How Lakehouse AI improves model accuracy with real-time computations
by Avesh Singh and Mani Parkhe
The predictive quality of a machine learning model is a direct reflection of the quality of data used to train and serve the model. Usually, the features, or input data to the model, are calculated in advance, saved, and then looked up and served to the model for inference. The challenge arises when these features cannot be pre-calculated, as model performance often correlates directly with the freshness of the data used for feature computation. To simplify the challenge of serving this class of features, we are excited to announce On Demand Feature Computation.
Use cases like recommendations, security systems, and fraud detection require that features be computed on-demand at the time of scoring these models. Scenarios include:
- When the input data for features is only available at the time of model serving. For instance,
distance_from_restaurantrequires the last known location of a user determined by a mobile device. - Situations where the value of a feature varies depending on the context in which it's used. Engagement metrics should be interpreted very differently when
device_typeis mobile, as opposed to desktop. - Instances where it's cost-prohibitive to precompute, store, and refresh features. A video streaming service may have millions of users and tens of thousands of movies, making it prohibitive to precompute a feature like
avg_rating_of_similar_movies.
In order to support these use cases, features must be computed at inference time. However, feature computation for model training is typically performed using cost-efficient and throughput-optimized frameworks like Apache Spark(™). This poses two major problems when these features are required for real-time scoring:
- Human effort, delays, and Training/Serving Skew: The architecture all-too-often necessitates rewriting feature computations in server-side, latency-optimized languages like Java or C++. This not only introduces the possibility of training-serving skew as the features are created in two different languages, but also requires machine learning engineers to maintain and sync feature computation logic between offline and online systems.
- Architectural complexity to compute and provide features to models. These feature engineering pipelines systems need to be deployed and updated in tandem with served models. When new model versions are deployed, they require new feature definitions. Such architectures also add unnecessary deployment delays. Machine learning engineers need to ensure that new feature computation pipelines and endpoints are independent of the systems in production in order to avoid running up against rate limits, resource constraints, and network bandwidths.
