Fine-tuning Llama 3.1 with Long Sequences
by Saaketh Narayan, Irene Dea, Brian Chu, Shashank Rajput and Vitaliy Chiley
We are excited to announce that Databricks Model Training now supports the full context length of 131K tokens when fine-tuning the Meta Llama 3.1 model family. With this new capability, Databricks customers can build even higher-quality Retrieval Augmented Generation (RAG) or tool use systems by using long context length enterprise data to create specialized models.
The size of an LLM’s input prompt is determined by its context length. Our customers are often limited by short context lengths, especially in use cases like RAG and multi-document analysis. Meta Llama 3.1 models have a long context length of 131K tokens. For comparison, The Great Gatsby is ~72K tokens. Llama 3.1 models enable reasoning over an extensive corpus of data, reducing the need for chunking and re-ranking in RAG or enabling more tool descriptions for agents.
Fine-tuning allows customers to use their own enterprise data to specialize existing models. Recent techniques such as Retrieval Augmented Fine-tuning (RAFT) combine fine-tuning with RAG to teach the model to ignore irrelevant information in the context, improving output quality. For tool use, fine-tuning can specialize models to better use novel tools and APIs that are specific to their enterprise systems. In both cases, fine-tuning at long context lengths enables models to reason over a large amount of input information.
The Databricks Data Intelligence Platform enables our customers to securely build high-quality AI systems using their own data. To make sure our customers can leverage state-of-the-art Generative AI models, it is important to support features like efficiently fine-tuning Llama 3.1 on long context lengths. In this blog post, we elaborate on some of our recent optimizations that make Databricks Model Training a best-in-class service for securely building and fine-tuning GenAI models on enterprise data.
