Introducing Agent Bricks: Auto-Optimized Agents Using Your Data
by Xiangrui Meng, Kasey Uhlenhuth, Hanlin Tang, Patrick Wendell and Matei Zaharia
- Auto-optimized agents: Build high-quality, domain-specific agents by describing the task—Agent Bricks handles evaluation and tuning.
- Fast, cost-efficient results: Achieve higher quality at lower cost with automated optimization powered by Databricks research.
- Trusted in production: Used by Flo Health, AstraZeneca, and more to scale safe, accurate AI in days, not weeks.
Last year, the promise of data intelligence – building AI that can reason over your data – arrived with Databricks, a comprehensive platform for building, evaluating, monitoring, and securing AI systems. Since then, thousands of our customers have shipped data intelligence into production, building domain-specific agents powered by their enterprise data:
- Mastercard shipped digital assistants to accelerate customer onboarding
- AT&T protects wireless customers from fraud and harm
- Crisis Text Line built AI agents specialized for mental health to train the next generation of crisis counselors
- Block shipped goose, an AI coding assistant grounded in enterprise context
However, the immaturity of the generative technology meant that the journey to production was still challenging. Building high-quality agents was often too complex, for several reasons:
- Evaluation is difficult: Many enterprise AI tasks are difficult to evaluate, for both humans and even automated LLM judges. Academic benchmarks such as math exams did not translate to real-world use cases. Building nuanced evaluations often required expensive manual labeling. As a result, promising projects stalled in endless tuning cycles, with stakeholders losing confidence due to unclear progress.