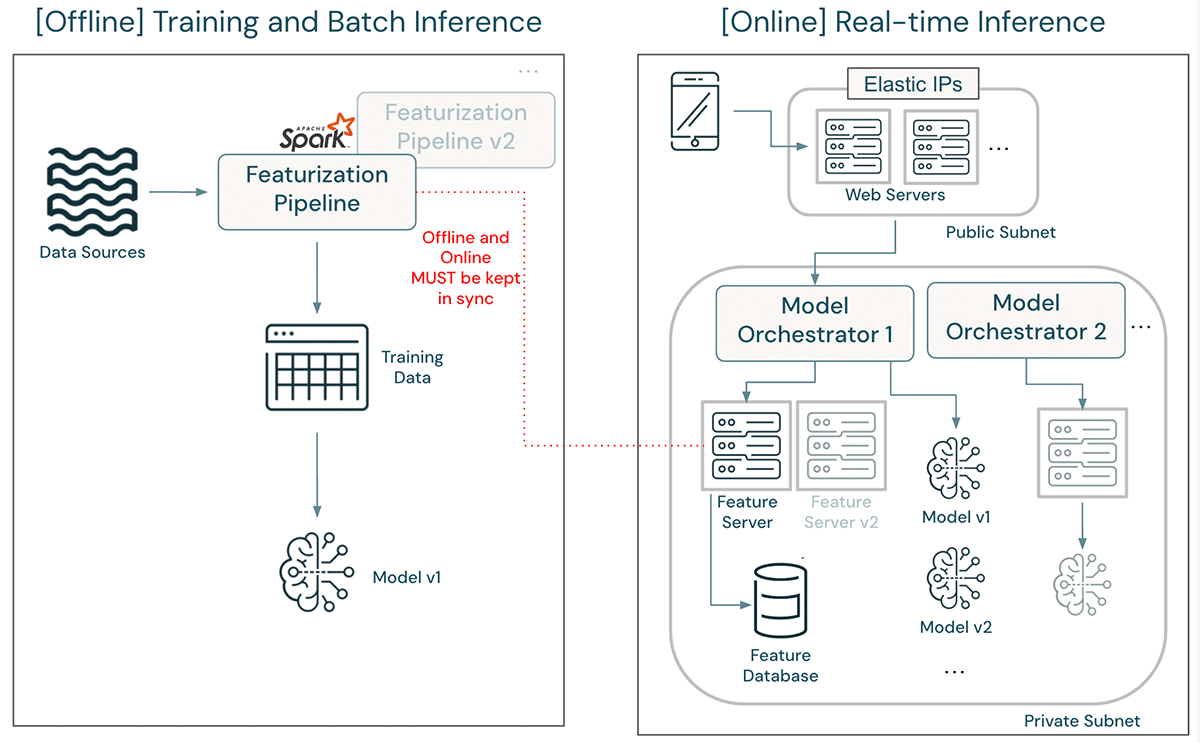
In the above architecture, updating a feature definition can be a major undertaking. An updated featurization pipeline must be developed and deployed in tandem with the original, which continues to support training and batch inference with the old feature definition. The model must be retrained and validated using the updated feature definition. Once it is cleared for deployment, engineers must first rewrite feature computation logic in the feature server and deploy an independent feature server version so as to not affect production traffic. After deployment, numerous tests should be run to ensure that the updated model's performance is the same as seen during development. The model orchestrator must be updated to direct traffic to the new model. Finally, after some baking time, the old model and old feature server can be taken down.
To simplify this architecture, improve engineering velocity, and increase availability, Databricks is launching support for on-demand feature computation. The functionality is built directly into Unity Catalog, simplifying the end-to-end user journey to create and deploy models.
On-demand features helped to substantially reduce the complexity of our Feature Engineering pipelines. With On-demand features we are able to avoid managing complicated transformations that are unique to each of our clients. Instead we can simply start with our set of base features and transform them, per client, on-demand during training and inference. Truly, on-demand features have unlocked our ability to build our next generation of models. - Chris Messier, Senior Machine Learning Engineer at MissionWired
Using Functions in Machine Learning Models
With Feature Engineering in Unity Catalog, data scientists can retrieve pre-materialized features from tables and can compute on-demand features using functions. On-demand computation is expressed as Python User-Defined Functions (UDFs), which are governed entities in Unity Catalog. Functions are created in SQL, and can then be used across the lakehouse in SQL queries, dashboards, notebooks, and now to compute features in real-time models.
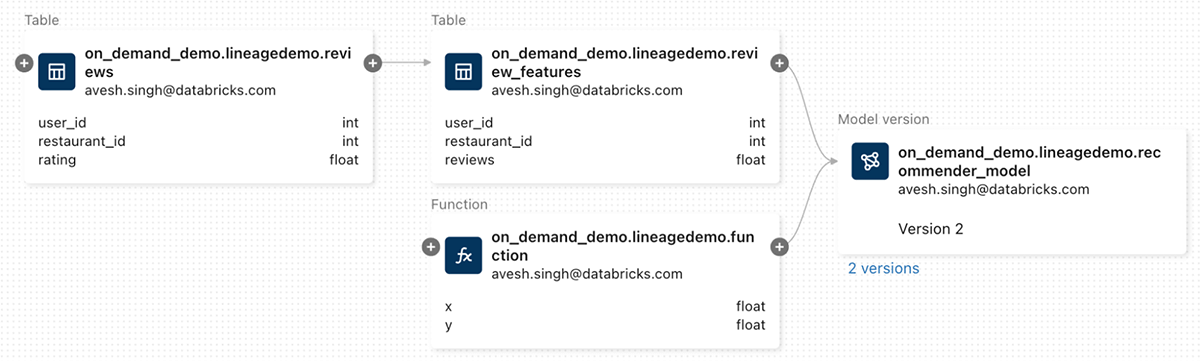
The UC lineage graph records dependencies of the model on data and functions.