Long Context Length Fine-tuning
Long sequence length training poses a challenge mainly because of its increased memory requirements. During LLM training, GPUs need to store intermediate results (i.e., activations) in order to calculate gradients for the optimization process. As the sequence length of training examples increases, so does the memory required to store these activations, potentially exceeding GPU memory limits.
We solve this by employing sequence parallelism, where we split a single sequence across multiple GPUs. This approach distributes the activation memory for a sequence across multiple GPUs, reducing the GPU memory footprint for fine-tuning jobs and improving training efficiency. In the example shown in Figure 1, two GPUs each process half of the same sequence. We use our open source StreamingDataset’s replication feature to share samples across groups of GPUs.
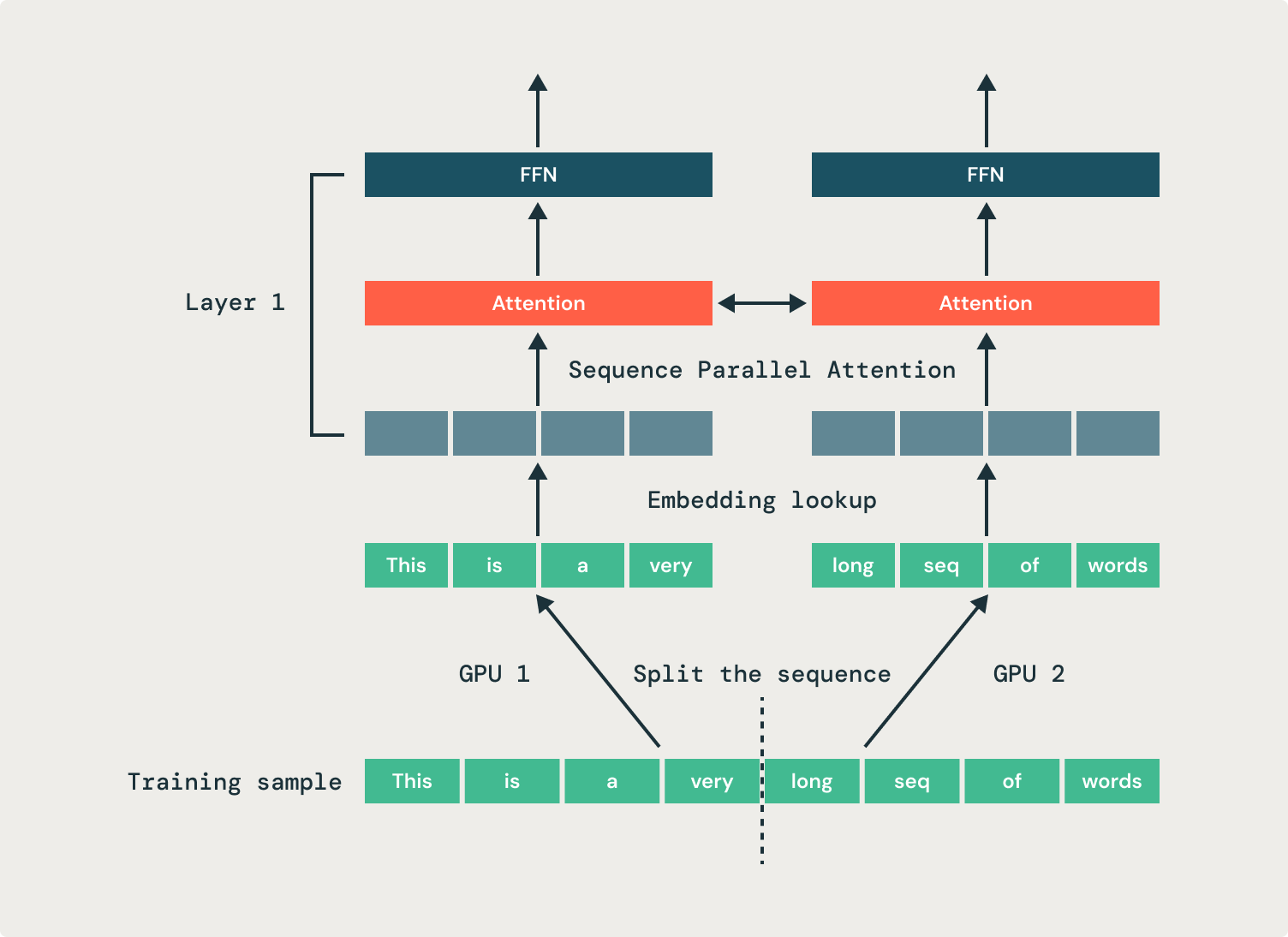
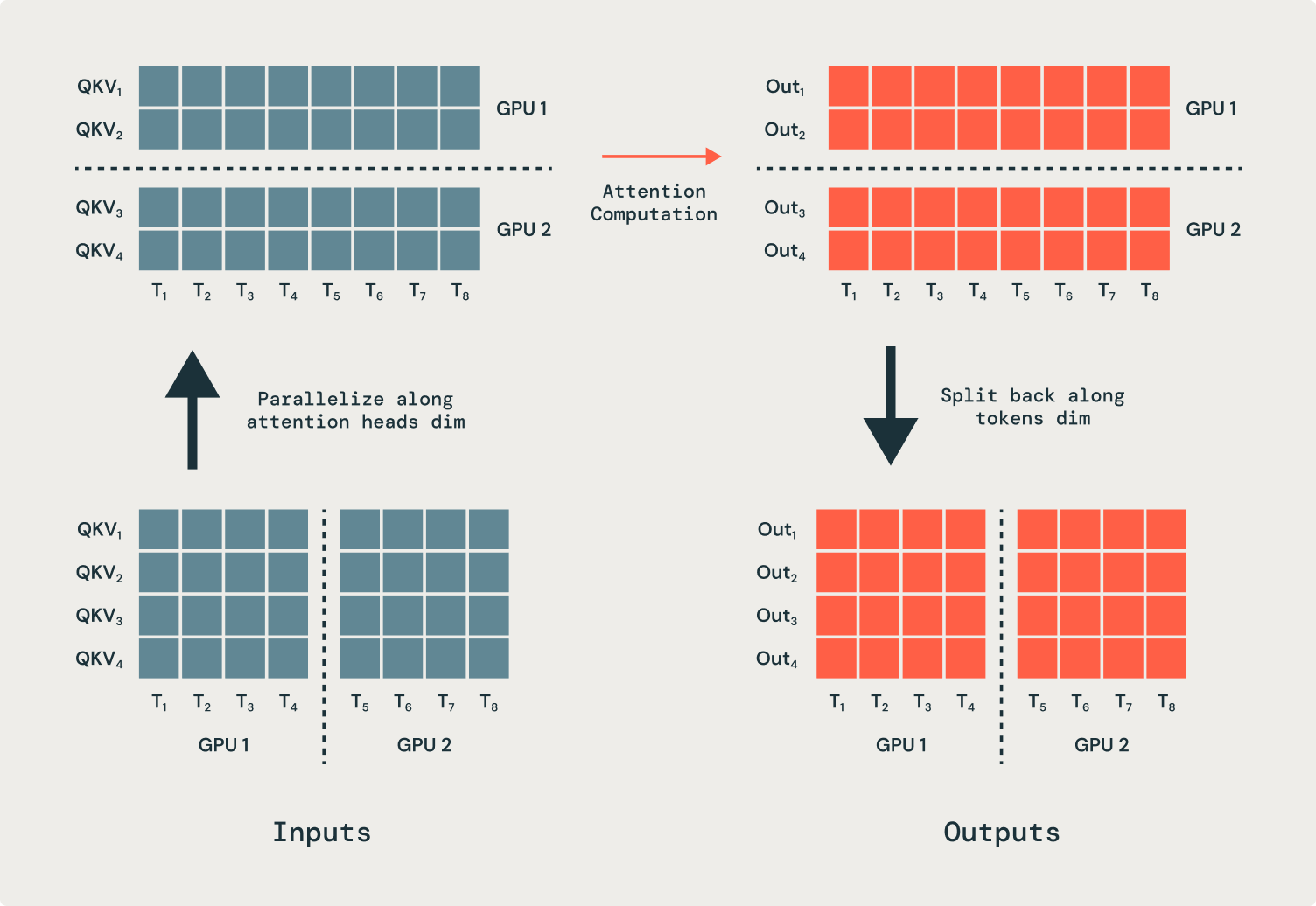
All operations in a transformer are independent of the sequence dimension—except, crucially, attention. As a result, the attention operation has to be modified to input and output partial sequences. We parallelize attention heads across many GPUs, which necessitates communication operations (all-to-alls) to move tokens to the correct GPUs for processing. Prior to the attention operation, each GPU has part of every sequence, but each attention head must operate on a full sequence. In the example shown in Figure 2, the first GPU gets sent all the inputs for just the first attention head, and the second GPU gets sent all the inputs for the second attention head. After the attention operation, the outputs are sent back to their original GPUs.
With sequence parallelism, we’re able to provide full-context-length Llama 3.1 fine-tuning, enabling custom models to understand and reason across a large context.
