity Catalog counterparts to help users transition smoothly and avoid confusion. Before decommissioning any legacy tables or jobs, rigorously test all downstream dependencies in Unity Catalog to ensure uninterrupted workflows. In addition, consistent communication should be maintained, and coordination must be managed with stakeholders when updating workspace access controls or reassigning roles for assets now governed by Unity Catalog.
The next section compares two common migration paths (soft versus hard) that complement the incremental approach.
Migration Paths: “Soft” versus “Hard”
Within our defined framework, there are two distinct migration patterns: soft migration through HMS federation, which enables access to the advanced governance features from Unity Catalog on federated assets while keeping HMS intact (avoiding legacy workload disruption) and hard migration, which involves the complete metadata and data transfer from HMS to Unity Catalog but requires more extensive planning and coordination across teams and systems.
Soft Migration via HMS Federation
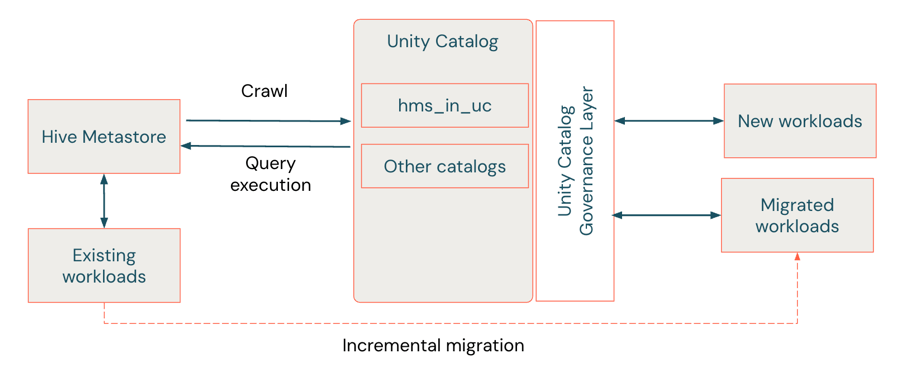
The soft migration is considered a hybrid approach that acts as a “migration bridge,” allowing teams to adopt Unity Catalog governance features while keeping the legacy HMS intact. Hive metastore federation (AWS | Azure | GCP) enables incremental migration with minimal disruption—no immediate data movement or code changes are required. Unity Catalog creates a foreign catalog that mirrors the HMS metadata, allowing workloads to run across both systems. In this way, foreign tables in this federated HMS provide a form of backwards compatibility, letting workloads continue to use Hive-only semantics—the legacy two-level namespace (schema.table). This allows them to benefit from the governance, auditing and access controls of Unity Catalog while maintaining compatibility with the three-level namespace (catalog.schema.table).
How you manage and interact with federated data in Unity Catalog depends on whether your HMS is internal or external. Federation connectors support read and write access for tables in internal HMS instances within Databricks workspaces, while external HMS and AWS Glue tables are read-only. In all cases, you can mount entire HMS catalogs (internal or external) or AWS Glue as foreign catalogs in Unity Catalog, where they appear as native objects. Table metadata is automatically synchronized with HMS as changes occur. For internal HMS, any new tables or updates made in the foreign catalog are written back to HMS, maintaining seamless interoperability between the two environments.
While soft migration via HMS federation offers a low-disruption path to adopt Unity Catalog, organizations aiming to fully retire HMS must eventually perform a hard migration of federated assets. Although it is possible to automate the hard migration of federated assets, code that reads and/or writes to these assets will need to be pointed to the new Unity Catalog asset.
Additionally, UCX offers CLI tools to enable HMS federation (as an alternative to the table migration process):
For instructions on setting up HMS federation for a legacy workspace HMS, an external HMS or an AWS Glue metastore, see How do you use Hive metastore federation during migration to Unity Catalog? (AWS | Azure | GCP).
Hard Migration
A hard migration is a comprehensive upgrade from HMS to Unity Catalog, converting metadata (and data for managed tables) for tables into the new metastore. This approach combines tools like SYNC (or Upgrade Wizard) for external tables and CREATE TABLE CLONE (CTAS) for managed tables. Each method has its own set of requirements and limitations.
For organizations with large amounts of data in HMS that need to be migrated, Databricks recommends the automated table migration workflows from UCX (over the manual methods listed below) for most table migration scenarios. See Migrate Hive metastore data objects to determine which UCX workflow to run and obtain additional context for migrating tables.