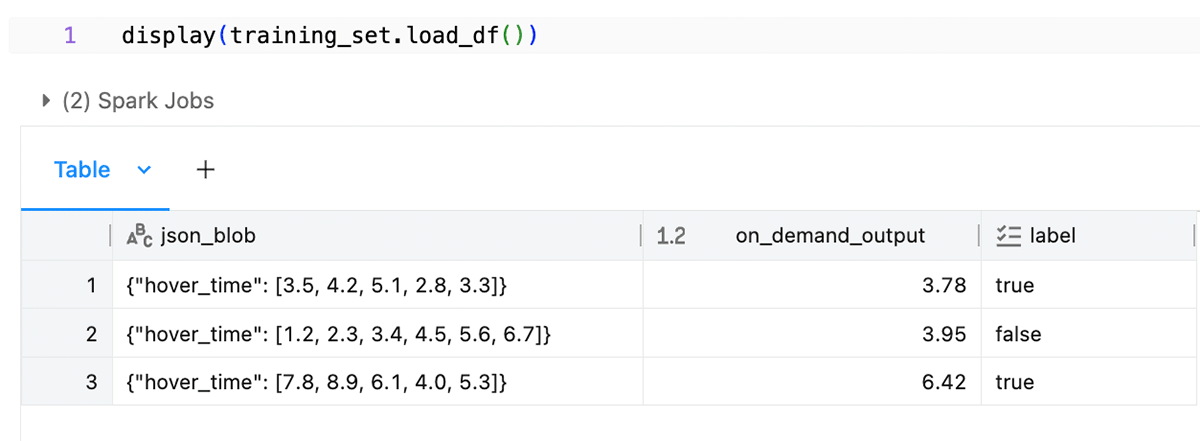
To use a function in a model, include it in the call to create_training_set.
The function is executed by Spark to generate training data for your model.
The function is also executed in real-time serving using native Python and pandas. While Spark is not involved in the real-time pathway, the same computation is guaranteed to be equivalent to that used at training time.
A Simplified Architecture
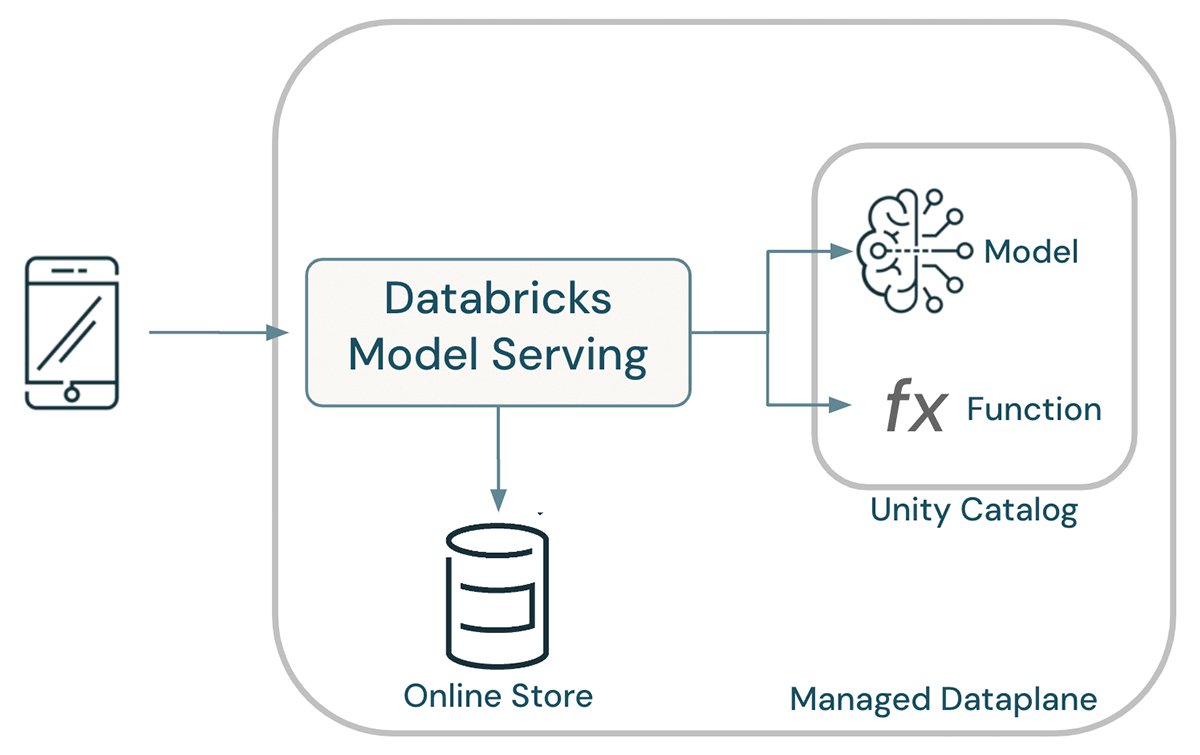
Models, functions, and data all coexist within Unity Catalog, enabling unified governance. A shared catalog enables data scientists to re-use features and functions for modeling, ensuring consistency in how features are calculated across an organization. When served, model lineage is used to determine the functions and tables to be used as input to the model, eliminating the possibility of training-serving skew. Overall, this results in a dramatically simplified architecture.