- Too many knobs: Agents are complex AI systems with many components, each that have their own knobs. From tuning prompts to index chunking strategies to model choices and fine-tuning parameters, each adjustment creates unknown effects across the system. What should be fast iterative improvement becomes an expensive and tedious manual trial-and-error, slowing time to production.
- Cost and quality: Even after teams solve the above issues and build a high-quality agent, they are often surprised to find that the agent is too expensive to scale into production. So teams get stalled in either a long cost optimization process, or are forced to make trade-offs between cost and quality.
Agent Bricks: Auto-optimizing agents for your domain tasks
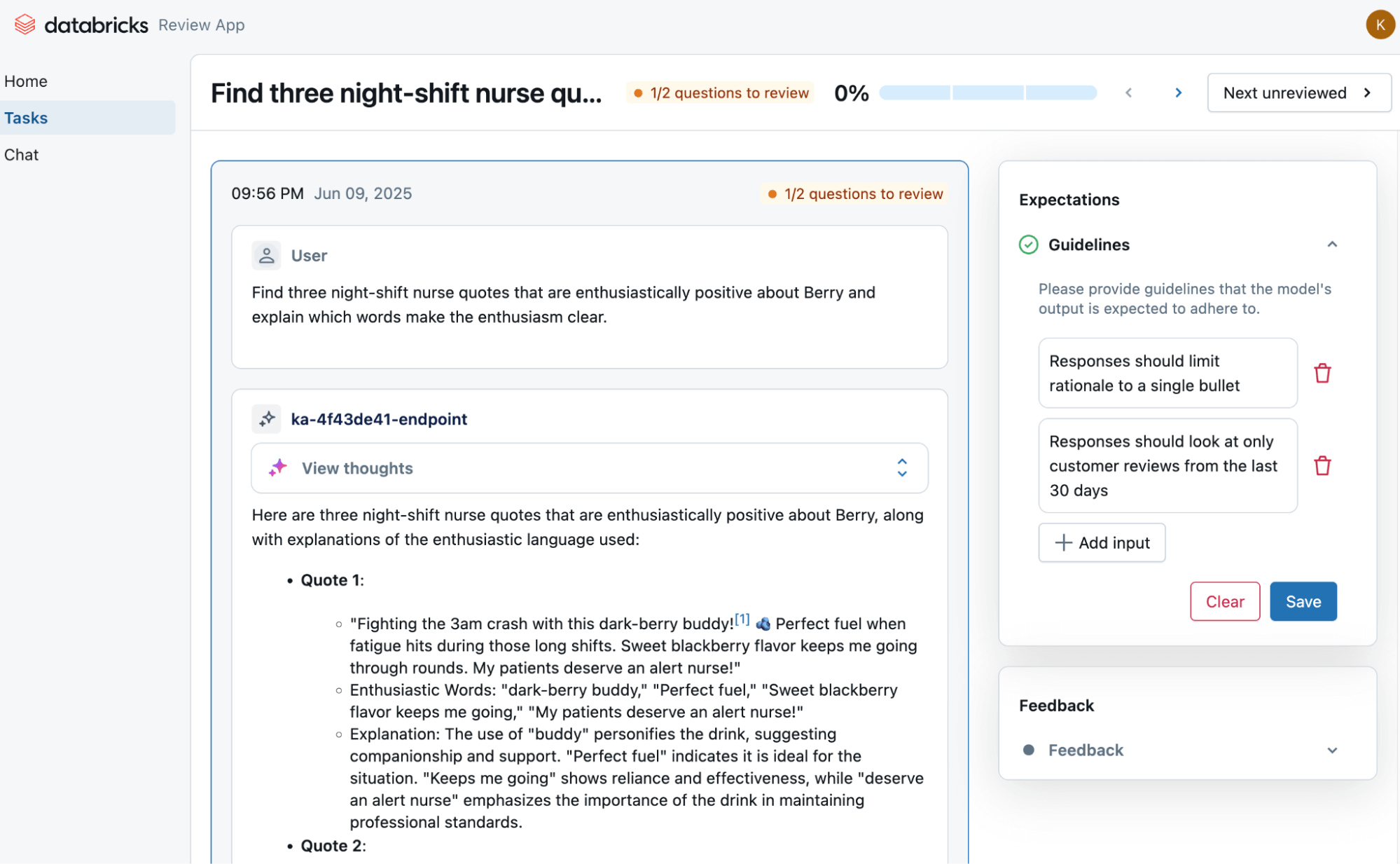
Based on our above experiences working with customers to ship AI into production, we’ve spent the last year re-thinking how to build agents. Today, we're introducing Agent Bricks, a new product that changes how enterprises develop domain-specific agents. Rather than managing the overwhelming complexity of agent development, teams can focus on what matters most: defining their agent's purpose and providing strategic guidance on quality through natural language feedback. Agent Bricks handles the rest, automatically generating evaluation suites and auto-optimizing the quality.
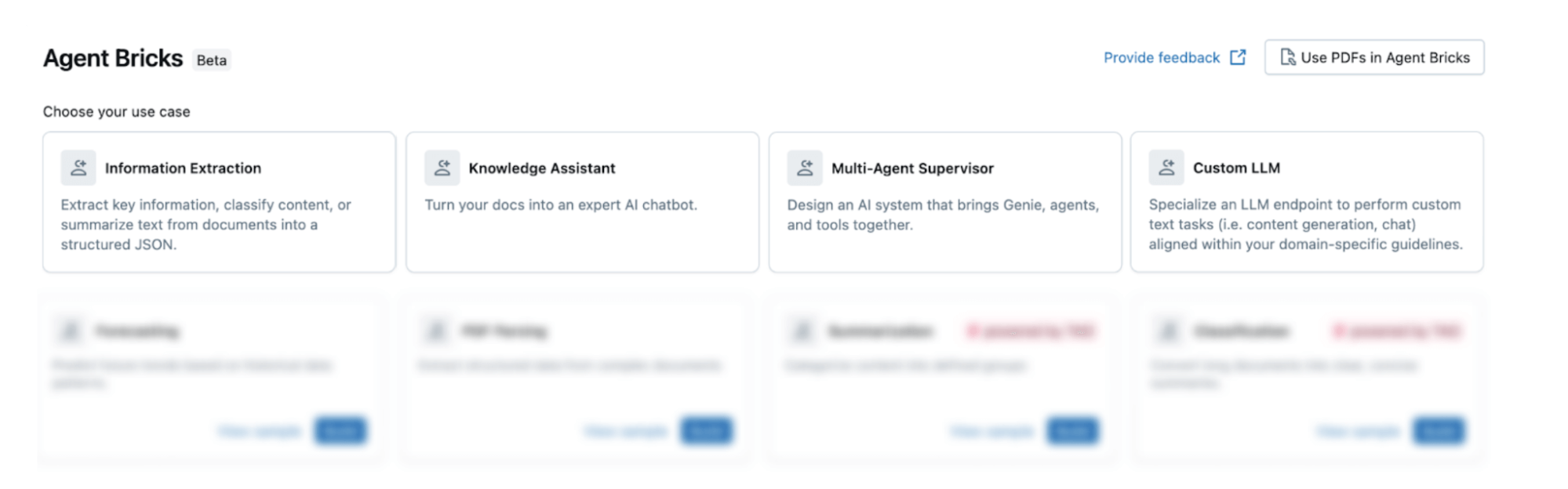
Here’s how it works:
- Declare your task. Select your task, define in natural language a high-level description of what you want the agent to accomplish, and connect your data sources.
