Farewell, CUDA OOM: Automatic Gradient Accumulation
by Mihir Patel and Erica Ji Yuen
With automatic gradient accumulation, Composer lets users seamlessly change GPU types and number of GPUs without having to worry about batch size. CUDA out of memory errors are a thing of the past!
It’s a tale as old as time -- from the early days of Caffe to latest frameworks such as JAX, CUDA throwing Out Of Memory (OOM) errors has always existed. With increasing model sizes, and growing heterogeneity in hardware with different memory limits, making sure your model does not OOM is a delicate balance of tinkering with the magic combination of batch size, gradient accumulation steps, and number of devices.
Now, with Composer, you’ll rarely have to worry about CUDA out of memory exceptions again. Introducing automatic gradient accumulation:
a simple but useful feature with which we will automatically catch CUDA Out of Memory errors during training, and dynamically adjust the number of gradient accumulation steps to stay within your hardware’s available memory.
With this simple flag, you can now train on any device, any number of devices, modify your batch sizes, or apply some of our algorithms, without fear of CUDA OOM. This obviates the tedious job of dialing in the gradient accumulation settings through trial and error!
Here’s a plot where we use Composer to train the same GPT3-125M model with a global batch size of 1024 sequences, on 1, 8, and 32 GPUs, with no changes to our training script. Composer automatically splits the global batch size among the devices, and determines the number of gradient accumulation steps to fit within each device’s GPU memory. The convergence is the same, and only the gradient accumulation and throughputs are different:
![Figure 1: GPT3-125M training on [1,8,32] x A100-40GB GPU.](https://www.databricks.com/sites/default/files/inline-images/farewell-cuda-oom-img-1.png)
Not only does Auto Grad Accum adjust automatically when training starts, but we also monitor and catch any OOMs over the full course of the training run. This not only lifts the cognitive burden of monitoring memory usage for the user, but also leads to improved efficiency -- we only decrease the microbatch size as necessary to fit into memory.
Let's see that in action when we train ResNet-50 on ImageNet with a large batch size on a single GPU! We use Progressive Image Resizing to slowly increase the image size (and therefore the memory footprint). In the plot below, see how we catch the CUDA OOMs and adjust the gradient accumulation automatically throughout training.
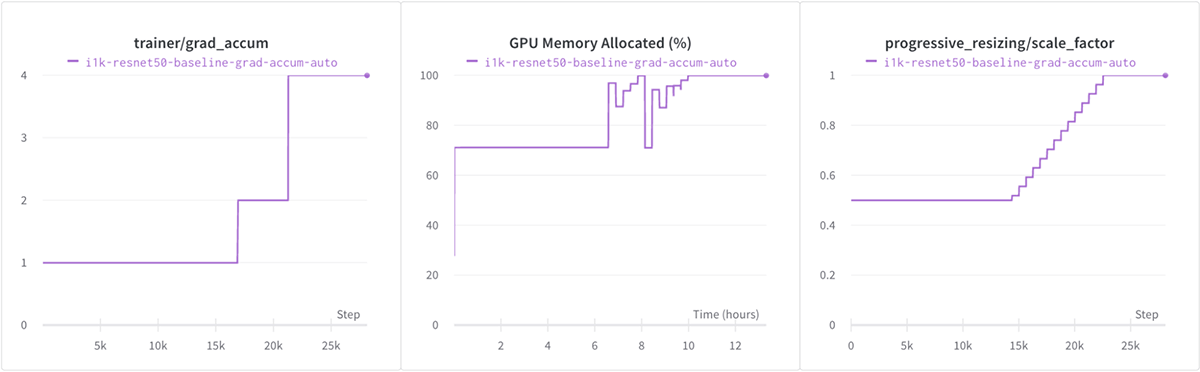
Here’s some more detail on gradient accumulation, and how we implemented this feature.
Gradient Accumulation
When training a model, we usually want to use a specific global batch size, as it is tuned along with other optimization hyperparameters such as the learning rate. For example, we may want to reproduce a research paper or check if larger batch sizes may improve performance. However, our device (e.g. GPU) memory may not be sufficient to support those batch sizes. Instead, we can employ gradient accumulation, in which a single minibatch is split into multiple smaller microbatches, each of which is run serially followed by a single update using their accumulated gradients. That way, the peak memory usage is reduced to what a single microbatch requires.
