Linking the unlinkables; simple, automated, scalable data linking with Databricks ARC
by Robert Whiffin, Marcell Ferencz and Milos Colic


In April 2023 we announced the release of Databricks ARC to enable simple, automated linking of data within a single table. Today we announce an enhancement which allows ARC to find links between 2 different tables, using the same open, scalable, and simple framework. Data linking is a common challenge across Government - Splink, developed by the UK Ministry of Justice and which acts as the linking engine within ARC, exists to provide a powerful, open, and explainable entity resolution package.
Linking data is usually a simple task - there is a common field or fields between two different tables which give a direct link between them. The National Insurance number would be an example of this - two records which have the same NI number should be the same person. But how do you link data without these common fields? Or when the data quality is poor? Just because the NI number is the same, doesn't mean someone didn't make a mistake when writing it down. It is in these cases that we enter the realm of probabilistic data linking, or fuzzy matching. Below illustrates a case where we can link 2 tables to create a more complete view, but don't have a common key on which to link:


Clearly, these tables contain information about the same people - one of them is current, the other historic. Without a common field between the two though, how could one programmatically determine how to link the current with historical data?
Traditionally, solving this problem has relied on hard coded rules painstakingly handwritten over time by a group of expert developers. In the above case, simple rules such as comparing the birth years and first names will work, but this approach does not scale when there are many different attributes across millions of records. What inevitably happens is the development of impenetrably complex code with hundreds or thousands of unique rules, forever growing as new edge cases are found. This results in a brittle, hard to scale, even harder to change systems. When the primary maintainers of these systems leave, organisations are then left with a black box system representing considerable risk and technical debt.
Probabilistic linking systems use statistical similarities between records as the basis for their decision making. As machine learning (ML) systems, they do not rely on manual specifications of when two records are similar enough but instead learn where the similarity threshold is from the data. Supervised ML systems learn these thresholds by using examples of records that are the same (Apple & Aple) and those that aren't (Apple & Orange) to define a general set of rules which can be applied to record pairs the model hasn't seen before (Apple & Pear). Unsupervised systems do not have this requirement and instead look at just the underlying record similarities. ARC simplifies this unsupervised approach by applying standards and heuristics to remove the need to manually define rules, instead opting for using a looser ruleset and letting the computers do the hard work of figuring out which rules are good.
Linking 2 datasets with ARC requires just a few line of code:


This image highlights how ARC has linked (synthetic!) records together despite typos and transpositions - in line 1, the given name and surnames not only have typos but have also been column swapped.
Where linking with ARC can help
Automated, low effort linking with ARC creates a variety of opportunities:
- Reduce the time to value and cost of migrations and integrations.
- Challenge: Every mature system inevitably has duplicate data. Maintaining these datasets and their pipelines creates unnecessary cost and risk from having multiple copies of similar data; for example unsecured copies of PII data.
- How ARC helps: ARC can be used to automatically quantify the similarity between tables. This means that duplicate data and pipelines can be identified faster and at lower cost, resulting in a quicker time to value when integrating new systems or migrating old ones.
- Enable interdepartmental and inter-government collaboration.
- Challenge: There is a skills challenge in sharing data between national, devolved and local government which hinders the ability for all areas of government to make use of data for the public good. The ability to share data during the COVID-19 pandemic was crucial to the government's response, and data sharing is a thread running through the 5 missions of the 2020 UK National Data Strategy.
- How ARC helps: ARC democratises data linking by lowering the skills barrier - if you can write python, you can start linking data. What's more, ARC can be used to ease the learning curve of Splink, the powerful linking engine under the hood, allowing budding data linkers to be productive today whilst learning the complexity of a new tool.
- Link data with models tailored to the data's characteristics.
- Challenge: Time consuming, expensive linking models create an incentive to try and build models capable of generalising across many different profiles of data. It is a truism that a general model will be outperformed by a specialist model, but the realities of model training often prevent the training of a model per linking project.
- How ARC helps: ARC's automation means that specialised models trained to link a specific set of data can be deployed at scale, with minimal human interaction. This drastically lowers the barrier for data linking projects.
The addition of automated data linking to ARC is an important contribution to the realm of entity resolution and data integration. By connecting datasets without a common key, the public sector can harness the true power of their data, drive internal innovation and modernisation, and better serve their citizens. You can get started today by trying the example notebooks which can be cloned into your Databricks Repo from the ARC GitHub repository. ARC is a fully open source project, available on PyPi to be pip installed, requiring no prior data linking or entity resolution to get started.
Accuracy - to link, or not to link
The perennial challenge of data linking in the real world is accuracy - how do you know if you correctly identified every link? This is not the same as every link you have made being correct - you may have missed some. The only way to fully assess a linkage model is to have a reference data set, one where every record link is known in advance. This means we can then compare the predicted links from the model against the known links to calculate accuracy measures.
There are three common ways of measuring the accuracy of a linkage model: Precision, Recall and F1-score.
- Precision: what proportion of your predicted links are correct?
- Recall: what proportion of total links did your model find?
- F1-score: a blended metric of precision and recall which gives more weight to lower values. This means to achieve a high F1-score, a model must have good precision and recall, rather than excelling in one and middling in the other.
However, these metrics are only applicable when one has access to a set of labels showing the true links - in the vast majority of cases, these labels do not exist, and creating them is a labor intensive task. This poses a conundrum - we want to work without labels where possible to lower the cost of data linking, but without labels we can't objectively evaluate our linking models.
In order to evaluate ARCs performance we used FEBRL to create a synthetic data set of 130,000 records which contains 30,000 duplicates. This was split into 2 files - the 100,000 clean records, and 30,000 records which need to be linked with them. We use the unsupervised metric previously discussed when linking the 2 data sets together. We tested our hypothesis by optimizing solely for our metric over a 100 runs for each data set above, and separately calculating the F1 score of the predictions, without including it in the optimization process. The chart below shows the relationship between our metric on the horizontal axis versus the empirical F1 score on the vertical axis.
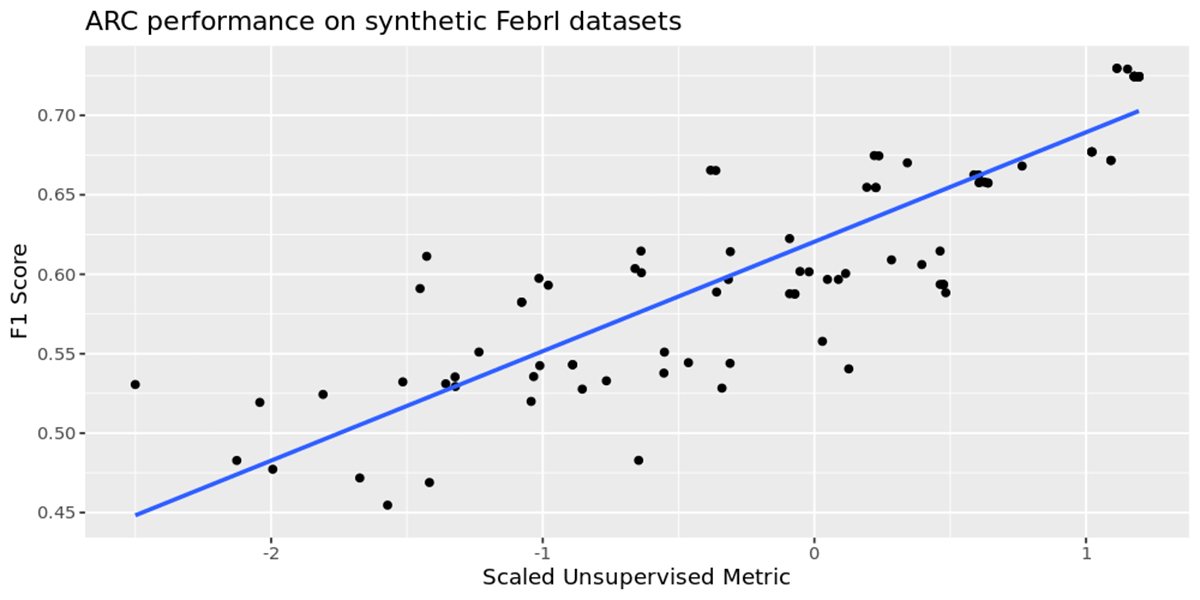
We observe a positive correlation between the two, indicating that by increasing our metric of the predicted clusters through hyperparameter optimization will lead to a higher accuracy model. This allows ARC to arrive at a strong baseline model over time without the need to provide it with any labeled data. This provides a strong data point to suggest that maximizing our metric in the absence of labeled data is a good proxy for correct data linking.
You can get started linking data today ARC by simply running the example notebooks after cloning the ARC GitHub repository into your Databricks Repo. This repo includes sample data as well as code, giving a walkthrough of how to link 2 different datasets, or deduplicate one dataset, all with just a few lines of a code. ARC is a fully open source project, available on PyPi to be pip installed, requiring no prior data linking or entity resolution experience to get started.
Technical Appendix - how does Arc work?
For an in-depth overview of how Arc works, the metric we optimise for and how the optimisation is done please visit the documentation at https://databricks-industry-solutions.github.io/auto-data-linkage/.
You can get started linking data today ARC by simply running the example notebooks after cloning the ARC GitHub repository into your Databricks Repo. This repo includes sample data as well as code, giving a walkthrough of how to link 2 different datasets, or deduplicate one dataset, all with just a few lines of a code. ARC is a fully open source project, available on PyPi to be pip installed, requiring no prior data linking or entity resolution experience to get started.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.