Upgrade External Tables
External tables can be upgraded with the SYNC command or the Upgrade Wizard. These perform metadata-only operations—no data is copied or moved.
- SYNC: A SQL command that transfers table metadata from HMS to Unity Catalog and adds bookkeeping properties back to the HMS table. It can be applied at the table or schema level, giving SQL-first teams granular control over what and when to migrate.
- Upgrade Wizard: A Catalog Explorer interface that wraps SYNC functionality in a visual workflow. It is ideal for bulk schema migrations, where point-and-click simplicity accelerates adoption.
Because HMS and Unity Catalog tables reference the same cloud storage, hybrid setups can run during transition. Scheduled SYNCs keep metadata aligned across both systems until the migration is complete.
Upgrade Managed Tables
Managed tables require data movement because they reside in a managed storage location (see What is a managed storage location? [AWS | Azure | GCP]). As a result, they must be upgraded with CREATE TABLE CLONE or CREATE TABLE AS SELECT (CTAS).
- CREATE TABLE CLONE (Deep Clone): This method copies data and metadata directly to the storage layer. It automatically preserves partitioning, format, invariants, nullability and other metadata. It also runs faster than CTAS because it avoids a compute-intensive read/write cycle.
- CREATE TABLE AS SELECT (CTAS): Useful when the managed Hive tables do not meet cloning requirements (e.g., Delta format). CTAS rebuilds tables from query results, enabling selective migration or transformations during the process.
CLONE is highly recommended for managed table migrations, while CTAS offers flexibility when source tables require adjustments.
Upgrade Views
Views must be recreated manually once all referenced tables are migrated. Use CREATE VIEW statements that reference the Unity Catalog versions of the tables, following the three-level namespace (catalog.schema.table).
For more details on the various options for migrating tables and views, see Upgrade Hive tables and views to Unity Catalog (AWS | Azure | GCP).
Disabling Access to HMS
After all HMS assets have been migrated to Unity Catalog or the HMS has been federated as a federated catalog under Unity Catalog, it is essential to disable direct access to the legacy HMS to ensure organization-wide adoption of centralized data governance. This step ensures that future queries, workloads and data discovery are subject exclusively to Unity Catalog access controls, eliminating the need for parallel governance frameworks and preventing unauthorized use.
Databricks recommends disabling direct HMS access for all clusters and workloads at once to enforce uniform governance and shut down potential bypass routes. For organizations preferring a staged rollout, enforcement can also be applied on an individual compute cluster basis by setting a Spark configuration, allowing for incremental rollout as needed (see Disable access to the Hive metastore used by your Databricks workspace [AWS | Azure | GCP]).
To understand the ramifications of disabling the legacy metastore, refer to What happens when you disable the legacy metastore? (AWS | Azure | GCP).
Real-World Example
A global retailer using Databricks operating at a massive scale—managing thousands of tables and notebooks—faced significant challenges in data governance and cross-functional collaboration. Data was siloed across multiple legacy storage environments, complicating permissions management, obscuring access visibility and making enterprise-wide analytics difficult to execute. BUs often lacked trust in the data, and limited asset visibility made initial migration scoping especially daunting.
Guided by the foundational principles outlined in this blog, the organization began by defining its target architecture: a federated Data Mesh designed to balance centralized governance with domain-level autonomy (“Governance Model: Centralized versus Distributed Ownership”). Leveraging the Databricks Labs UCX migration toolkit, they conducted a comprehensive asset inventory, identifying inactive workloads or not running on Unity Catalog-compatible compute (“1. Pre-migration Data Discovery”). This insight allowed them to prioritize high-value business use cases, adopt a pilot-and-scale migration approach and sequence workflows based on downstream dependencies and impact (“3. Migration Strategies”). The migration was executed in phases, employing SYNC for external tables and DEEP CLONE for managed tables. In the absence of HMS federation, not available at the time, they implemented a two-way synchronization strategy to enable incremental migration with minimal operational disruption (“Soft Migration via HMS Federation”).
Following migration, the organization established centralized governance through Unity Catalog while maintaining a federated architecture that empowered business domains to manage their own data and analytics. Built-in auditing and data lineage capabilities enhanced transparency and trust, while decommissioning legacy code and patterns reduced technical debt and streamlined operations. By abstracting away physical storage and simplifying access, the organization fostered a culture where business teams could discover, access and analyze trusted data, advancing their transformation towards a more data and AI-driven business.