Optimizing Fine-tuning Performance
Custom optimizations like sequence parallelism for fine-tuning require us to have fine-grained control over the underlying model implementation. Such customization is not possible solely with the existing Llama 3.1 modeling code in HuggingFace. However, for ease of serving and external compatibility, the final fine-tuned model needs to be a Llama 3.1 HuggingFace model checkpoint. Therefore, our fine-tuning solution must be highly optimizable for training, but also able to produce an interoperable output model.
To achieve this, we convert HuggingFace Llama 3.1 models into an equivalent internal Llama representation prior to training. We’ve extensively optimized this internal representation for training efficiency, with improvements such as efficient kernels, selective activation checkpointing, effective memory use, and sequence ID attention masking. As a result, our internal Llama representation enables sequence parallelism while yielding up to 40% higher training throughput and requiring a 40% smaller memory footprint. These improvements in resource utilization translate to better models for our customers, since the ability to iterate quickly helps enable better model quality.
When training is finished, we convert the model from the internal representation back to HuggingFace format, ensuring that the saved artifact is immediately ready for serving via our Provisioned Throughput offering. Figure 3 below shows this entire pipeline.

Next Steps
Get started fine-tuning Llama 3.1 today via the UI or programmatically in Python. With Databricks Model Training, you can efficiently customize high-quality and open source models for your business needs, and build data intelligence. Read our documentation (AWS, Azure) and visit our pricing page to get started with fine-tuning LLMs on Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.