Automatic evaluation: Agent Bricks will then automatically create evaluation benchmarks specific to your task, which may involve synthetically generating new data or building custom LLM judges.
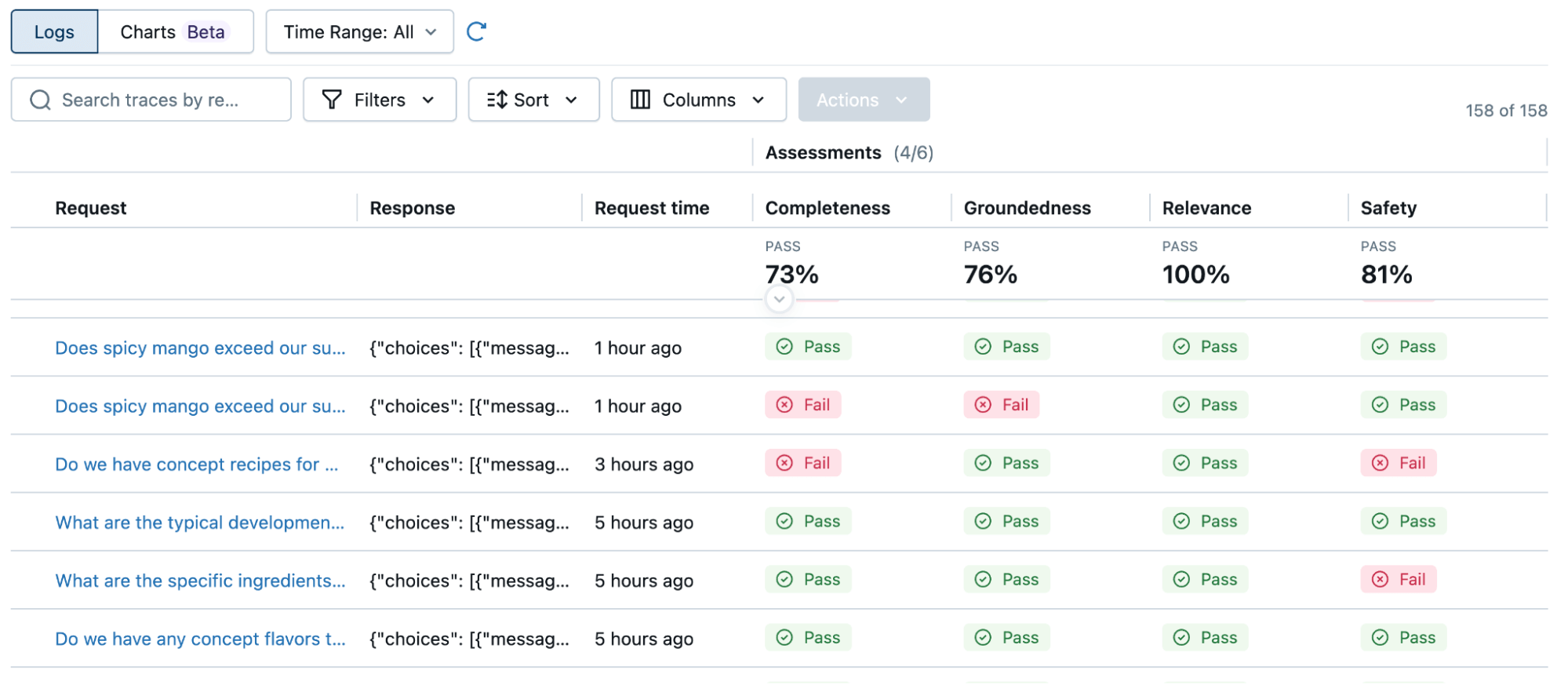
Powered by MLflow 3, Agent Bricks automatically creates evaluation datasets and custom judges tailored to your task. - Automatic Optimization: Agent Bricks intelligently searches through and combines various optimization techniques, such as prompt engineering, model-finetuning, reward models, or test-adaptive optimization (TAO) to achieve high quality.
