Introducing Llama2-70B-Chat with MosaicML Inference
by Hagay Lupesko, Margaret Qian, Daya Khudia, Sam Havens, Daniel King and Erica Ji Yuen
Llama2-70B-Chat is a leading AI model for text completion, comparable with ChatGPT in terms of quality. Today, organizations can leverage this state-of-the-art model through a simple API with enterprise-grade reliability, security, and performance by using MosaicML Inference and MLflow AI Gateway.
Llama2-70B-Chat is available via MosaicML Inference. To get started, sign up here and check out our inference product page. Curious about our pricing? Look here.

On July 18th, Meta published Llama2-70B-Chat: a 70B parameter language model pre-trained on 2 trillion tokens of text with a context length of 4096 that outperforms all open source models on many benchmarks, and is comparable in quality to closed proprietary models such as OpenAI's ChatGPT and Google PaLM-Bison. Meta made the model publicly available with a commercially permissive license that enables the broader ML community to learn from this work, build on top of it, and leverage it for commercial use cases.

However, enterprise deployment of Llama2-70B-Chat is challenging—and costly. Achieving adequate reliability, latency and throughput for commercial-grade applications requires state-of-the-art GPUs and sophisticated system and ML optimization. That's why we're making Llama2-70B-Chat available on the MosaicML Inference service. Customers who use the service can start experimenting with Llama2-70B-Chat within minutes, benefiting from enterprise-grade reliability, security, and performance, while paying for usage only on a per-token basis.
Read on to learn more about how to leverage Llama2-70B-Chat's enterprise-grade capabilities, integrate with MLflow AI Gateway, and design effective prompts.
Querying Llama2-70B-Chat with MosaicML Inference API
Invoking Llama2-70B-Chat text completion with MosaicML Inference is as easy as importing a Python Module and calling an API:
Here's the example response:
You can further customize your outputs with the following parameters:
- max_new_tokens: the maximum number of new tokens to generate.
- temperature: a decimal greater than or equal to 0. Higher values will make the output more random, while lower values will make it more deterministic. A temperature of 0 means greedy sampling.
- top_p: a decimal between 0 and 1 that controls how nucleus sampling is performed; the higher it is set, the more possible it is to pick unlikely continuations.
- top_k: an integer value that is 1 or higher. Determines how many tokens are considered at each token generation step.
For more information about using MosaicML Inference, take a look at the API documentation.
Querying Llama2-70B-Chat through MLflow AI Gateway
MLflow AI Gateway from Databricks is a highly scalable, enterprise-grade API gateway that enables organizations to manage their LLMs for experimentation and production use cases.
Using MLflow AI Gateway to query generative AI models enables centralized management of LLM credentials and deployments, exposes standardized interfaces for common tasks such as text completions and embeddings, and provides cost management guardrails.
You can now leverage MosaicML Inference API through MLflow AI Gateway on Databricks, and query Llama2-70B-Chat as well as other models including MPT text completion and Instructor text embedding models.
The following code snippet demonstrates how easy it is to query Llama2-70B-Chat through AI Gateway using the MLflow Python client:
Here's the example response:
Using MosaicML Inference and MLflow AI Gateway, ML engineers can now leverage pretrained language models to build generative AI applications such as Retrieval Augmented Generation (RAG). To learn more, check out this blog post from Databricks.
Enterprise-grade serving of Llama2-70B-Chat
There are three models in the Llama-v2 family with parameter sizes ranging from 14 GB to 140 GB in Float16 precision: Llama2-7B, Llama2-13B and Llama2-70B. Each of these have different inference hardware requirements for serving. For example, 7B models can easily fit on a single NVIDIA A10 GPU (24GB memory) or NVIDIA A100 GPU (40GB memory), while 70B doesn't in either Float16 or even Int8 precision.
For the 70B parameter model Llama2-70B-Chat, it's necessary to distribute the workload across multiple GPUs. However, multi-GPU serving is complicated and naively serving without optimizations is very expensive and slow.
Reliability
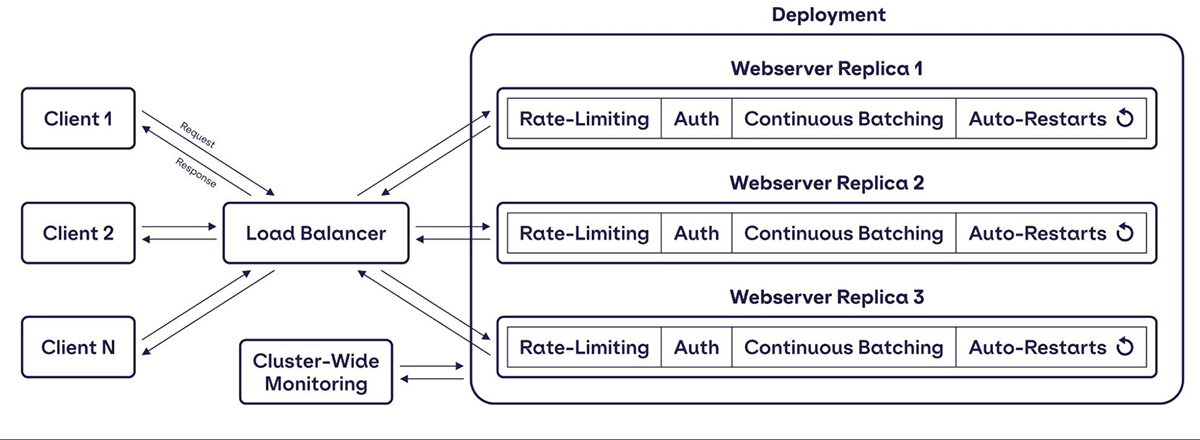
Our deployment of the 70B model is served with multiple replicas for redundancy, with built-in auto-restarts to handle failure recovery. If, for example, CUDA OOMs and a single replica goes down, the load balancer will route requests to other available replicas. The deployment itself is monitored to detect failures. Each replica implements rate limiting to ensure fairness among different clients and to avoid overloading the service. Moreover, we are working to have replicas deployed across multiple regions to ensure high availability.