Key Takeaways
- Scalable Governance Is Essential: As data-driven organizations grow, legacy metastores like HMS struggle to support modern governance needs. Unity Catalog delivers unified governance with fine-grained access controls, lineage tracking and multi-workspace support, which are critical for maintaining trust and compliance across complex analytics and AI environments.
- Modular Governance Architecture: Unity Catalog supports centralized and distributed (federated) governance. Centralized models simplify compliance and auditing for regulated industries, while distributed models grant BUs ownership over their data, accelerating innovation without sacrificing guardrails.
- Metastore and Catalog Design Matter: Thoughtful metastore and catalog design form the foundation for scalable governance. A single metastore strategy with catalog-based isolation (paired with consistent naming conventions and storage boundaries) simplifies permissions, promotes autonomy and enables secure collaboration.
- Automated, Risk-Aware Migration: Combining pre-migration discovery with Infrastructure as Code (IaC) ensures consistent Unity Catalog setup, reduces manual errors and accelerates deployment. Incremental adoption, starting with a representative pilot, minimizes disruption while building confidence and stakeholder buy-in.
- Flexible Migration Paths: Soft migration via HMS federation enables the phased adoption of Unity Catalog governance without immediate code changes, while hard migration delivers full Unity Catalog benefits and facilitates the complete retirement of HMS. Selecting the right path depends on operational risk tolerance, dependencies and modernization goals.
Conclusion
Migrating from Hive Metastore to Unity Catalog is a necessary foundational step for businesses seeking unified, scalable governance and optimized data operations to unlock true data intelligence. Success depends on aligning governance models with organizational priorities—whether centralized control for compliance or distributed ownership for team-level agility. By combining automated deployment, thorough pre-migration discovery and phased adoption, organizations can minimize disruption while ensuring continuity of mission-critical workloads. The flexible, modular architecture of Unity Catalog enables secure collaboration, self-service analytics and comprehensive compliance, establishing a foundation for sustained digital transformation and data-driven competitive advantage.
Next Steps & Resources
To begin a Unity Catalog migration effectively, apply the strategies outlined above and consult official Databricks documentation for detailed, up-to-date guidance.
Unity Catalog Migration Tracker
This tracker offers a structured template for managing your Unity Catalog migration, with built-in links to documentation and tooling and status fields to track milestones as they are completed.
Migration Tracker: Github
Getting Started with Unity Catalog
To build foundational expertise on Unity Catalog, leverage the following interactive, self-paced Databricks Academy courses (requires login with your Databricks Account or email):
- Introduction to Unity Catalog
- Data Administration in Databricks
- Data Access Control in Unity Catalog
- Compute Resources & Unity Catalog
- Unity Catalog Patterns & Best Practices
Learning from Real-World Scenarios
Gain practical insight from customer success stories and in-depth technical sessions featured at the 2025 Data + AI Summit:
- Databricks-led:
- Unity Catalog Deep Dive: Practitioner's Guide to Best Practices and Patterns - Data + AI Summit 2025 | Databricks
- Unity Catalog Upgrades Made Easy. Step-by-Step Guide for Databricks Labs UCX - Data + AI Summit 2025
- Demystifying Upgrading to Unity Catalog — Challenges, Design and Execution - Data + AI Summit 2025 | Databricks (with Celebal Technologies)
- Customer Stories:
- Schiphol Group’s Transformation to Unity Catalog - Data + AI Summit 2025 | Databricks (Schiphol Group and Databricks)
- Story of a Unity Catalog (UC) Migration: Using UCX at 7-Eleven to Reorient a Complex UC Migration - Data + AI Summit 2025 | Databricks (7-Eleven and Databricks)
- Unlocking Enterprise Potential: Key Insights from P&G's Deployment of Unity Catalog at Scale - Data + AI Summit 2025 | Databricks (P&G)
DSA: Expert Migration Guidance
Databricks Delivery Solutions Architects (DSAs) play a pivotal role in guiding organizations through Unity Catalog migrations. Acting as strategic advisors, DSAs support the design of execution plans unique to the organization, align migration efforts with business goals, and help identify potential risks before they impact delivery. By collaborating closely with data engineering teams, platform owners, and executive stakeholders, DSAs ensure that each stage of the migration, from scoping and workspace assessment to deployment and validation, is centered around tailored solutions and faster time to value. To explore how a DSA can support your Unity Catalog migration journey with tailored planning and expert oversight, reach out to your Databricks account team.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.