- Cost and quality: Agent Bricks ensures agents are not only highly effective but also cost-effective. Users can choose between cost-optimized or quality-optimized models. In many cases, the end solution is both higher quality and lower cost compared to other DIY approaches.
With Agent Bricks, eliminate guesswork through automatic evaluations. We auto-optimize the knobs, so you can trust your agent's performance and know you're running at peak efficiency. The end result is that you can now ship high-quality and cost-efficient agents into production. Agent Bricks is optimized for common industry use cases, including structured information extraction, reliable knowledge assistance, custom text transformation, and orchestrated multi-agent systems.
Build high-quality agents with Agent Bricks
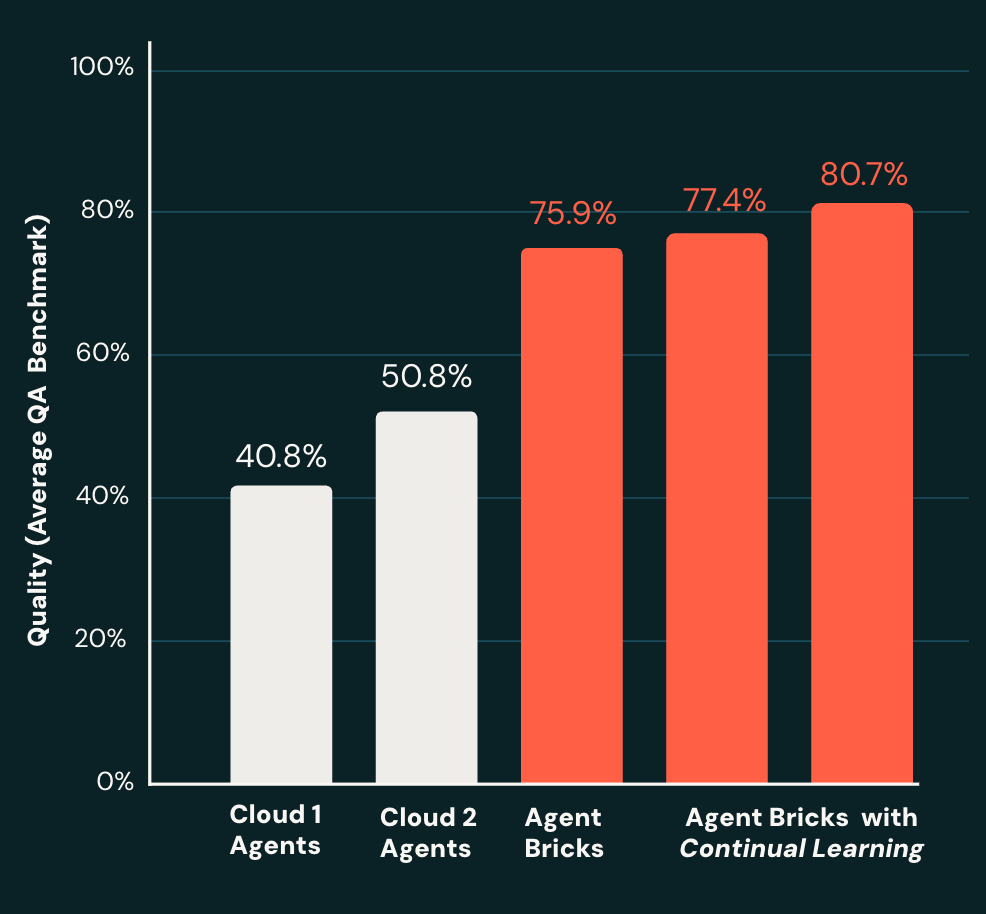
Agent Bricks is uniquely able to measure, build, and continually improve quality. With building conversational agents over documents, for example, we measured quality average across several Q&A benchmarks. Compared to other products in this space, Agent Bricks built significantly higher quality agents (Figure 1). Not only that, with the ability for continual learning, performance continues to improve over time.