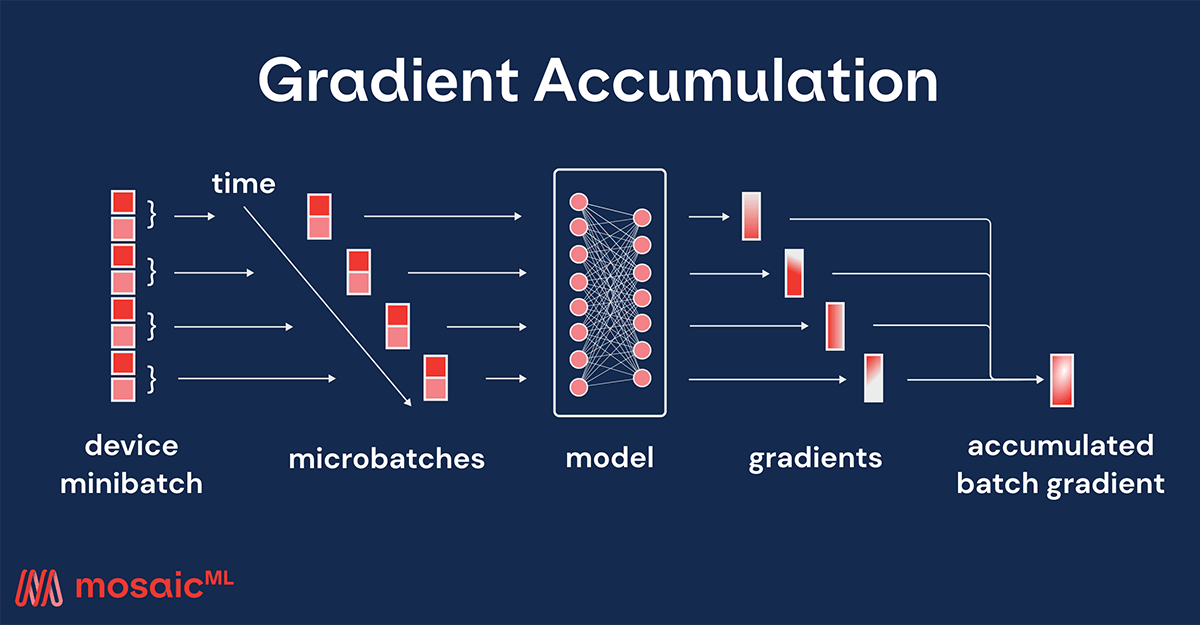
Setting the gradient accumulation to 4 with Composer would look like this:
While powerful, it's tedious to constantly try different gradient accumulation steps to get your training workload to fit, and more so to adjust whenever you change the batch size, move between a Colab notebook and a different GPU, or change how many GPUs you use.
Another important consideration is dynamism: memory consumption is not a constant throughout training. Some speedup methods increase the memory consumption throughout training, risking the frustrating experience of OOMs occurring at a point late in the training run. Even the minor variations in memory consumption by the Python runtime can trigger OOM events unpredictably. ML practitioners have often defended themselves from these in their code, with a hodgepodge of memory management techniques. It would be much better if the training loop itself could be more robust.
Enter Automatic Gradient Accumulation
To solve these challenges, Composer now supports automatic gradient accumulation. Simply by setting the "grad_accum" parameter to "auto," we will catch CUDA OOM exceptions during training, double the number of microbatches, and attempt to retrain the batch that failed. Now, by setting a single parameter, most Out of Memory errors are a thing of the past.
We take advantage of a unique design within our Trainer -- we ask each device’s dataloader to return the complete device batch, and the Trainer handles slicing that batch into microbatches and feeding it to the model. Since we control the slicing, we can dynamically change the microbatch sizes during training.
Then, we simply catch CUDA OOMs, double the gradient accumulation, and retry. If a microbatch size of 1 still doesn’t fit in memory, we throw an error.
Here’s a comparison of convergence results when training a vision model with progressive image resizing. We use grad_accum=”auto” in purple, and a fixed grad_accum=4 in gray:
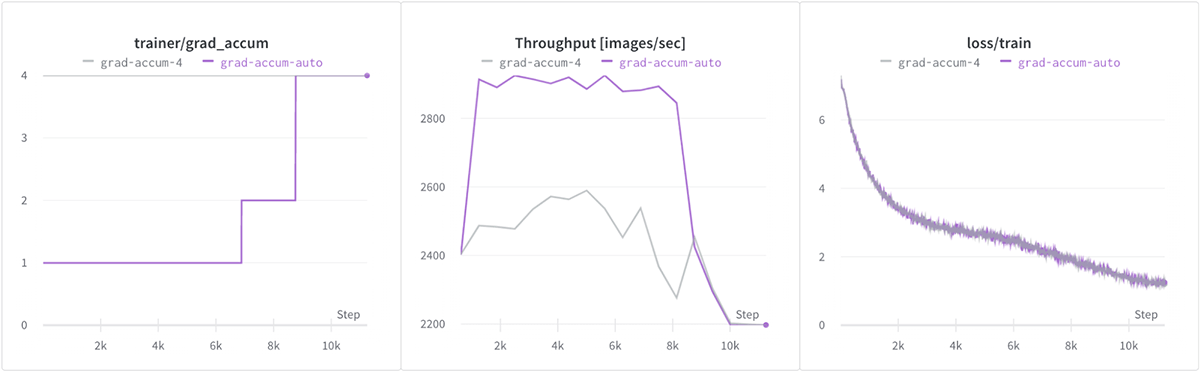
Not only does automatic gradient accumulation prevent OOMs, but it also leads to a ~16% throughput increase because we can use larger microbatches earlier in training. This is not possible with a fixed grad_accum -- even after manual tuning -- because we can only use one value, and have to satisfy the memory constraints of the larger images at the end of training.
A hardware-independent future
Beyond saving users tedious experimentation time, automatic gradient accumulation unlocks the potential for more speedups and cost savings. Since automatic gradient accumulation allows the same hyperparameters to be used for different hardware, this unlocks a whole new category of speedups where the hardware or number of devices is changed throughout the training process. One opportunity in this space is particularly useful for multi-node training in multi-tenant environments offered by public cloud providers. Now, variations in node availability can be accommodated across GPU types, which can be the difference between having a job wait for many hours in a queue, and starting immediately.
Additionally, since automatic gradient accumulation allows the hyperparameters to be used for different hardware, this unlocks a whole new category of speedups where the hardware is changed throughout the training process. For example, in the previous example with progressive image resizing, if the batch size’s memory footprint becomes small enough, we might even be able to downgrade to a lower tier GPU to decrease the cost of the initial part of the training run!
Conclusion
With automatic gradient accumulation, train your models across different hardware and experiment with advanced speedup methods without the need to search for a magical combination of settings that fits into GPU memory. If you like our Composer library, please give it a star on GitHub!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.