Lakehouse AI automates the deployment of models: when a model is deployed, Databricks Model Serving automatically deploys all functions required to enable live computation of features. At request time, pre-materialized features are looked up from online stores and on-demand features are computed by executing the bodies of their Python UDFs.
Simple Example - Average hover time
In this example, an on-demand feature parses a JSON string to extract a list of hover times on a webpage. These times are averaged together, and the mean is passed as a feature to a model.
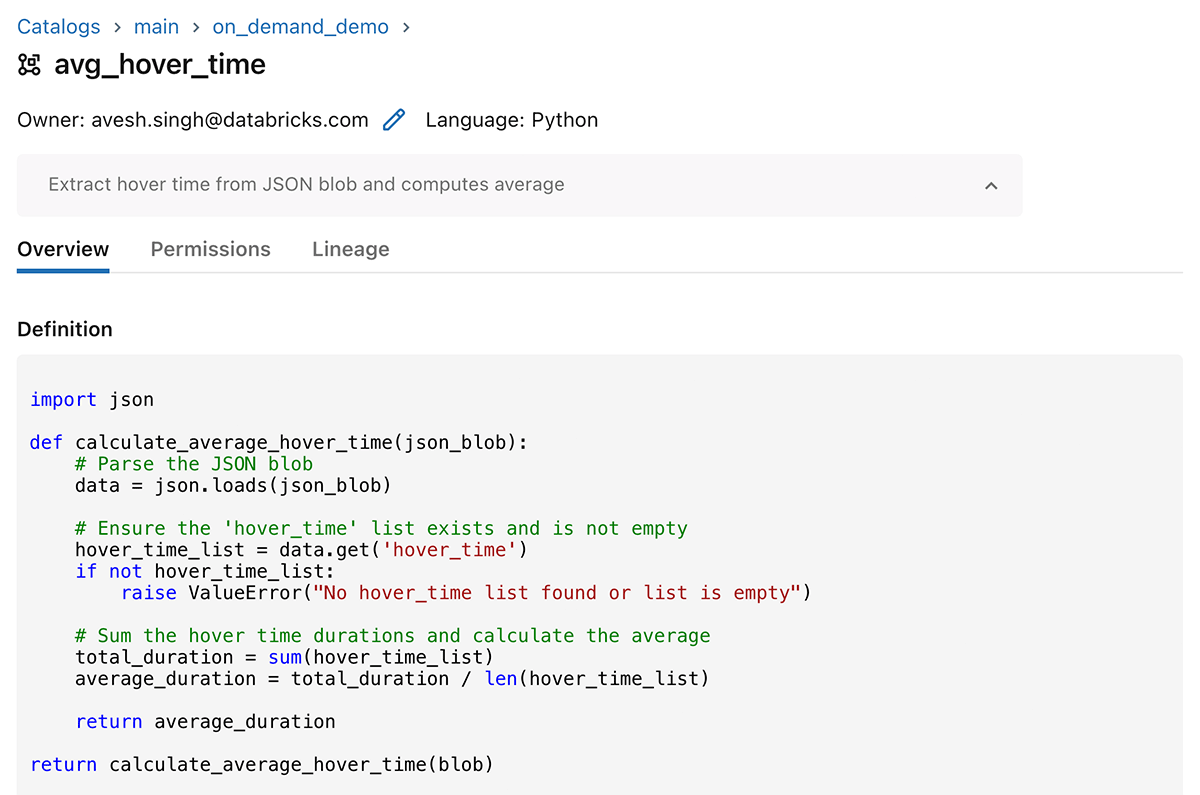
The query the model, pass a JSON blob containing hover times. For example:
The model will compute the average hover time on-demand, then will score the model using average hover time as a feature.