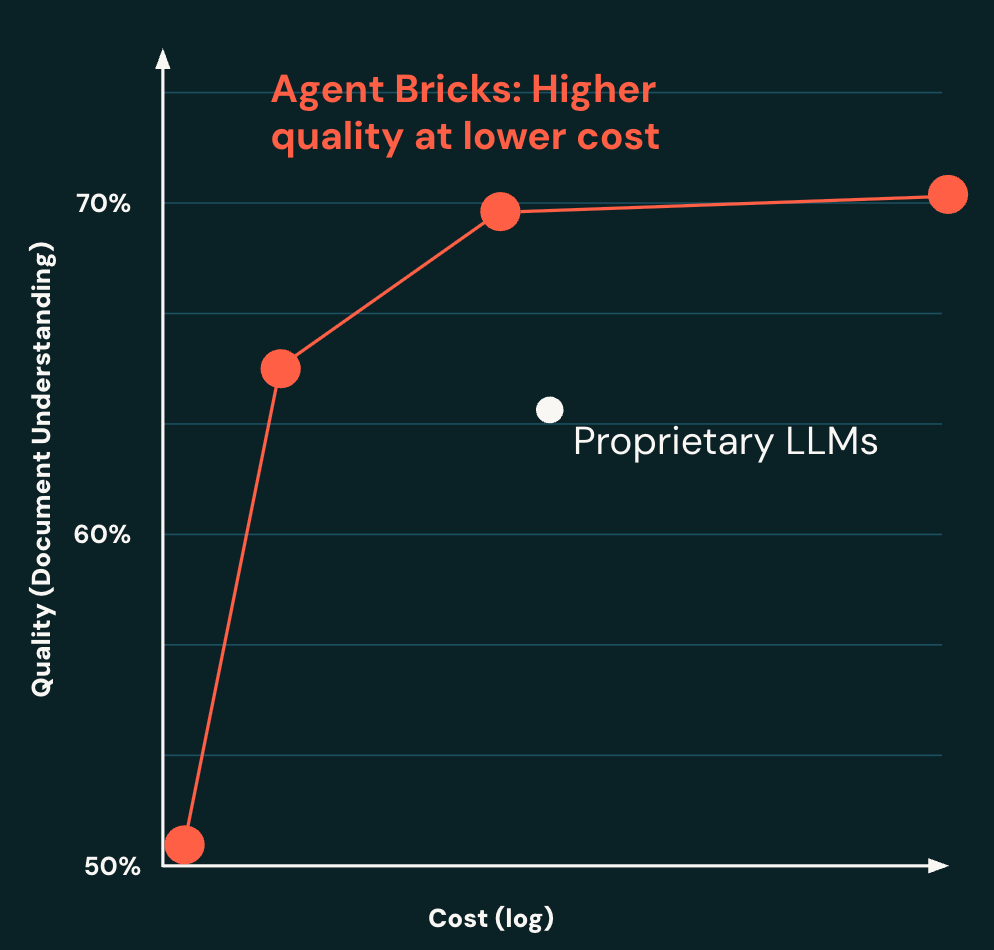
For document understanding, Agent Bricks builds higher-quality and lower-cost systems, compared to prompt-optimized proprietary LLMs (Figure 2). We can achieve a system that is higher quality on a document parsing benchmark, but up to 10x lower cost.