Security
The MosaicML Inference platform is designed to maintain data privacy. User queries and responses generated by the model are not logged. The platform does not record or log any data provided by the user or generated by the model as a response to user prompts; it only records non-identifiable operational system metrics.
Performance
As briefly mentioned above, optimizations are what makes it possible to serve these large models efficiently. We include a number of optimizations, including Tensor Parallelism, KV cache techniques, continuous batching, and other efficient methods. Some of the optimizations we employ include:
Tensor Parallel: A 70B parameter model such as Llama2-70B-Chat requires either 140GB (Float16) or 70GB (Int8) just to store the weights in GPU memory. To address this constraint, we use a tensor parallel mechanism to fit the model into the memories of multiple GPUs.
KV Cache memory management and Quantization: In autoregressive token generation, past Key/Values (KV) from the attention layers are cached; it's not necessary to recompute them at every step. The size of the KV cache can be significant depending on the number of sequences processed at a time and the length of these sequences. Moreover, during each iteration of the next token generation, new KV items are added to the existing cache making it bigger as new tokens are generated. Therefore, effective memory management that keeps the KV cache size small is critical for good inference performance.
Continuous Batching: Batching, i.e., processing multiple requests simultaneously, is essential for efficient utilization of GPU compute. However, requests from different clients do not arrive at the same time to form a batch. MosaicML Inference server supports adding requests to the server as they arrive and returning them as they get processed. This technique, known as continuous batching, optimizes GPU usage with minimal impact on request latency.
Streaming of Output Tokens: Output token streaming enables incremental rendering of output tokens to the end-user, as tokens are generated. While this is not a model performance feature per-se, this capability greatly enhances the user experience for chat and similar use cases and delivers enhanced interactivity when generating long output sequences. This feature is currently available with MosaicML Llama2-70B-Chat API; see the documentation for details.
Stay tuned for future blog posts as we explore other optimization techniques like quantization that improve performance (but may impact model quality).
Designing effective prompts for Llama2-70B-Chat
Llama2-70B-Chat, as the name implies, has undergone more training to make it excel at following instructions and having conversations. Like other versions of Llama2, this model has a 4,096 token maximum length, which corresponds to around 3,000 words. (Tokens are sometimes whole words, and sometimes fractions of a word. On average, a token is about ¾ of a word.)
If you'd like to check how many tokens a message has, you can use Llama2's tokenizer, which is available to experiment with through llama-tokenizer-js. You can spend those tokens how you like, so if you ask to summarize 4,095 tokens, it will only be able to respond with a single token. For optimal results, Llama2-70B-Chat does expect some structure, and that format will use some of your tokens. For example, if you want to know how to make a customer support bot to help answer questions based on product docs, you can use a prompt like this:
That's probably a lot more words than you expected.
In this prompt, there are two parts.
- User message: Your question or request. In this case: "How do I make a customer support bot using my product docs?"
- System prompt: A prompt shared across messages that tells the model what persona to take on in the conversation. It's everything between the <<SYS>> and <</SYS>> tokens. In this example, we used the system prompt that Meta suggests using with Llama2. However, it is far from the only system prompt you can use.
In chat conversations, there is usually a third part, the LLM response, which gets added in multi-turn conversations.
Llama-70B-Chat customization comes from being able to specify system prompts for specific use cases. For example, if you are using Llama2-70B-Chat to write code, you might want to use a system prompt like:
A company using Llama2-70B-Chat as a customer service chatbot would pass that information to the model in the system prompt, like:
Retrieval Augmented Generation Example
Let's look at a longer code sample with a realistic example.
Say you want to answer a domain-specific question based on a set of documents. A popular method to use is Retrieval Augmented Generation (RAG). With RAG, you first retrieve a set of relevant documents from a larger document store based on the user query, and then pass those along to the LLM as context to help it answer the query. This method allows the LLM to draw on knowledge it may not have seen before, and helps to reduce hallucination.
For this simple example we are not dynamically retrieving relevant documents, and are just providing a hardcoded set of relevant documents to the model. We make a request to the Llama-70B-Chat endpoint with the following in the input:
- A set of documents about MosaicML
- A user message: a domain specific question about our MPT models
- A system prompt asking to choose the most relevant document to answer the user query
Here's the answer Llama2 finds:
From here, you can try experimenting with additional system prompts, parameters, documents, and user messages for your custom applications.
Getting started with Llama2-70B-Chat on MosaicML Inference
To leverage Llama2-70B-chat with enterprise-grade reliability, security, and performance, sign up here and check out our inference product page. To stay up-to-date on updates and new releases, follow us on Twitter or join our Slack.
License
Llama 2 is licensed under the LLAMA 2 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved. Customers are responsible for ensuring compliance with applicable model licenses.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.