Sophisticated Example - Distance to restaurant
In this example, a restaurant recommendation model takes a JSON string containing a user's location and a restaurant id. The restaurant's location is looked up from a pre-materialized feature table published to an online store, and an on-demand feature computes the distance from the user to the restaurant. This distance is passed as input to a model.
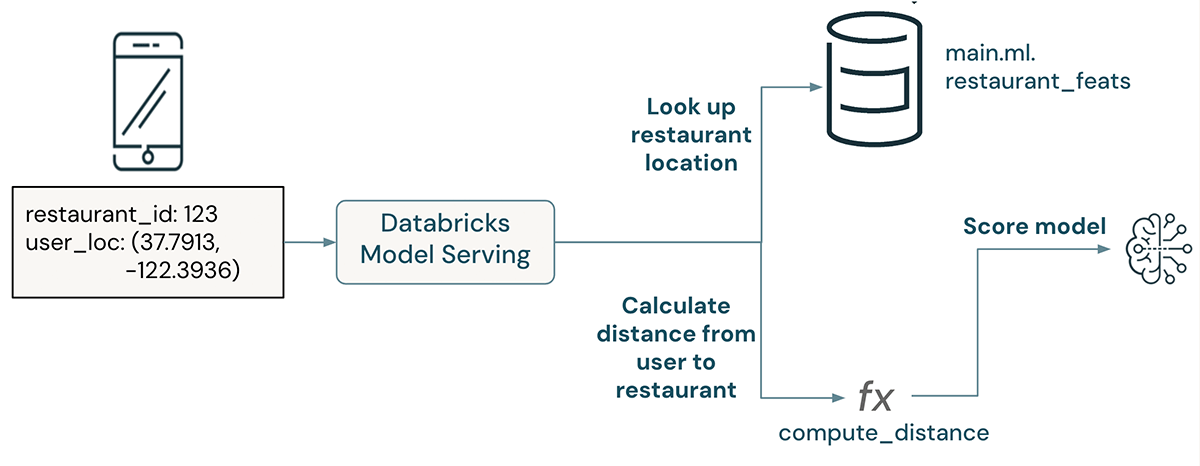
Notice that this example includes a lookup of a restaurant's location, then a subsequent transformation to compute the distance from this restaurant to the user.
Restaurant Recommendation Demo
Learn More
For API documentation and additional guidance, see Compute features on demand using Python user-defined functions.
Have a use case you'd like to share with Databricks? Contact us at on-demand-features@databricks.com.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.