Beyond these benchmarks, our customers are also able to build quality agents with Agent Bricks:
"Agent Bricks enabled us to double our medical accuracy over standard commercial LLMs, while meeting Flo Health's high internal standards for clinical accuracy, safety, privacy, and security." —Roman Bugaev, CTO, Flo Health
“Agent Bricks significantly outperformed our original open-source implementation in both LLM-as-judge and human evaluation accuracy metrics.” —Joel Wasson, Enterprise Data & Analytics, Hawaiian Electric
“[Agent Bricks] accelerated our AI capabilities across the enterprise, guiding us through quality improvements in the feedback loop and identifying lower-cost options that perform just as well.” —Chris Nishnick, Director of AI, Lippert
Powered by the latest research in agent learning
Agent Bricks is able to achieve these results because it is powered by the research coming from our Databricks Research team. There’s a zoo of methods for improving agent quality, and new research is released at a breathless pace. Our team both curates existing research and also develops new innovations that are then used by Agent Bricks during the automatic evaluation and optimization phase. While we have an expansive set of methods, today we are excited to highlight one of our innovations – Agent Learning from Human Feedback (ALHF).
Agent Learning from Human Feedback (ALHF)
A key challenge to quality is the ability to steer agent behavior from feedback. This is particularly difficult because feedback is often only provided with a thumbs up or thumbs down, and it's unclear which of the many components and knobs inside an agent system need to be adjusted to respect the feedback. The current approach, which is to pack all the instructions into one massive LLM prompt, is brittle and does not generalize to a more complex agent system.
With ALHF, we’ve solved this with two approaches. First, we are able to receive the rich context of natural language guidance (e.g. ignore all data before May 1990). Second, based on this natural language guidance, our algorithms intelligently translate the guidance into technical optimizations – refining the retrieval algorithm, enhancing prompts, filtering the vector database, or even modifying the agentic pattern.
This approach democratizes agent development, allowing domain experts to contribute directly to system improvement without deep technical expertise in AI infrastructure.
"The ability to continuously evaluate and improve accuracy is a key capability for Experian, especially in a highly regulated industry." —James Lin, Head of AI ML Innovation, Experian
The Path Forward: From Lab to Production in Days, Not Months
Early customers are already experiencing the transformation Agent Bricks delivers ��– accuracy improvements that double performance benchmarks and reduce development timelines from weeks to a single day. More importantly, they're achieving something that seemed impossible just months ago: sustainable, scalable AI systems that deliver consistent business value.
Agent Bricks represents more than an evolution in tooling – it's a fundamental shift toward mature, production-ready AI development. As agent systems become increasingly central to enterprise operations, the “vibe check” approaches of the past simply won't scale. Organizations need a robust, systematic approach to building and optimizing intelligent agents that can handle the complexity and requirements of real-world business applications.
Customers using Agent Bricks
Many Databricks customers have already built AI Agents with Agent Bricks, and we’re all looking forward to seeing what they can do in the future.
Watch the video with Experian and Flo Health
“With Agent Bricks, our teams were able to parse through more than 400,000 clinical trial documents and extract structured data points, without writing a single line of code. In just under 60 minutes, we had a working agent that can transform complex unstructured data usable for Analytics.” —Joseph Roemer, Head of Data & AI, Commercial IT, AstraZeneca
“Agent Bricks allowed us to build a cost-effective agent we could trust in production. With custom-tailored evaluation, we confidently developed an information extraction agent that parsed unstructured legislative calendars, saving 30 days of manual trial-and-error optimization.” —Ryan Jockers, Assistant Director of Reporting and Analytics at the North Dakota University System
Try Agent Bricks Today
Ready to bridge the gap between “demo quality” and “production quality”? Agent Bricks is now available in beta.
Get started:
- Read the documentation
- Watch the keynote
- Watch customers describe the benefits of using Agent Bricks
- Discover Product Tour to explore how Databricks Agent Bricks lets you create intelligent, no-code AI agents that automatically optimize using your own data
The future of enterprise AI isn't about managing complexity – it's about focusing on the outcomes that matter while Agent Bricks handles the rest.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.